Over the past few months, we have written extensively on computer vision and data annotation in our blog, covering both theoretical foundations and practical applications. In essence, computer vision is the process by which we enable machines and computers to interpret visual data in a manner similar to human perception.
However, computers do not spontaneously learn to recognize or understand images. Instead, mathematics, statistical methods, algorithms, and computing power are all required to help computers analyze, classify, and detect images and video frames, such as this one:
Fashion Semantic Segmentation with Pixels | Unitlab Annotate
Computer vision comprises multiple components and processes. It is a rapidly developing field, currently experiencing an AI boom with tremendous potential. As emphasized in previous discussions, successful computer vision initiatives require considerable time, resources, robust data labeling tools, and human involvement. One of the most fundamental yet highly subjective aspects of developing computer vision models is data annotation.
Why is data annotation so critical? Because the other phases of model development are comparatively stabilized and standardized throughout the broader community. Model building, testing, and deployment largely follow established best practices. In contrast, the data annotation phase still consumes substantial time, energy, and manpower.
Since our models are only as effective as the data used to train them, ensuring data annotation is done correctly is essential. As we will illustrate, data annotation involves numerous considerations and moving parts. In fact, many startups have been founded in recent years specifically to address the challenges of data labeling and data annotation service.

Below, we focus on the essential aspects of data annotation by addressing four key questions. By the end of this post, you should be able to answer these questions independently:
- What is Data Annotation?
- What are the Types of Data Annotation?
- Why Care About Data Annotation?
- What are the Challenges in Data Annotation?
What is Data Annotation?
Data annotation, sometimes called data labeling, involves labeling or tagging various types of data, such as images, videos, text, or audio, for machine learning algorithms. In this process, metadata is added so that machine learning models can learn to identify and understand patterns over time as they ingest more annotated samples.
For a simple image annotation scenario with bounding boxes, consider this image:

Through specialized software or platforms, relevant metadata would be generated, enabling machines to interpret and process the data:
{
'class': 'Person',
'coordinates': {
'x': 10,
'y': 10,
'width': 150,
'length': 300
},
'confidence_score': 0.93,
}
The precise steps involved in data annotation differ depending on the type of data. In this post, for clarity, we focus on image labeling. Here, objects of interest within an image are identified and labeled so our AI/ML models can understand and detect them effectively.
What are the Types of Data Annotation?
Because we operate in a complex, ever-changing environment, data annotation itself varies widely according to real-world AI needs. The main types include:
- Image Annotation: Labeling objects in images using bounding boxes, polygons, pixels, or keypoints. This is the most common type of annotation for training computer vision models. Typically, a large dataset is compiled, then annotated by human labelers, auto labeling tools, or a hybrid approach.
- Text Annotation: Adding metadata to text for NLP (natural language processing), including named entity recognition and sentiment analysis. This approach is frequently used to train chatbots and various text-based AI systems.
- Audio Annotation: Labeling speech segments, transcriptions, and background noise. Modern audio processing tools leverage AI to reduce noise, enhance quality, and generate transcripts. These systems must be trained on large sets of labeled audio files.
- Video Annotation: Detecting and tracking objects moving across frames in a video. Closely related to image labeling, video annotation is vital for computer vision models that analyze real-time video data. For example, speed cameras identify cars, determine whether any traffic regulations are violated, and make decisions within milliseconds.
Each annotation type plays a significant role in constructing AI/ML models tailored to specific tasks and industries.
Why Care About Data Annotation?
You may be familiar with the computer science maxim:: garbage in, garbage out. It states that
Flawed, biased or poor quality ("garbage") information or input produces a result or output of similar ("garbage") quality. The adage points to the need to improve data quality in, for example, programming.
