![Writing Clear Guidelines for Data Annotation Projects [2025]](/content/images/size/w2000/2025/11/imain-3.png)
First of all, let's review some generally accepted principles of computer vision model development:
- Image annotation is the foundational step in preparing AI/ML datasets fpr computer vision models.
- The quality of the training data determines the quality of the AI: “garbage in, garbage out.”
- Clear labeling guidelines ensure consistent labeling, thus consistend image sets.
We covered the first two principles extensively in our earlier posts - the first and the second principle.
Consistency in your source labeled images is crucial because AI/ML models learn patterns. If these patterns are inconsistent, or your dataset is so poor that no obvious patterns emerge, you end up with what we humorously call “garbage AI.”
Hence the need for data labeling platforms with clear guidelines. In fact, the entire data annotation process must be carefully planned.

In this post, we will cover guidelines to annotate images more consistently and accurately with examples.
By the end of this post, you will learn:
- why bother about clear guidelines
- what makes guidelines clear
- common pitfalls to avoid
Why need guidelines?
Everyone agrees we need high-quality, consistent, and accurate image sets to train and improve our computer vision models, but not many have concrete ideas how to do it efficiently.
Accurate photo annotation does not happen by itself; it requires human annotators to follow precise, clear guidelines. Even if you have cutting-edge auto-annotation models or an expert data labeling team, you won’t maintain annotation consistency for long without guidelines, the single, central source of truth.
Inconsistent AI image sets likely result in weird, sometimes amusing CV models.
How do you ensure consistent quality in your dataset? What are common pitfalls to avoid in building image sets for CV models? How does your team know how effective they are? It's demoralizing to have your work judged by inconsistent standards in any field.
Therefore, although overlooked, image annotation guidelines are essential for the CV development pipeline. A clear, consistent guideline can be the differentiating factor between a well-annotated, high-quality dataset and a poorly annotated, inconsistent, nearly useless one.
What Makes a Guideline Clear?
Obviously, the exact checklist does not exist. Specific details depend on your project, but these principles can help you formulate robust, adaptable guidelines for yourself:
1. Give Detailed Instructions
An ideal guideline should specify exactly what to label, how to label, and any exceptions to the rules. Imagine you’re building a street-level detection system for pedestrians and vehicles. Telling your team:
Annotate every pedestrian and vehicle.
…is too vague. For starters, it does not specify which image annotation type to use. How should occluded objects be labeled? What about shadows, reflections, or partially visible objects? What if there are too many in a single image?
Such micro-decisions, repeated countless times, drain the team’s energy and morale. A much better approach would be:
Annotate every pedestrian and vehicle with polygons. If an object is occluded, label it as if it were fully visible. Assign new classes called “Shadow” and “Reflection” for shadows and reflections.
2. Make Language Clear
No matter how detailed and technical your guidelines are, they must be straightforward, unambiguous, and free of complicated technical jargon that not everyone understands. Your team most likely includes people with varying levels of language proficiency, so it is best to go for middle-school level complexity.
Let's look at this example:
All pedestrians and vehicles must be annotated with detailed polygon masks that reconstruct their complete silhouette, even where occluded, by inferring hidden geometry from contextual cues. In addition, shadows and reflections must be treated as distinct semantic entities, each assigned to the “Shadow” and “Reflection” classes, with explicit linkage to their generating objects.
Quite difficult to read and understand, right? It is actually a paraphrase of the guideline above.
At the other end of the spectrum, stay away from vague wording, like “stuff” or “things” that do not specify anything meaningful. This leaves a huge interpretation gap that decreases labeling consistency.
Just mark people and cars kind of loosely with shapes, even if you can’t see the whole thing. Also, maybe add something for shadows and reflections if they look important.
I think you can see this is also a paraphrase. Way too much ambiguity?
Finally, avoid using technical jargons too much. A few technical concepts related to photo annotation are fine, but abbreviations and made-up jargons make the process ambigious and unclear for everyone involved. This was apparently a huge problem in SpaceX back in 2010, written in Elon Musk's biography by Ashlee Vance:
Excessive use of made up acronyms is a significant impediment to
communication and keeping communication good as we grow is incredibly
important. Individually, a few acronyms here and there may not seem so
bad, but if a thousand people are making these up, over time the result will be a huge glossary that we have to issue to new employees. No one can actually remember all these acronyms and people don’t want to seem dumb in a meeting, so they just sit there in ignorance. This is particularly tough on new employees.
