
![Multimodal AI in Robotics [+ Examples]](/content/images/size/w2000/2026/01/Robotics--12-.png)
TL;DR (Below is a quick summary of multimodal AI in robotics)
- What is multimodal AI in robotics and how does it differ from traditional unimodal systems?
Multimodal AI in robotics refers to artificial intelligence systems that integrate and process multiple data types, such as visual data, audio inputs, sensor data (LiDAR, radar), and haptic feedback in parallel to create a unified understanding of the environment. Unimodal systems rely on a single source of information (only computer vision), multimodal AI systems use sensor fusion to resolve ambiguities by combining visual cues with ultrasonic or force-torque data. This approach mimics human perception for autonomous robots to operate in dynamic environments where single sensors might fail due to occlusion, noise, or lighting conditions.
- How do multimodal AI models enhance the operational efficiency and safety of autonomous systems in dangerous tasks?
Multimodal AI models improve operational efficiency and safety by providing contextual awareness and redundancy. In dangerous tasks like search-and-rescue or industrial welding, robots equipped with multimodal perception (infrared imaging combined with 3D depth sensing) can detect hazards invisible to the naked eye, such as gas leaks or structural instabilities. Autonomous systems can cross-validate data by using multimodal AI (audio processing to hear machinery faults while visual cues monitor for smoke).
- What role does sensor fusion play in enabling natural human-robot interaction and improved patient outcomes in healthcare?
Sensor fusion is the backbone of natural human-robot interaction, particularly in healthcare settings where social and assistive HRI is critical. Medical robots can engage in empathetic and effective care by fusing speech recognition (to understand patient requests) with facial expression analysis (to gauge pain or emotion) and visual perception (to recognize gestures). For instance, surgical robots combine haptic feedback with high-definition medical images to provide surgeons with a richer understanding of tissue texture and depth, directly leading to improved patient outcomes and higher diagnostic accuracy. This comprehensive understanding lets robots interpret unstructured human behaviors that unimodal systems would miss.
- How are generative AI and large language models (LLMs) being integrated into multimodal AI robotic systems?
The integration of generative AI and large language models (LLMs) transforms robots from rigid automatons into embodied agents. Models like Google DeepMind's Gemini Robotics and PaLM-E are Vision-Language-Action (VLA) models that take text data and visual inputs to generate robotic control actions. These multimodal Gen AI systems allow users to issue high-level voice commands that the robot interprets by combining semantic understanding with spatial reasoning. This enables autonomous robots to perform complex tasks and generalize to new objects and environments without explicit retraining.
Introduction
Robots can sense environments and human cues much like people do. They combine sight, sound, touch, and language to work safely in messy environments.
Instead of relying on a single sensor, multimodal AI lets autonomous robots and AI-powered cobots be far more adaptable, reliable, and context-aware in complex settings.
In this article, we will walk you through how robots use multimodal AI to fuse multiple data types to understand context before acting.
Here’s what we will cover:
- What is multimodal AI in a robotics context?
- Core capabilities robots can gain from using multimodal AI.
- Key modalities and sensor stack in modern robots.
- Industrial and warehouse robotics.
- Service, healthcare, and assistive robotics.
- Multimodal models for embodied agents.
- Challenges of multimodal AI in robotics and strategies for overcoming them.