Wikipedia

This concept also applies to AI/ML models, whose performance is heavily dependent on the quality of their training data—particularly on how the data is collected and annotated (i.e., the dataset). Mistakes in dataset preparation (both in collection and annotation) are common, and we have previously discussed the most frequent errors in image annotation:
8 Common Mistakes in Preparing Datasets for Computer Vision Models
We emphasize data annotation because it forms the foundation of any model’s performance. Consider building an object detection model for parking lot monitoring. You might collect a wide range of images from AI datasets and ML datasets, representing different angles, lighting conditions, and weather scenarios. Amassing extensive, diverse data is beneficial.
However, the critical next step is making this raw data usable for training: specifically by labeling or tagging it in a manner that is consistent, accurate, and meaningful.
It is easy to see why data annotation is so important. If our CV (computer vision) model learns from inconsistent, incorrect, and incomplete data, how do you think our model would fare in the real world use cases, which are typically more complex and unpredictable? Barely.
Moreover, issues introduced during data annotation cannot usually be fixed later in the process. Hence, AI dataset management and dataset version control are also crucial for preserving data integrity throughout the project lifecycle. Think of it as the foundation of a building: if that foundation is unstable, addressing structural weaknesses afterward is extremely difficult. As Peter Thiel notes in Zero to One:
It’s hard to recover from a radically inferior starting point.
What are the Challenges in Data Annotation?
The proliferation of data annotation platforms, with each claiming superior features, pricing, or efficiency, indicates that data annotation remains a challenging and highly competitive field. Its very nature involves trade-offs.
Typically, two main approaches exist:
- Manual annotation: Traditionally, humans perform annotation tasks, often using a data labeling tool. Humans excel at considering context and identifying nuances but are limited by capacity and time, which is problematic when thousands (or millions) of images are needed. The result is a process that can be costly, slow, and inconsistent more often than not.
- Auto annotation: first, it is truly remarkable that we are living in the age where we annotated images for AI/ML models to do the annotation for us (see the video below). This data auto-annotation approach can accelerate the process but may fail in novel or unusual cases, since these methods lack the human ability to understand broader contextual cues.