—From email by Elon Musk
3. Use Visual Examples
Sometimes, as cliché as it gets, a picture is worth a thousand words. Combined with exact details and a clear language, a visual example is a great addition for human data annotators.
Whenever possible, use visual examples (images or videos) to show what ideal annotations look like. Visualization is often the quickest, clearest way for everyone to align on the guidelines.
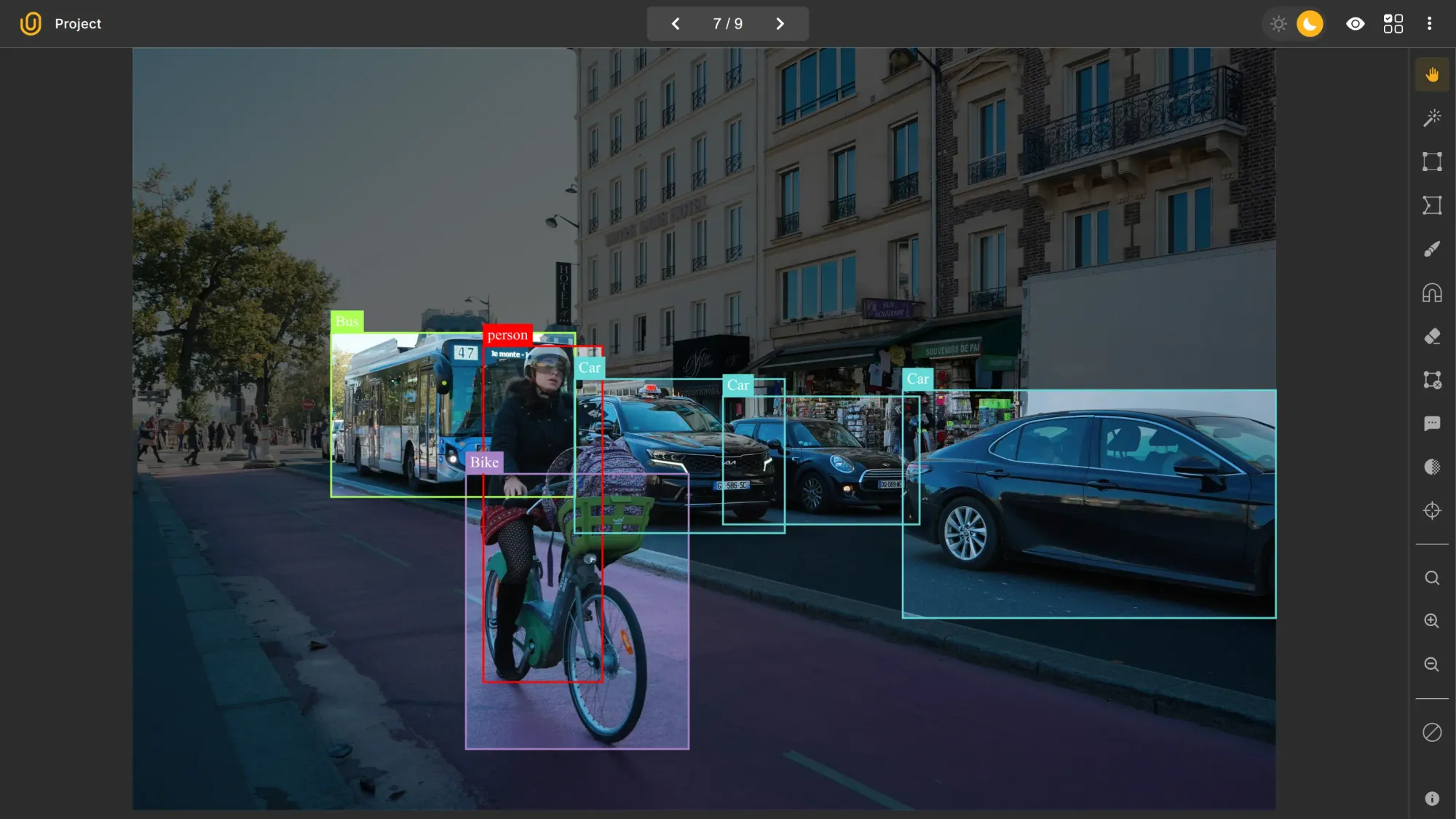
For example, you can show the image above as an example that meets the requirements for the guideline above. Every vehicle, including occluded ones, is fully labeled and given appropriate class names (bus, car, bike). You can attach it to the requirement so that everyone "gets it" easily.
