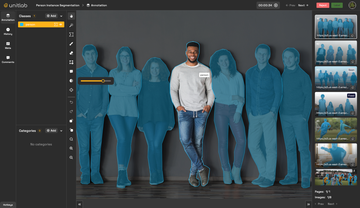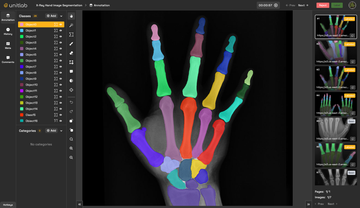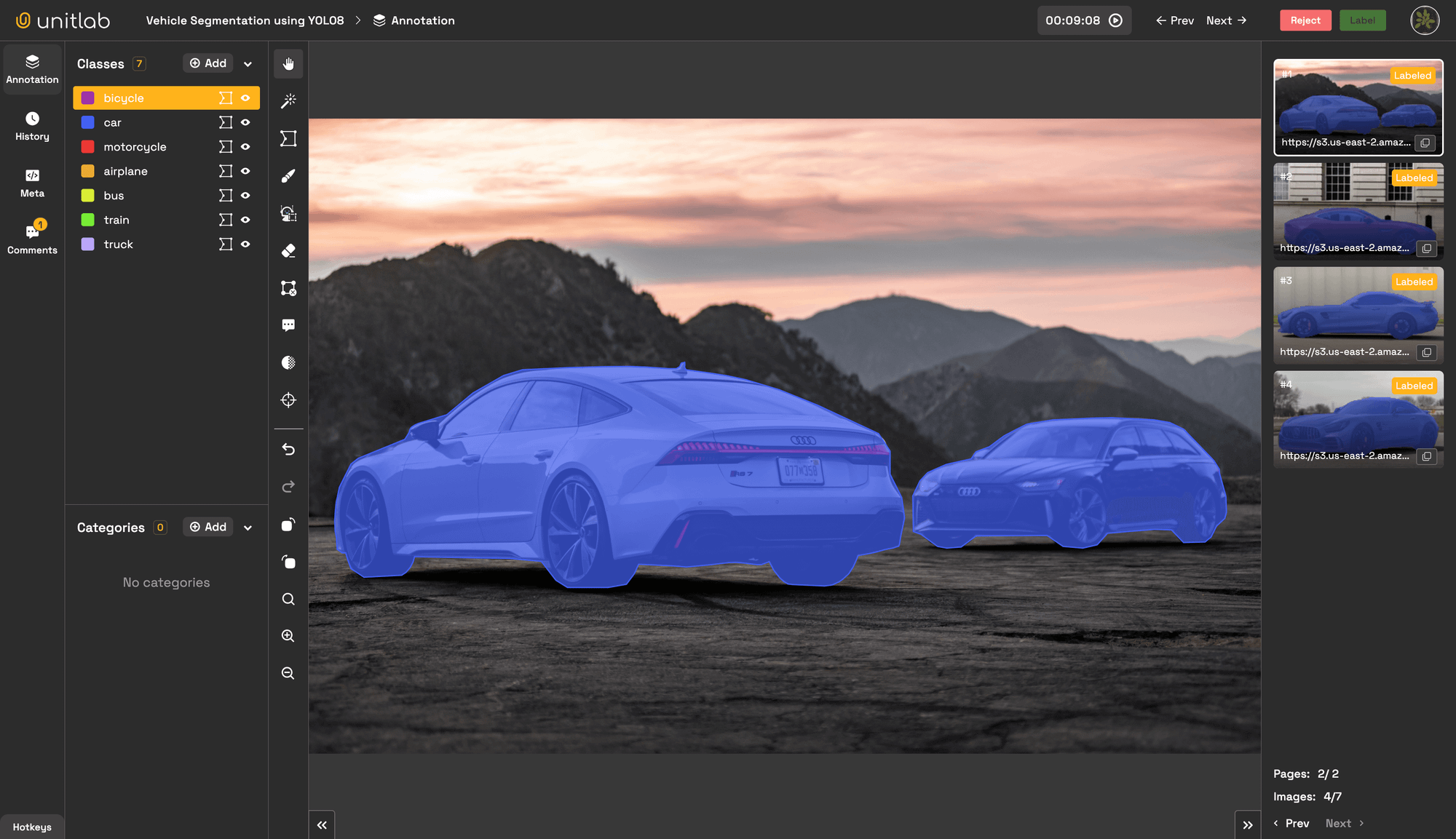
We've open-sourced a production-ready YOLOv8-Seg model deployment code with single-command deployment, optimized for both GPUs and CPUs using TensorRT and ONNX.
 teamunitlab
teamunitlabThis source code can be used either for learning about how to integrate your own AI models into Unitlab Annotate or for production purposes of your application.