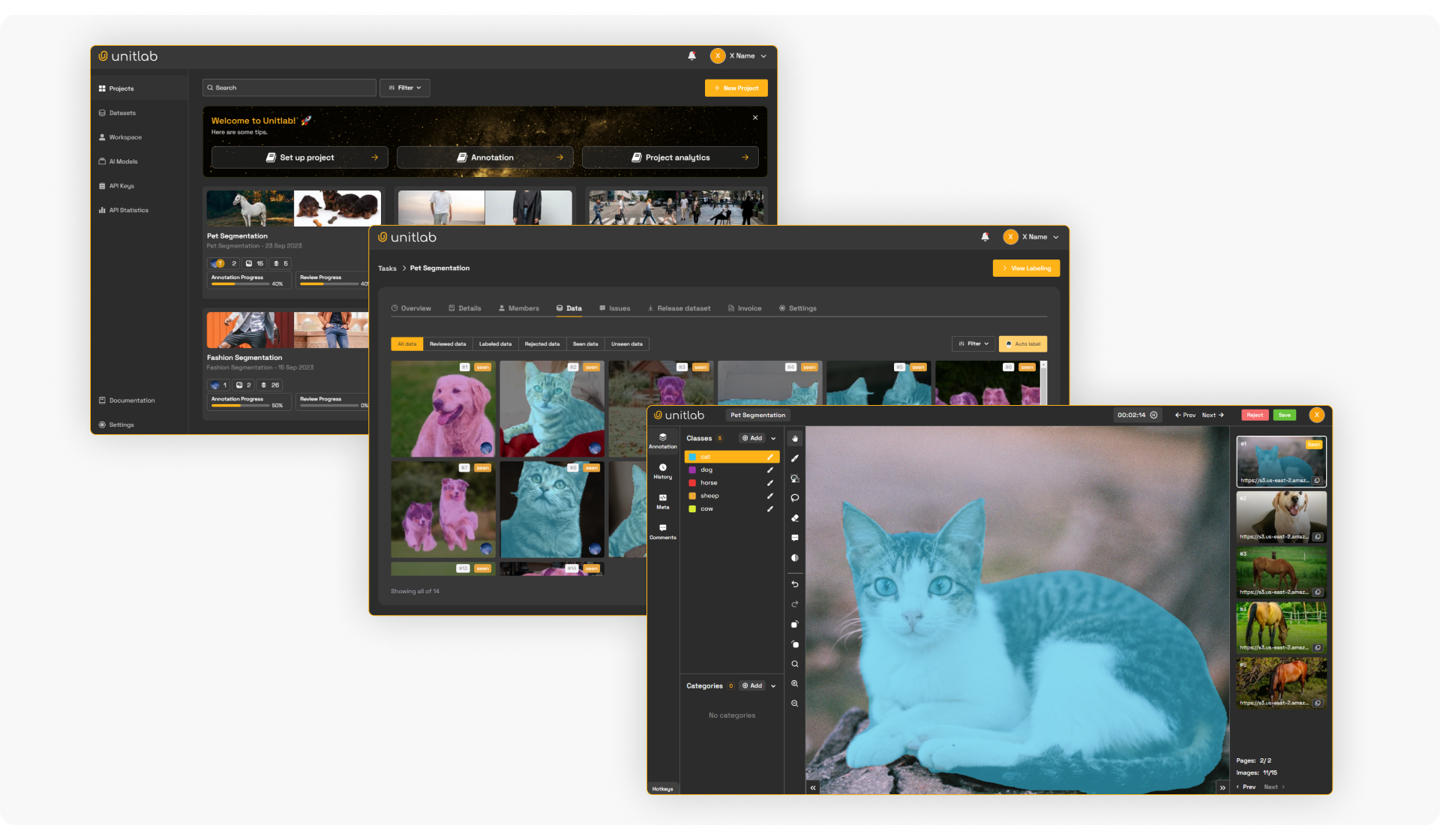
Training and scaling AI models depend on the quality of your annotated data across images, text, audio, and video. Unitlab AI helps you speed up data preparation with AI-assisted labeling workflows (and is expanding its capabilities to support multimodal data annotation).
Try Unitlab AI for free to set up a production-ready labeling + review workflow to reduce rework from noisy labels, and ship AI models faster.
What Is Multimodal AI in a Robotics Context?
Multimodal AI in robotics refers to artificial intelligence (AI) systems that process and combine multiple data types from cameras, microphones, force sensors, and language to inform an agent's perception and control policies.
For example, a multimodal robot might use computer vision (camera images) to recognize objects, a microphone (audio) to catch voice commands, and touch or force sensors to feel an object’s weight. That diverse inputs are aligned (sensor fusion), so the robot has a single understanding of its surroundings.