4. Handle Edge Cases Once
Every photo labeling pipeline has edge cases you can anticipate; and others you can’t. If you can predict some, address them from the start and stick to one method throught the project.
For instance, in our case passengers inside buses and cabs might be visible in the image. These passangers, to label them or not? Should we create a separate class or annotate them as usual? The exact answer depends, but whatever you choose, stick to your way throughout to maintain consistency.
Similarly, in future unexpected scenarios, you can work out the optimal path for your case. The key is to stick to your solution, not deviate them in the middle of the project.
This ensures that exceptions are handled consistently with care and logic, not haphazard, independent action.
5. Update Guidelines Regularly
Edge cases, requirements, project scopes, and techniques naturally evolve over time. So should your guidelines.
Keep them updated to reflect the latest standards in your workflow. Ensure that data labelers remain aligned with the new guidelines. Consistency and accuracy in your AI datasets happen as a result
This is a small preventative step that many tend to forget. But remember, an ounce of preventation is worth a pound of cure.
Avoiding Common Pitfalls in Guidelines
To complete the discussion, let's now talk about what not to do. Avoiding these pitfalls is just as crucial as following best practices:
1. Avoid Vague Instructions
We touched on this point above, but it's so important that it deserves repeating. If you get anything from this post, this will be it: make your guidelines clear.
Unclear ones result in major deviations in photo labeling, decreasing consistency and accuracy in your final ML dataset. Statements like “label all objects and stuff” are wide open to interpretation by your data labeling team. Instead, take the time to specify precisely which and how objects of interest should be labeled. This action will pay dividends in the form of high-quality image sets.
In a nutshell, clarity is the unsung hero of consistent data annotation.
2. Do Not Overwhelm Team
On the other hand, you do not need to write a full-blown specs for your data labeling team. Human labelers are more valuable than auto-labeling models precisely because they can step back, see the full picture, and make informed decisions. Too much micromanagement kills morale of any team. Too many details are good for training AI models, not for humans.
Consider this detailed, unambigious guideline:
Annotate all pedestrians and vehicles with polygons that cover their full shape, even when partly hidden. Use at least 8 points and add more around curves like wheels or arms. For hidden parts, complete the shape using symmetry or common body proportions. Label shadows as Shadow and reflections as Reflection, tracing them on glass, water, or shiny surfaces, and link each back to its original object.
The problem lies in its too detailed nature. This likely overwhelms humans.
The point is to make clear, general guidelines that your annotation team can rely on. The goal is to find the Goldilocks zone.
3. Provide Context for Annotators
Not all domains are created equal. You cannot just expect someone to label medical images accurately without providing training and context. Data annotators need enough background context to understand the requirements and to fulfill them.
It is too easy to assume that your team understands the task, and that this background training is just another hassle. You have thousands of data points to label with a deadline and tight budget.
This might seem like a trade-off, but it isn't. You might risk a poorly-labeled, inconsistent dataset without this training, especially when your domain is a specialized one, like medicine or law.
Conclusion
We need high-quality, accurate, consistent image sets to train our computer vision models effectively. Achieving this level of effectiveness depends on consistent photo annotation, and that, in turn on clear labeling guidelines.
This task seems like an unimportant hassle, but it is a deposit you invest in at the beginning of your labeling pipeline that pays many dividends down the road in saved time and efforts.
Today, we discussed what to focus on when writing these guidelines and which pitfalls to avoid. Detailed and visually illustrated instructions that are context-aware help you maintain a high standard of image labeling.
Essentially, invest in the clear, unambiguous photo labeling guidelines to achieve and maintain consistent datasets.
Explore More
Check out these posts for more on achieving consistent, accurate data labeling: