Discover how Segment Anything Models (SAM) are reshaping pixel-level segmentation while enabling faster and more cost-efficient data annotation pipelines in real-world applications.
Pixel-level object segmentation is a fundamental requirement in many modern computer vision applications, including large-scale data annotation, medical imaging, robotics, and autonomous systems. To address this need, Meta AI introduced the Segment Anything Model (SAM), a foundation model designed to generate high-quality segmentation masks through flexible, prompt-driven inputs.
This blog provides a systematic comparison of SAM models, examining the architecture of each variant, analyzing their performance characteristics, and discussing real-world application scenarios to clarify when each model is most appropriate in practice.
Introduction
Image segmentation has traditionally been one of the most computationally demanding tasks in computer vision, largely due to its dependence on extensive pixel-level annotations and domain-specific models that require frequent retraining. As datasets grow in size and diversity, conventional segmentation pipelines often struggle to scale across different object categories and environments, particularly when speed and consistency are critical.
The Segment Anything Model (SAM) family introduced by Meta AI marks a significant shift in how segmentation problems are addressed. Rather than training narrowly focused models, SAM follows a foundation model approach that learns general visual representations capable of segmenting a wide range of objects using simple prompts such as points or bounding boxes. This design reduces the reliance on task-specific training data while enabling greater adaptability across multiple application domains.
With the continued development of the SAM ecosystem, several variants, including SAM1, SAM2, and SAM3, have emerged, each incorporating architectural refinements and performance improvements. These models differ in terms of backbone structure, inference efficiency, and suitability for real-time and large-scale workflows. For researchers and engineers deploying segmentation systems in practice, understanding these technical differences is essential for selecting the most appropriate model.
Today, we focus on the following topics:
All About SAM Models
- Architectural differences
- Performance and efficiency trade-offs
- Practical considerations for model selection
Real-World Applications of SAM Models in 2026
- Improvements in segmentation and annotation workflows
- Reduction in manual labeling effort
- Adoption within modern data annotation pipelines
All About SAM Models
This section compares how SAM1, SAM2, and SAM3 evolve in architecture and performance, and then extends the discussion to lightweight variants such as MobileSAM and FastSAM, showing how the SAM concept scales from research settings to mobile, edge, and real-time environments.
SAM1: The Foundation of Prompt-Driven Image Segmentation
The Segment Anything Model (SAM) is a family of prompt-driven segmentation models, with SAM1 as the original implementation that introduced general-purpose, pixel-level object segmentation for static images.
Architectural Overview
SAM1 is built around a modular architecture designed to support general-purpose, prompt-driven image segmentation. The model consists of three main components: an image encoder, a prompt encoder, and a mask decoder, each playing a distinct role in transforming raw images into pixel-level segmentation masks.
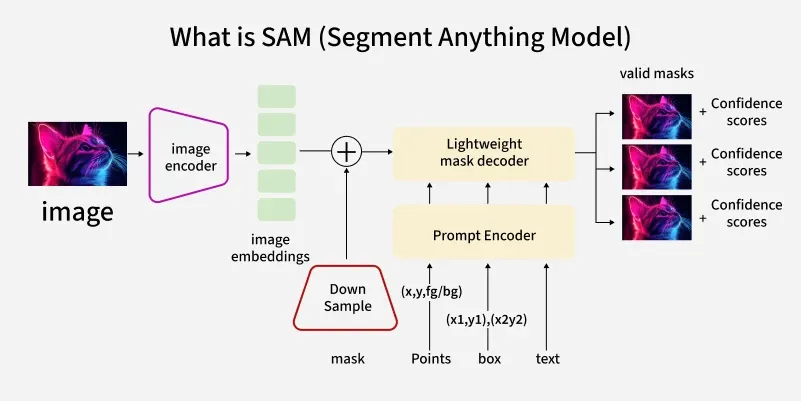
The image encoder uses a Vision Transformer backbone to extract rich, high-dimensional visual representations from the input image. This encoder is trained to capture general visual features that can transfer across object categories and domains, enabling SAM1 to generalize beyond task-specific datasets.
The prompt encoder translates user-provided inputs such as points, bounding boxes, or coarse masks into embedding representations that guide the segmentation process. This design enables SAM1 to adapt its output with minimal interaction, making it suitable for both interactive and automated workflows.
Finally, the mask decoder combines image embeddings and prompt embeddings to generate one or more segmentation masks. The decoder is optimized to produce high-quality object boundaries while maintaining flexibility across different prompt types. Multiple candidate masks can be generated, allowing downstream systems or users to select the most appropriate result.
Together, these components enable SAM1 to perform flexible, prompt-based segmentation without requiring retraining for new object categories, establishing the architectural foundation for later SAM variants.