Simply put, multimodal AI lets robotic systems be environment-aware, reacting based on a combination of sight, sound, and more rather than any single cue.
Capabilities Robots Can Gain From Using Multimodal AI
Integrating multimodal AI confers four key capabilities that set intelligent robots apart from older robots.
Adaptive Perception
Adaptive perception helps robots work reliably in dynamic environments where conditions can quickly shift.
A robot relying only on visual data will struggle in a warehouse with variable lighting (sun glare through skylights).
But a robot using multimodal inputs, combining vision with infrared imaging or LiDAR, can adjust better.
- Scenario: A factory robot drives into a dark space. As the camera adjusts to the darkness (visual degradation), the system automatically up-weights the radar and LiDAR data to maintain precise positional data and obstacle detection.
- Mechanism: The system constantly monitors the confidence levels of each sensor stream. When one modality becomes noisy, the data fusion algorithm shifts reliance to the unaffected sensors to ensure continuous, safe operation.
Context-Aware Decision-Making
Multimodal AI enables robots to interpret the intent and state of their environment and adjust actions in real time.
- Scenario: A robot arm on an assembly line needs to pick up a fragile component from a bin. It first uses vision to locate and target the object. As the gripper closes, the robot then confirms contact with force sensors and detects how firmly it is holding the part and whether anything slips or collides.
- Mechanism: The system fuses visual data with tactile and force feedback (contact, pressure, micro-slippage) to reason about the quality of the grasp and the safety of the motion. It lets the robot adjust its grip strength, speed, and trajectory like tightening slightly on a heavier object or loosening for something fragile.
Natural Human-Robot Interaction (HRI)
Natural human-robot interaction is critical for collaborative robots (cobots) and social robots. People communicate multimodally as we speak, point, gaze, and express emotion simultaneously.
- Scenario: A user points at a tool and says, Hand me that. A robot with only speech recognition fails because that is ambiguous. A robot with multimodal perception combines the audio input (Hand me that) with visual perception (detecting the user's hand and calculating the vector of the pointing gesture) to identify the specific tool.
- Mechanism: The AI aligns the timestamp of the spoken word that with the visual frame where the pointing gesture reaches its apex and resolves the deictic reference. It also analyzes facial expressions to confirm that the user is satisfied with the action.
Generalization and Flexibility
Generalization is a robot's ability to perform tasks it has never been explicitly trained for. Embodied generalist models trained on multimodal datasets can transfer knowledge to new domains.
- Scenario: A robot is asked to recycle the plastic bottle. It has never seen this specific brand of bottle. But its multimodal foundation model recognizes the object's transparency and shape (vision) and label (text reading) as plastic, and knows from general knowledge that plastic goes in the blue bin.
- Mechanism: Vision-Language-Action (VLA) models help robots understand high-level commands and translate them into specific actions. They use general knowledge to learn how to handle new objects and let robots work effectively in everyday environments such as homes and offices.

Key Modalities and Sensor Stack in Modern Robots
Modern robots use multiple sensors to capture different modalities of data. Common sensors include:
- Vision (Cameras): Cameras are crucial for robotic perception. There are different types of cameras, including RGB cameras that take color pictures, depth cameras that measure how far away things are, and infrared or thermal cameras that detect heat. These cameras help robots recognize objects, navigate spaces, and analyze scenes. For instance, factory robots use cameras for object detection and check the quality of products.
- LIDAR and Radar: LIDAR and Radar use light or radio waves to create a 3D map of the environment. LIDAR (Light Detection and Ranging) is common on autonomous vehicles and mobile robots. It provides accurate distance-to-obstacle measurements of nearby objects and creates detailed maps of the area around them. Radar (radio waves) also maps obstacles and works well in bad weather. Robots in warehouses and transportation heavily use LIDAR/radar to localize and plan safe routes.
- Inertial Sensors (IMU) and Odometry: IMUs measure acceleration (how fast something is speeding up) and rotation, while joint encoders track motion. When used together, they help the robot know where it is and how it's moving.
- Tactile and Force Sensors: Tactile and force sensors are located in grippers or feet to measure contact forces and pressure. Tactile sensors can sense texture and detect when something is slipping, while force sensors can detect how much force is being applied.
- Audio (Microphones) and Speech: Microphones let robots hear sounds. They can recognize spoken commands and pick up alarms or announcements. In service robots, speech recognition technology turns spoken words into actions. Microphones also listen to other sounds in the environment, like machinery or footsteps, to understand the situation better.
- Other Sensors: Robots can also have different types of sensors based on their use. For example, they might use GPS to find their location outdoors, ultrasonic or infrared sensors to detect obstacles, barometers to measure altitude, or chemical sensors to detect dangerous gases. Some specialized robots, like those used in medical imaging, even use LiDAR or ultrasound as needed.
Industrial and Warehouse Robotics
Multimodal AI greatly improves efficiency and flexibility in warehouses, logistics centers, and other settings.
Multimodal AI robots on assembly lines use vision and force sensors to build products. For instance, an automotive robot can use cameras to locate a car door and force-torque sensors to fit it exactly on the frame.
Multimodal AI-powered robots can also inspect products. A vision systemcan detects defects, while microphones or vibration sensors might catch subtle manufacturing errors (a misaligned panel that makes noise).
Modern warehouses use fleets of autonomous mobile robots (AMRs) and drones for sorting, picking, and transport. These robots merge different modalities to navigate busy aisles.
For example, Amazon’s fulfillment centers employ thousands of autonomous carts that combine cameras, LIDAR, and radar to map the floor and avoid obstacles.
Furthermore, multimodal AI robots can read barcodes to identify racks and use LIDAR scanning for accurate localization. These multimodal stacks often include floor magnets or QR codes, too, and ensure packages reach the right spot.
Service, Healthcare, and Assistive Robotics
Multimodal AI is also greatly benefiting service and healthcare robots by enabling them to interact with people and adapt to complex human environments. In hospitals and homes, multimodal AI robots often use speech, vision, and even touch to engage in useful ways.
In eldercare, multimodal AI robots use a camera and a microphone to monitor an elderly person’s well-being. They can spot if someone falls (via vision) and also respond to verbal commands.
In customer service (hotels, shops), robots use vision to navigate and recognize people, while speech AI handles queries.
For instance, a concierge robot sees a guest approach (detecting body language) and greets them by name (recognizing their face), then answers spoken questions about the hotel facilities.
Multimodal Models for Embodied Agents
Many multimodal AI models are built to embed them in robots that plan and act in the physical world. Multimodal AI models for embodied agents include:
Gemini Robotics 1.5 (Google DeepMind)
Gemini Robotics 1.5 is a vision-language-action (VLA) model that turns camera inputs and text instructions into motor commands. Gemini 1.5 can think before taking action and generate internal plans in natural language to guide the robot. It even exposes its reasoning steps for transparency and enables the robot to solve complex, multi-step tasks.

Gemini Robotics-ER 1.5 (DeepMind)
Gemini Robotics-ER 1.5 reasons about a task and calls digital tools. It creates detailed multi-step plans (robotic blueprints) for missions, using state-of-the-art spatial reasoning.
For example, Gemini-ER 1.5 can plan how to sort objects into recycling bins by looking up local guidelines online and then instructing the robot step by step.
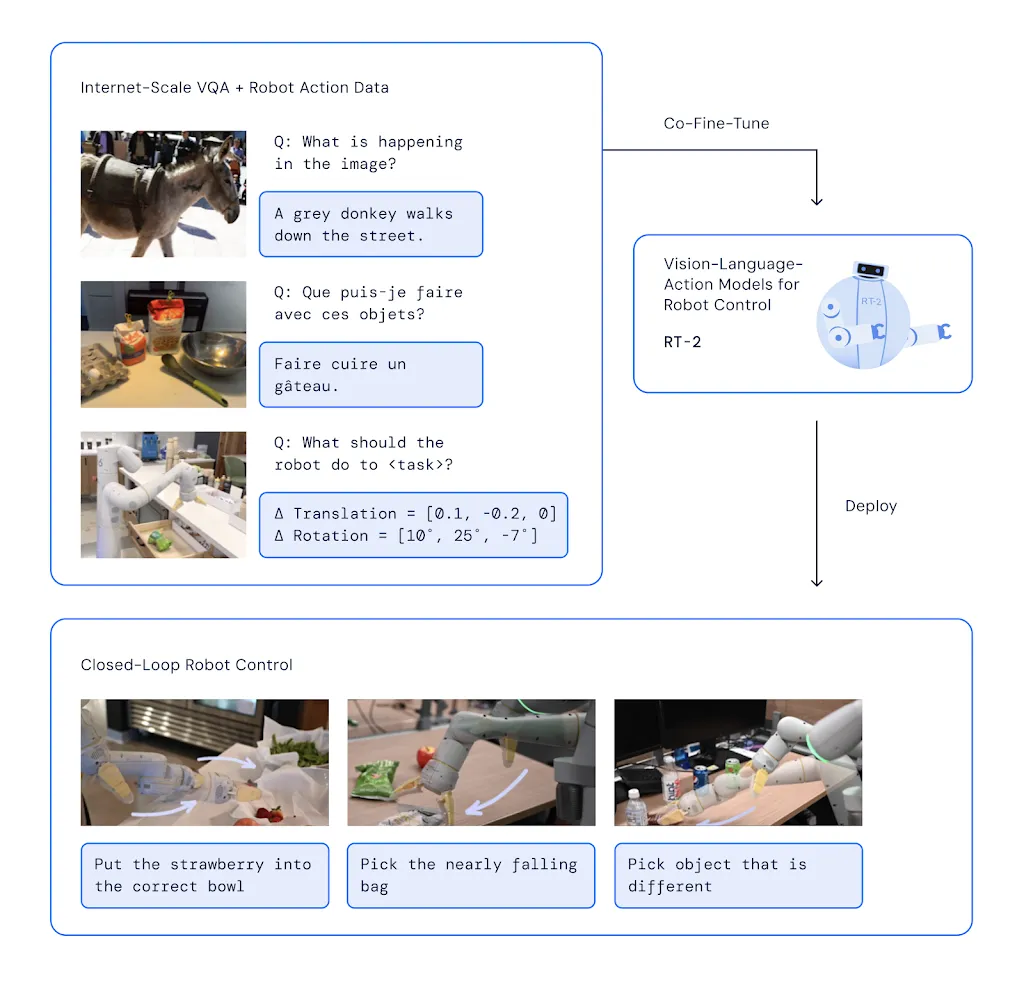
RT-2 (Robotic Transformer 2, DeepMind)
RT-2 model trained on both web-scale vision-language data and real robot demonstration data. It learns common-sense knowledge from the Internet (via a pre-trained vision-language model) and fine-tunes on actual robot tasks.
The result is a robot controller that can interpret new commands and generalize. It even uses a form of chain-of-thought reasoning so it can plan multiple steps ahead.
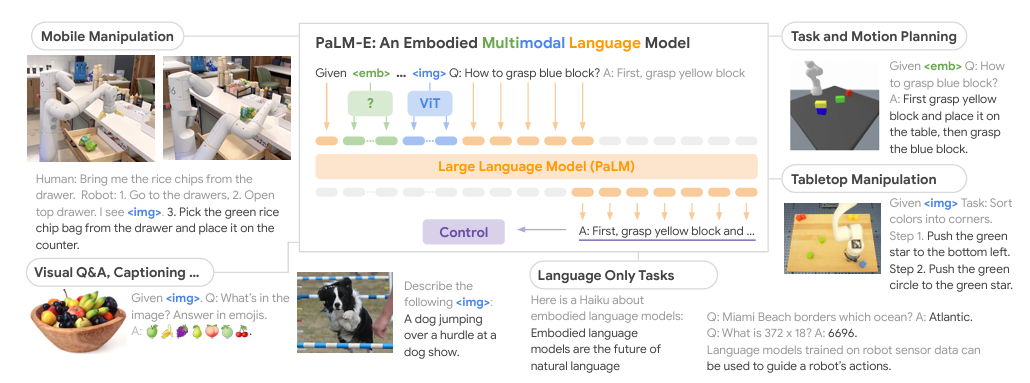
PaLM-E (Google, 2023)
PaLM-E is a large embodied multimodal model. It starts with PaLM (a massive language model) and feeds it raw sensor streams from robots (images, states).
