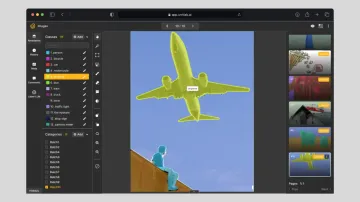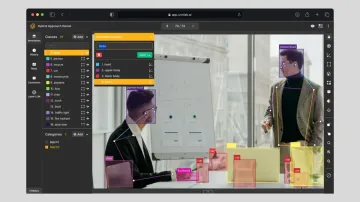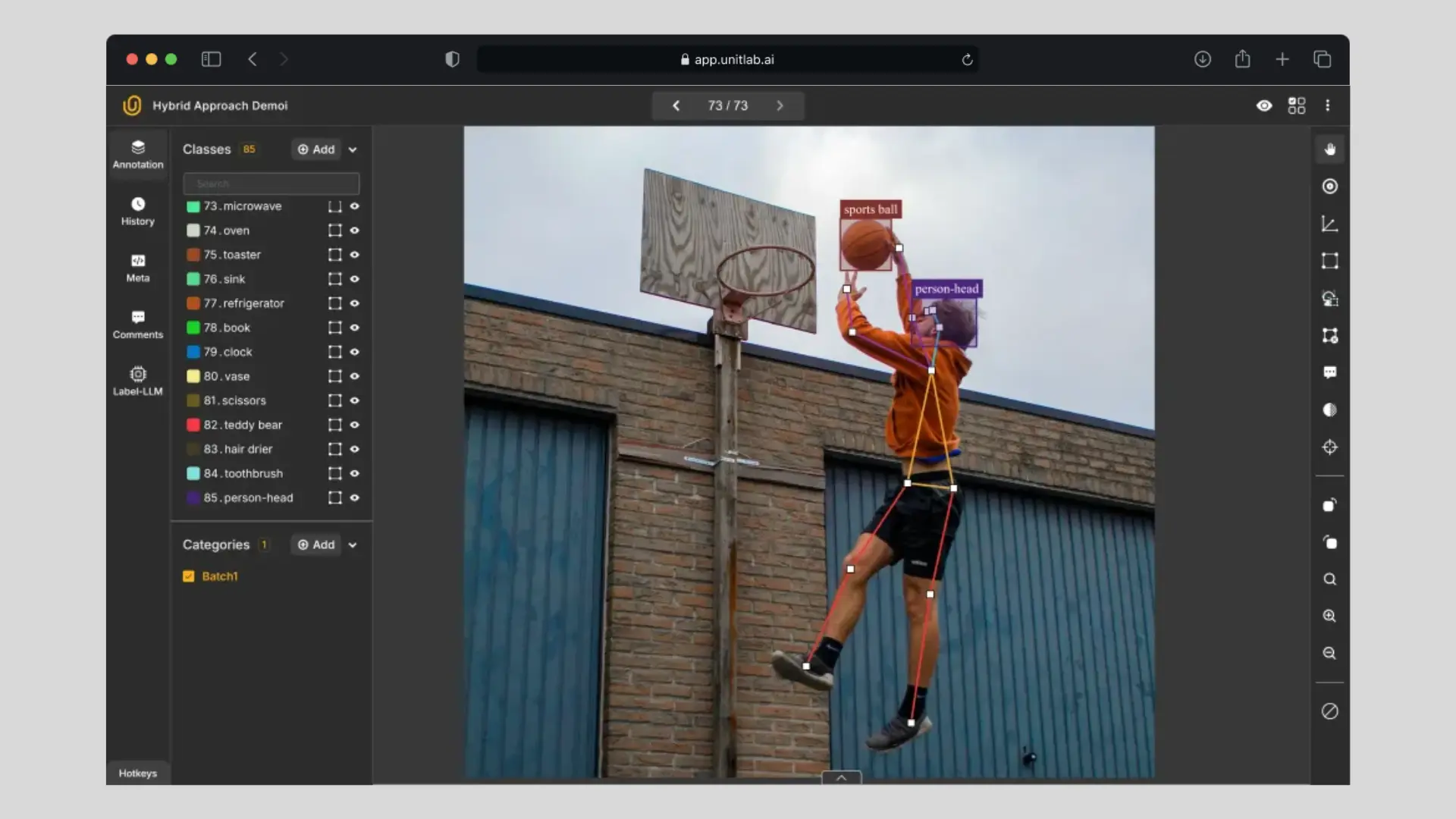
A fact of life: systems are vastly different at scale.