As you can see, there are numerous trade-offs in data annotation. Most startups have been working on to solve these issues in a variety of ways, and Unitlab AI is no exception. Unitlab AI is this, summed up in a single image:
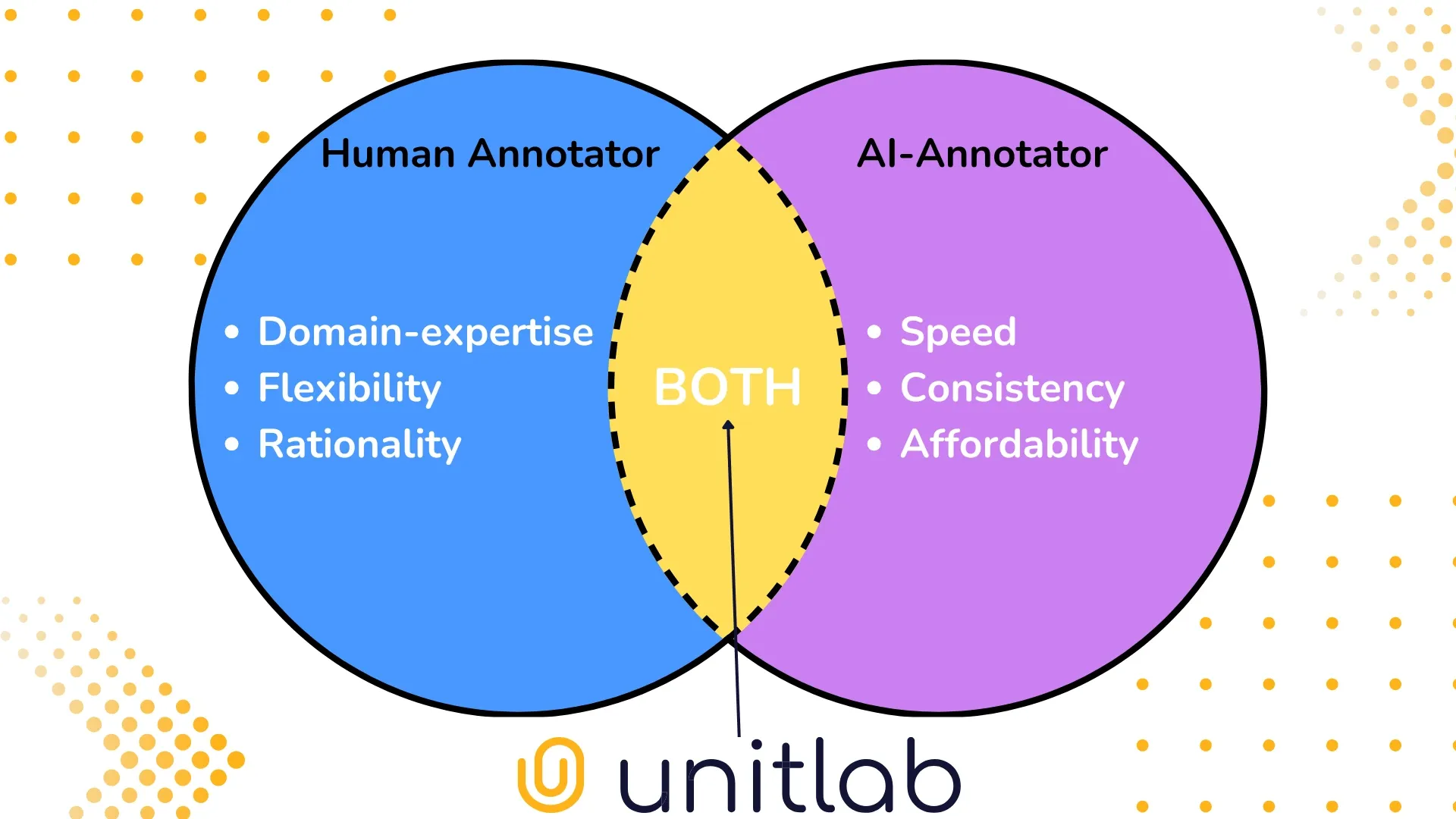
When focusing on specific challenges, consider the following:
- Time-Consuming Process: Manual annotation by human labelers requires significant time and effort, especially for large datasets. Consequently, many projects may opt for a data labeling service to handle large-scale tasks.
- Quality Control Issues: Inconsistent or ambiguous labels diminish model accuracy and degrade performance over time. This can make it difficult to pinpoint why a model yields inaccurate predictions. Common remedies include providing consistent, detailed labeling guidelines.
- High Costs: Annotating vast amounts of data is expensive, particularly for high-quality labeled datasets. In other words, the higher the quality, the higher the costs.
- Scalability: Large datasets demand efficient workflows and automation to ensure timely completion. This often involves automating tasks through CLI tools or SDKs to optimize processes.
Deciding on the best approach depends on each project’s unique needs. Nonetheless, the hybrid annotation method (combining automated tools with human oversight) has consistently shown promise.
Data annotation is by no means fully resolved, and differing opinions and standards abound. While many of these challenges are solvable, industry-wide consensus is still emerging.
This also represents an opportunity: numerous organizations, researchers, and individuals are actively developing robust image annotation solution strategies. In the meantime, it remains essential to consider your project’s requirements and monitor how different data annotation solution standards evolve and compete.

Conclusion
In summary, data annotation is the process of labeling or tagging images, video, text, or audio so AI/ML models can interpret and learn from them. Why does it matter so much?
Because data annotation is the foundational step that largely determines the quality and usefulness of any AI/ML model. It is impossible for a machine learning system to exceed the limitations of its training data. Data labeling ensures raw data is properly prepared for model training.
Although various solutions exist, industry-wide adoption of a single best practice is still lacking. Nonetheless, this gap highlights exciting opportunities for innovative companies and researchers to shape the future of data annotation. Until then, it is best to work within your specific project context and keep an eye on the evolving standards and tools in this space.
Explore More
- What is Computer Vision Anyway?
- Data annotation: Types, Methods, Use Cases.
- Data Annotation with Segment Anything Model (SAM)