The efficient Deployment
There are several factors how to achieve efficiency in the model deployment of the server. Let's learn each factor.
- Service Architecture
- Inference Tools: Pytorch, Torch, Tensorflow, TensorRT, ONNX-Runtime
- Serving tools: TorchServe, TensorFlow Serving, KF Serving, and Triton Server, or the common web frameworks are used as serving tools, including FlaskAPI, FastAPI, etc.
- Hardware acceleration (GPU & CPU)
1. Service Architecture
The model service architecture plays a crucial role in the deployment of segmentation models, particularly due to their large mask output sizes. To find an efficient service architecture for segmentation models, we first need to answer the following question:
How can we efficiently handle the large mask output size of segmentation in responses?
There are common practical scenarios regarding the response format of the service. These include the segmentation output mask as an image, a bitmap image in binary format, or as JSON that contains segmentation contours. We used the Locust Tool to benchmark and identify the most effective service architecture for deploying segmentation models, focusing on measuring Requests Per Second (RPS) in a consistent environment. Although extracting segmentation contours requires additional post-processing, which may increase CPU load, our analysis showed that utilizing JSON to represent segmentation contours is the most efficient method in terms of RPS. This approach is superior to directly transmitting mask data as images, bitmaps, or in binary format. To extract segmentation contours, we used OpenCV's FindContours() function to find contours from each mask, corresponding to each instance predicted by YOLOv8.
2. Inference Tools
The choice of inference tools directly impacts service efficiency. Models can be deployed easily using PyTorch and TensorFlow; however, for deployment purposes, they are not as efficient as they are for model training. If you're planning to deploy models on a GPU, TensorRT is recommended. It is highly optimized for minimal GPU memory usage and offers faster inference speeds compared to other alternatives. In instances where models need to be deployed on a CPU, ONNX Runtime is the recommended option due to its high optimization for lower memory usage and enhanced CPU efficiency.
3. Serving Tools
There are many model serving tools; some of them provide both inference and serving capabilities, such as TorchServe, TensorFlow Serving, KF Serving, and Triton Server. Additionally, common web frameworks, such as FlaskAPI and FastAPI, are used as serving tools. As choosing web frameworks as a serving tool offers more freedom in terms of designing the service architecture, we used the FlaskAPI as a serving tool in this repository.
4. Hardware acceleration (GPU & CPU)
Based on your resource capabilities, you can deploy models using either CPU or GPU. We have developed this repository to support both scenarios.
Let's Deploy
Let's deploy the YOLOv8-Seg model using the following steps. You can find these instructions in the repository as well.
Clone the repository to your local system:
git clone https://github.com/teamunitlab/yolo8-segmentation-deploy.git
cd yolo8-segmentation-deployUse Docker Compose to deploy for CPU environments:
docker-compose -f docker-compose-cpu.yml up -d --buildUse Docker Compose to deploy for GPU acceleration:
docker-compose -f docker-compose-gpu.yml up -d --buildTest the deployment locally to ensure everything is working correctly:
# Using cURL
curl -X POST http://localhost:8080/api/yolo8/coco-segmentation
-H "Content-Type: application/json" \
-d '{"src":"example.com/test-image.jpg"}'Visualize Results
To visualize results and ensure the service is working well, you can use OpenCV to render contour results of the service deployed using the repository. Alternatively, you can integrate the service with Unitlab Annotate for visualization, auto-annotation, and model evaluation purposes.

Conclusion
In the repository and blog, we learned how to efficiently deploy segmentation models, taking the YOLOv8-seg model as an example, and how to visualize the results of the service using Unitlab Annotate.