The process of preparing, labeling, and organizing datasets — data annotation — is no exception. As with any system, the larger it becomes, the more components it has, and the more complex its operations grow. In fact, in most AI/ML model development cycles, data preparation (data collection, cleaning, labeling, augmentation, etc.) consumes the majority of the time. No wonder The New York Times once referred to data scientists' work as “janitorial” in nature.
A common misconception is that scaling is linear — that complexity increases proportionally with input or components. This is decidedly not the case. Since each component also has to scale, the overall complexity often grows exponentially.
This post is a sequel to our earlier piece on data annotation at scale, where we explored the challenges of scaling in depth. Here, we briefly revisit those challenges before outlining five best practices for scaling data labeling in AI/ML model development.

Data Annotation at Scale | Unitlab Annotate
Challenges of Scaling Operations
Scaling data labeling operations introduces a combination of business, technical, and human challenges — particularly when managing large datasets or coordinating distributed teams across the globe. Based on insights from our earlier post, here are the most common issues teams face when moving from moderate to large-scale annotation:
1. High Volume
The challenge isn't merely having large volumes of data to label — it’s labeling that data effectively, accurately, and quickly, all within budget constraints. Handling large volumes puts considerable pressure on your entire system.
Take computer vision, for instance. Scaling from 1,000 labeled images to 100,000 across several datasets poses major technical hurdles. Every component in your pipeline must be able to support this increase.
2. Diminished Consistency
Consistent labeling is critical for AI/ML models to learn patterns and generalize well. This requires annotation guidelines that are clear and unambiguous, and annotators who adhere to them closely.
As annotation teams grow, maintaining consistency becomes more difficult. Different annotators may interpret the same guidelines differently, and without strong quality checks or a unified protocol, label drift sets in — directly affecting model performance.
There’s also a human limitation: annotators cannot maintain the same level of attention across tens of thousands of images. Hiring more annotators can help, but it increases both costs and training needs.

3. Communication Bottlenecks
This is a universal challenge for large organizations. Bigger teams lead to more back-and-forth between annotators, managers, and data scientists. Without clear communication channels and scalable feedback mechanisms, misunderstandings and delays become inevitable.
Without a streamlined communication pipeline, feedback loops slow down, and minor issues compound — negatively impacting dataset quality and project timelines.

4. Technical Infrastructure Strain
Most tools are not built for scale, simply because the average user doesn’t need that level of performance. Tools that work fine with 1,000 images may crash or become sluggish when processing 100,000, affecting your entire operation.
Other critical components — such as file storage, label versioning, and tool responsiveness — also become strained. No one can work efficiently with unstable or underperforming tools.
Without a robust infrastructure, annotation throughput suffers and iteration slows.
5. Cost Management
As your labeling operation scales, so does your overhead. More data, more annotators, more infrastructure — all require serious investment.
Without proper planning and efficient resource allocation, costs can escalate quickly — especially if poor-quality annotations lead to rework or repeated QA cycles.
Best Practices for Scaling
Despite the difficulties, scaling is achievable — and essential. Below are five actionable strategies that can help you scale labeling operations efficiently. These are informed by established best practices in the industry and our own experimentation with new technologies.
1. Standardize
In large, complex systems, ambiguity can be fatal. Clear and standardized processes reduce confusion and minimize variation.
Begin with well-defined annotation guidelines. Outline label classes, common edge cases (like shadows or occlusions), and clear instructions using simple language and visuals. Make documentation accessible and regularly updated. Everyone — from annotators to managers — should work from a single source of truth.
This guideline does not cut it, for instance:
Annotate every pedestrian and vehicle.