SAM2: Enhancing Efficiency and Scalability in Prompt-Driven Segmentation
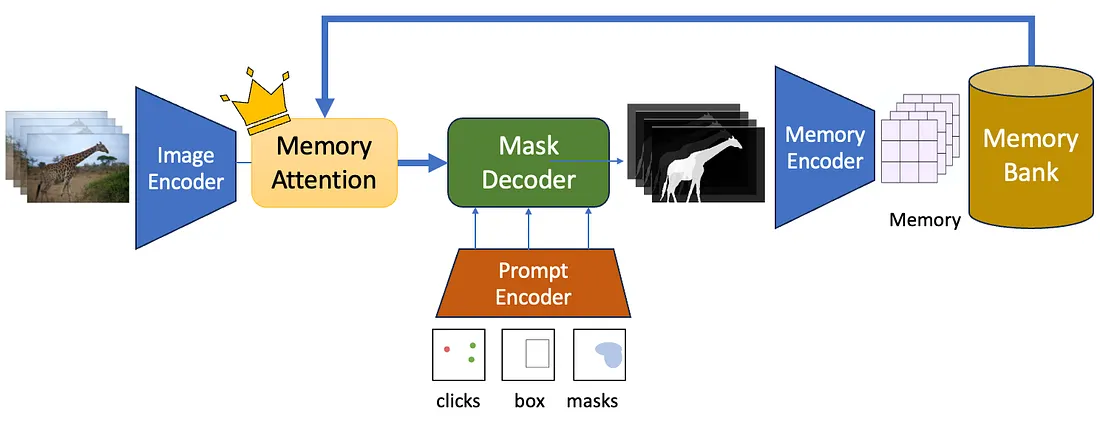
While SAM1 is designed for static image segmentation, SAM2 extends the framework to video by introducing a memory bank that preserves object representations across frames, enabling consistent segmentation and object tracking over time.
Architectural Overview
SAM2 extends the original SAM architecture to support both image and video segmentation, with a design that emphasizes temporal consistency and scalability. While it preserves the modular structure of SAM1, SAM2 introduces additional mechanisms to maintain object identity and segmentation quality across consecutive frames.
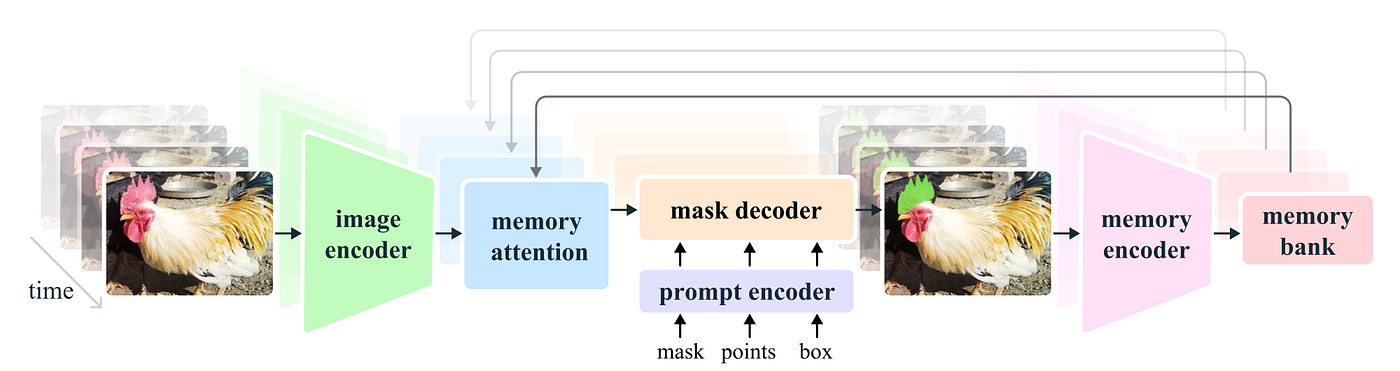
At its core, SAM2 still relies on an image encoder to extract high-level visual features from individual frames. These features are designed to be reusable across time, allowing the model to efficiently process video sequences without re-encoding redundant visual information.
The prompt encoder in SAM2 continues to accept user inputs such as points, bounding boxes, or masks, but these prompts can now be propagated across frames. This enables consistent segmentation of the same object throughout a video sequence with minimal additional user interaction.
The mask decoder is enhanced to incorporate temporal information, combining current frame embeddings with historical context from previous frames. This design allows SAM2 to generate stable segmentation masks over time, reducing flickering and inconsistencies that commonly occur in frame-by-frame segmentation.
Together, these architectural enhancements allow SAM2 to scale from static image segmentation to video-based workflows, making it suitable for applications such as video annotation, object tracking, and dynamic scene understanding while retaining the flexibility of the original SAM framework.