PaLM-E ingests images and sensor data as if they were word embeddings and unifies vision and language. It can answer questions about what a robot sees or plan actions in the physical world.
Challenges of Multimodal AI in Robotics and Strategies for Overcoming Them
Developing multimodal AI systems comes with technical hurdles. Below are the key challenges and how to address them.
- Data Collection and Annotation Complexity: Labeling AI datasets (images, video, audio, sensor logs) is labor-intensive and prone to error. Manual annotation of every frame or sensor reading is impractical.
- Solution: Use an AI-assisted labeling platform like Unitlab AI to speed up data annotation with auto-labeling features and quality checks. It supports various annotation types and is extending support to multimodal data. Unitlab AI reduces manual effort by up to 10x while ensuring high precision across modalities.
- Sensor Fusion Synchronization: Sensors operate at different frequencies (Cameras at 30Hz, LiDAR at 10Hz). Integrating these data streams requires precise temporal and spatial calibration. A mismatch of a few milliseconds can cause a robot to misjudge the position of a moving object, leading to collisions.
- Solution: Robust middleware like ROS 2 and hardware-level timestamping are essential. They can help visualize synchronized streams and let engineers verify calibration and alignment during the data curation phase so that the training data reflects reality accurately.
- Multimodal Security and Data Privacy: Multimodal robots collect sensitive data, video of private homes, audio of confidential factory conversations, and maps of secure facilities. Processing this data in the public cloud creates a massive attack surface and compliance risk (GDPR, HIPAA).
- Solution: Unitlab AI offers a secure deployment option (on-premises). You can use it to manage your data annotation within your own secure infrastructure. It ensures that sensitive input data never leaves the facility and solves the security challenge while enabling the development of advanced AI.
- Dataset Management at Scale: Robotics projects generate petabytes of data. Managing multimodal datasets like tracking which version of the LiDAR data corresponds to which camera calibration, and which data was used to train a specific model version, is difficult without proper tooling.
- Solution: Unitlab AI supports dataset management to provide version control for datasets (data management for multimodal data available soon). Teams can track lineage, manage distinct releases, and query data based on metadata to ensure reproducibility and organized development.
- Limited or Biased Data: It’s hard to collect balanced data for every environment or edge case. Robots trained only on daytime factory scenes may fail at night or in a different factory.
- Solution: Augment data and simulate. Use synthetic data (simulators) and domain randomization to expose models to varied conditions. Actively gather data in rare situations. Transfer learning (pretraining on large vision and language corpora) can also help models generalize.
- Real-Time Processing Latency: Running heavy multimodal models requires more compute that introduces latency incompatible with real-time control.
- Solution: Edge computing and model optimization (quantization, distillation) can help deploy these heavy models on robot hardware.
Multimodal AI in Robotics: Conclusion
Multimodal AI helps develop the next generation of robots for various fields. These include industrial robots that can quickly adapt to new assembly tasks and healthcare robots that offer compassionate care.
But implementing multimodal AI models for robotics systems does come with challenges, which can be addressed with advanced data labeling and management tools. As research into more general AI for robots advances, future robotic systems are expected to become more flexible.
The ultimate goal is to create versatile robots capable of handling complex tasks in factories, cities, or homes by using all types of sensory information.