For starters, it does not specify which image annotation type to use. How should occluded objects be labeled? What about shadows, reflections, or partially visible objects?
This guideline, by comparison, is much better because it is specific and takes care of edge cases:
Annotate every pedestrian and vehicle using polygons. If an object is occluded, label it as if it were fully visible. Assign new classes called “Shadow” and “Reflection” for shadows and reflections.
Use templates, checklists, and validation tools to reduce subjectivity. Continuously refine your documentation based on user feedback and model performance.
Standardization ensures everyone understands the process and operates on common ground.

Standardized Guidelines | Unitlab Annotate
2. Assemble & Improve the Team
Large-scale annotation projects require well-structured teams. Whether or not you outsource your annotation work depends on your priorities. Outsourcing can be cost-efficient but comes with quality and coordination challenges. In-house teams often offer higher consistency, though at greater cost.
Build a team with a well-balanced mix of annotators, reviewers, and QA leads. A typical review process might involve three layers of checks: annotation, peer review, and random QA sampling.
You may also want to segment the team by expertise — general annotators, domain experts (e.g., radiologists, linguists), and reviewers. Tight feedback loops between these roles help identify and fix systemic issues early.
Regardless of team structure, invest in proper onboarding and continuous training. Labeling needs change as your models evolve.
Automation is arguably the biggest lever for scaling. But it’s only effective when paired with clear processes and a skilled team.
Use AI-assisted labeling to pre-label data and allow human reviewers to correct them. This approach is significantly faster than manual labeling from scratch. Depending on your tools and use case, consider:
Batch Auto-annotation | Unitlab Annotate
- Batch Auto-annotation: Apply consistent labeling across large datasets using pre-trained models or templates.
Crop Auto-annotation | Unitlab Annotate
- Crop Auto-annotation: Automatically identify and label object instances in images.
SAM-powered Medical Labeling | Unitlab Annotate
- SAM Annotation: Leverage Meta’s Segment Anything Model for pixel-precise labels with minimal human input.
Beyond AI labeling, use CLI tools, SDKs, and APIs to automate workflow components. Every step you can automate reduces the risk of human error and increases scalability.
4. Iterate with a Human-in-the-Loop
Don’t expect to get everything right the first time — especially at scale.
Build workflows that allow for iterative improvements: relabeling, refining, and retraining. A human-in-the-loop (HITL) approach offers a powerful feedback mechanism by combining automation with expert review.
HITL makes it easier to spot and fix errors, evolve labeling guidelines, and ensure model predictions improve based on real-world feedback.
5. Adapt & Improvise
Your labeling workflows must evolve with your models and business goals. What worked yesterday may not work tomorrow.
You might need to switch from bounding boxes to polygons, or move from 2D to 3D data. Be prepared to retrain your team, update your tools, or change workflows as your requirements shift.
Adaptability is not optional — it’s vital for long-term sustainability.
This also means adjusting QA cycles, tooling stacks, and annotation priorities to match new demands and growth levels.
Key Takeaways
A quick summary of the best practices:
- Scaling data labeling is non-linear — what works for 1,000 samples won’t scale to 100,000.
- Success depends on standardization, automation, and iteration — not just more people or money.
- Investing in both people and tooling is essential to maintain quality.
- A human-in-the-loop workflow helps balance speed and precision, especially in critical domains.
Conclusion
As data volumes grow and projects become more complex, scalable annotation systems are no longer optional — they’re foundational. But true scalability isn’t just about increasing output; it’s about maintaining quality, speed, and flexibility under pressure.
By designing clear processes, investing in the right teams and tools, and building systems that adapt and iterate, you can create a sustainable pipeline for labeling data at any scale.
Whether you're just starting out or trying to overcome a bottleneck, the principles outlined here will help you take the next step with confidence.
Explore More
For more resources on scaling data annotation workflows, check out:
References
- Hojiakbar Barotov (Apr 30, 2025). Data Annotation at Scale. Unitlab Blog: Link
- Nikolaj Buhl (Jul 4, 2023). How to Scale Data Labeling Operations. Encord Blog: Link