SAM3: Optimizing Segment Anything for Large-Scale and Production Use
SAM3 extends SAM2’s video-based design with further optimizations that enhance robustness, efficiency, and deployment scalability for production-grade video segmentation and object tracking tasks.
Architectural Overview
SAM3 builds upon the core principles of SAM1 and the video-aware extensions introduced in SAM2, with a primary emphasis on optimization and robustness in real-world environments. The architecture is designed to support high-throughput segmentation while maintaining strong segmentation quality across diverse data distributions.
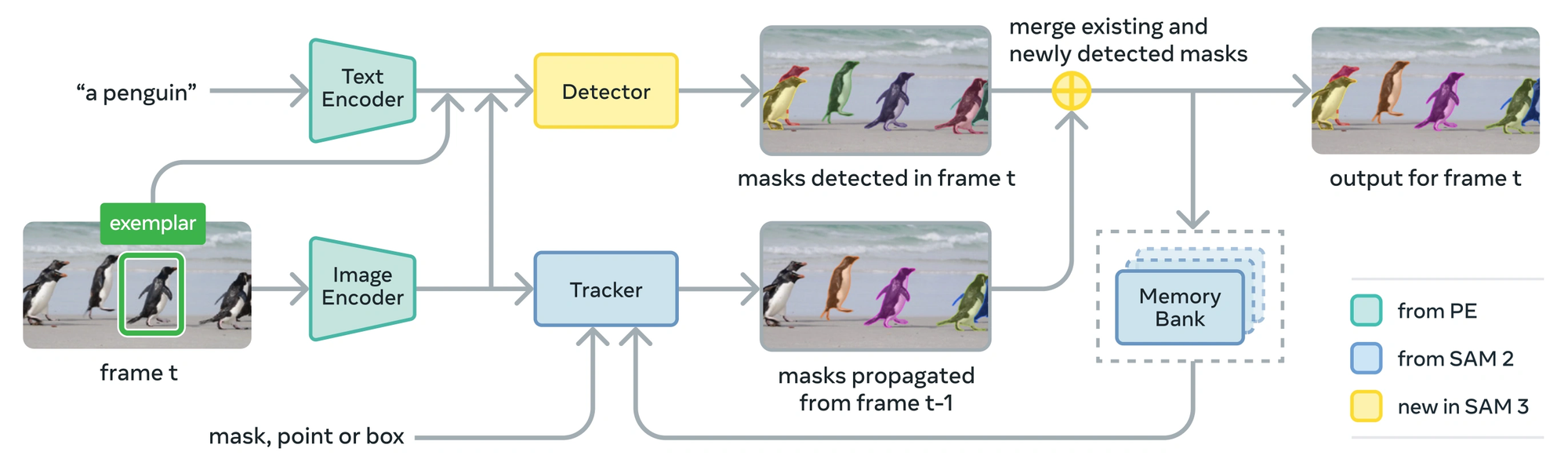
The image encoder in SAM3 is optimized for faster inference and reduced memory consumption, enabling efficient processing of high-resolution images and long video sequences. Architectural refinements and improved feature reuse allow SAM3 to scale more effectively in resource-constrained or production settings.
The prompt encoder continues to support flexible user inputs such as points, bounding boxes, and masks, but with enhanced handling for automated and large-scale pipelines. This allows SAM3 to operate effectively in scenarios where prompts are generated programmatically rather than through manual interaction.
The mask decoder is further refined to balance segmentation accuracy with computational efficiency. By improving mask generation stability and reducing redundant computations, SAM3 delivers consistent segmentation outputs suitable for continuous inference, batch processing, and deployment-focused workflows.
Overall, SAM3 is designed to transition the Segment Anything framework from research and annotation use cases toward reliable, scalable deployment in production systems, completing the progression from foundational segmentation to real-world operational readiness.
Comparison of SAM Models
The table below summarizes the key differences among the SAM model variants, highlighting their release timelines, development origins, and primary advantages and limitations. This comparison provides a high-level view of how the SAM family has evolved from image-based segmentation to video support and production-ready deployment. Moreover, to explore the implementation details and official source code, click the corresponding SAM model version in the table to access its GitHub repository.
Comparison of SAM Models
The table presents a quantitative comparison of SAM1, SAM2, and SAM3 on the SA-37 interactive image segmentation benchmark, reporting average mIoU under varying numbers of user interactions and inference speed in frames per second (FPS). The results demonstrate a clear performance progression across model generations: SAM2 and SAM3 substantially improve segmentation accuracy with fewer clicks compared to SAM1, while SAM2 achieves the highest throughput, reflecting its efficiency-oriented design. SAM3 attains the strongest multi-click accuracy, indicating improved robustness and refinement capability, albeit with lower peak FPS than SAM2. Overall, the comparison highlights the trade-offs between interactive accuracy, inference speed, and architectural optimization across SAM models.
| SAM Version | Year | Introduced By | mIoU (1-click) | mIoU (3-clicks) | mIoU (5-clicks) | FPS |
|---|---|---|---|---|---|---|
| SAM1 | 2023 | Meta AI | 58.5 | 77.0 | 82.1 | 41.0 |
| SAM2 | 2024 | Meta AI | 66.4 | 80.3 | 84.3 | 93.0 |
| SAM3 | 2025 | Meta AI | 66.1 | 81.3 | 85.1 | 43.5 |
Beyond SAM1, SAM2, and SAM3
Beyond the main SAM variants, the ecosystem has also expanded to include lighter and more specialized models such as MobileSAM and FastSAM. These extensions show how the core ideas behind SAM can be adapted to different usage scenarios without changing the overall interaction paradigm.
MobileSAM brings prompt-driven segmentation to mobile and edge environments by simplifying the original SAM design while remaining compatible with its pipeline. This makes it possible to run segmentation directly in settings where computational resources are limited, while still producing reliable object masks.
FastSAM takes a different path by relying on a CNN-based architecture tailored for responsive segmentation. It retains the prompt-based interaction style of SAM but is designed to generate masks quickly, making it well-suited for applications that require immediate visual feedback across a wide range of tasks.
Real-World Applications of SAM Models in 2026
SAM models have gained widespread adoption in real-world computer vision tasks, particularly in applications that demand accurate and reliable object boundary segmentation. In this section, we discuss how SAM improves segmentation and annotation workflows, reduces manual labeling effort, and is increasingly adopted within modern data annotation pipelines.
Improvements in Segmentation and Annotation Workflows
SAM models significantly improve segmentation and annotation workflows by shifting the process from manual boundary drawing to prompt-driven mask generation. Instead of creating object masks from scratch, annotators interact with the model using simple inputs, such as points or bounding boxes, allowing SAM to automatically infer accurate object boundaries.
This approach streamlines the annotation pipeline by reducing cognitive load on annotators and minimizing repetitive low-level tasks. As a result, annotation workflows become more structured and predictable, with faster turnaround times and improved consistency across large datasets. The ability to generate multiple candidate masks also enables quick selection and refinement, further enhancing workflow efficiency., such as points or bounding boxes, allowing SAM to automatically infer accurate object boundaries
Moreover, Figure 4 shows a traditional supervised segmentation pipeline requiring manual annotations and model training, whereas Figure 5 demonstrates a SAM-based prompt-driven workflow that generates accurate segmentation masks directly from user prompts, significantly improving annotation.
Reduction in Manual Labeling Effort
One of the most impactful contributions of SAM models is the substantial reduction in manual labeling effort required for pixel-level annotation tasks. Traditional segmentation workflows often require annotators to trace complex object contours, which is both time-consuming and prone to variability across individuals.
By automating the initial mask generation, SAM allows annotators to focus primarily on validation and correction rather than full mask creation. In many cases, a small number of prompts is sufficient to produce high-quality segmentation results, reducing the total annotation time per object by a large margin. This shift transforms labeling from a creation-heavy task into a review-oriented process, improving both efficiency and annotation quality.
Adoption Within Modern Data Annotation Pipelines
Modern data annotation pipelines increasingly adopt SAM models as foundational components due to their flexibility and scalability. SAM integrates seamlessly with existing computer vision systems, including object detection models and annotation management platforms, enabling hybrid workflows that combine detection, segmentation, and human review.
In large-scale environments, SAM supports batch processing, automated prompt generation, and video-based mask propagation, making it suitable for both offline dataset creation and continuous annotation pipelines. Its ability to generalize across object categories without retraining further reduces operational complexity, allowing teams to deploy a single segmentation framework across multiple projects.
As a result, SAM models are becoming a standard tool within contemporary annotation pipelines, supporting faster dataset production while maintaining the precision required for training high-performance computer vision models
Putting It All Together
The Segment Anything Model represents a shift in image and video segmentation toward general-purpose, prompt-driven frameworks that reduce reliance on task-specific training and dense manual annotation. By enabling pixel-level object understanding through simple user prompts, SAM expands the applicability of segmentation across diverse datasets and domains.
As segmentation tasks scale in size and complexity, challenges related to annotation cost, consistency, and workflow efficiency become increasingly important. Prompt-driven segmentation models such as SAM address these challenges by transforming annotation from manual mask creation into a faster review and refinement process.
Looking ahead, the impact of SAM will extend beyond model architecture to the design of scalable data and annotation pipelines that support large-scale computer vision systems. Readers interested in how SAM is applied within real-world annotation systems to accelerate mask generation, reduce manual labeling, and scale data pipelines can find further insights through Unitlab AI.