

YOLO-26 explained: architecture, performance, and production-ready computer vision use cases
Object detection is a core task in computer vision that allows machines to identify and locate multiple objects within images and videos. As computer vision systems have expanded into real-time applications such as autonomous driving, robotics, and large-scale data annotation, the demand for fast and accurate object detection models has increased significantly.
To meet these demands, the YOLO family of models was introduced as a direct object detection approach that performs detection and classification in a single pass. Since the first YOLO model, each new version has improved detection accuracy, inference speed, and training efficiency. These continuous improvements have made YOLO one of the most widely adopted object detection frameworks in both academic research and industrial applications.
However, modern computer vision workloads now operate under stricter performance requirements than earlier systems. Higher resolution inputs, improved small object detection, efficient edge deployment, and the need for automated annotation pipelines have introduced challenges that previous YOLO versions were not fully designed to handle. As a result, a new release, YOLO 26, has emerged to better address these evolving requirements and to align object detection performance with current real-world production needs.
In this blog, we cover the following topics:
• What YOLO 26 is and how it works
• An overview of the model architecture
• Performance comparison with previous YOLO versions
• How to run YOLO 26 using the Ultralytics framework
• Real-world use cases, with a focus on automated data annotation
What is YOLO-26?
YOLO 26 is the most recent release in the YOLO family, developed by Ultralytics and introduced on September 25, 2025. This release represents a shift in design priorities, moving away from increasing architectural complexity and toward deployment-oriented efficiency. The goal of YOLO 26 extends beyond improving detection performance, focusing instead on a streamlined design that eliminates unnecessary complexity while introducing targeted innovations for faster, lighter, and more accessible deployment across diverse environments.
In addition to traditional object detection, YOLO 26 is designed as a unified computer vision framework that supports multiple vision tasks within a single model family. These tasks include object detection, instance segmentation, pose and keypoint estimation, oriented object detection, and image classification. By supporting multiple tasks under a shared architecture, YOLO 26 enables consistent workflows and simplifies deployment across different computer vision applications, as illustrated in Figure 2.
Compared to earlier versions, YOLO 26 places greater emphasis on streamlined regression mechanisms and fully end-to-end prediction behavior. In addition, training time refinements enabled by improved optimization strategies contribute to more stable convergence and better overall efficiency. These changes make the model particularly well-suited for real-time applications, large-scale deployment, and automated computer vision pipelines.
To better understand how these design goals are achieved in practice, the next section provides a detailed examination of the architecture of YOLO 26.
YOLO-26 Architecture
The architecture of YOLO 26 is designed around a streamlined and efficient detection pipeline that is purpose-built for real-time object detection across both edge devices and server environments. Rather than adding architectural complexity, YOLO 26 focuses on simplifying critical components while introducing targeted innovations that improve deployment reliability, inference speed, and training stability.
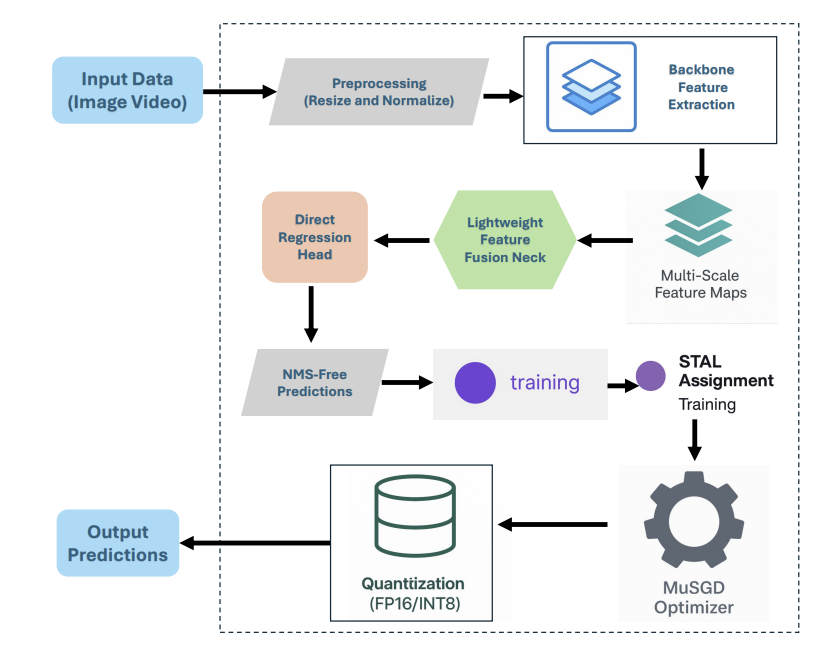
Two major architectural changes define this release.
First, the detection head removes Distribution Focal Loss-based distributional regression and replaces it with a lighter, hardware-friendly bounding box parameterization. By eliminating DFL, YOLO 26 reduces graph complexity and removes operators that were fragile across different compilers and runtimes. This change significantly improves compatibility with quantization and makes the model easier to deploy across a wide range of hardware platforms.
Second, the decoding path is redesigned to support full end-to-end real-world inference without using Non Maximum Suppression. Rather than producing overlapping predictions that require additional filtering, the detection head outputs a compact and clearly structured set of results directly. This removes a traditional latency bottleneck and eliminates deployment configuration parameters such as IoU and confidence thresholds, which often require manual tuning in real-world production systems.
Beyond architectural simplification, YOLO 26 introduces several training time improvements that enhance convergence stability and detection quality. Progressive Loss balancing, referred to as ProgLoss, dynamically adjusts the relative importance of classification, localization, and auxiliary loss terms during training. This prevents domination by easy negatives or large objects in later epochs and results in smoother and more reliable convergence.
Small Target Aware Label assignment, referred to as STAL, further improves performance by ensuring that small, occluded, or low contrast objects receive sufficient supervisory signal during training. By adjusting assignment priorities and spatial tolerance, STAL significantly improves recall in scenarios involving edge devices such as UAV imagery, smart cameras, and mobile robotics.
Optimization in YOLO 26 is driven by MuSGD, a hybrid optimizer that combines the simplicity and generalization strength of standard SGD with momentum-based and curvature-informed update strategies inspired by modern large model training. In practice, MuSGD shortens the time required to reach stable performance, reduces instability during later training stages, and improves reproducibility across model scales ranging from nano to extra-large variants.
Together, these architectural and training innovations enable several practical improvements. YOLO 26 supports broader device compatibility by simplifying inference and enabling export to formats such as TFLite, CoreML, OpenVINO, TensorRT, and ONNX. It also delivers stronger small object recognition through ProgLoss and STAL, making it well-suited for IoT, robotics, and aerial imagery applications. Direct prediction without post-inference filtering reduces latency and improves deployment reliability, while model design and training optimizations significantly improve CPU efficiency for real-time operation.
Performance Benchmarks
The YOLO-26 family includes multiple model variants designed to address different trade-offs between accuracy, inference speed, and computational cost. These variants allow practitioners to select an appropriate model based on available hardware resources, latency requirements, and target application scenarios. Lighter models prioritize fast inference and low resource usage, making them suitable for edge devices and real-time systems, while larger models offer higher accuracy at the cost of increased computational complexity, making them more appropriate for server-side deployment.
| Model | Input Size (px) | mAP (50–95) | CPU Inference ONNX (ms) | GPU Inference T4 TensorRT (ms) | Parameters (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 38.9 ± 0.7 | 1.7 ± 0.0 | 2.4 | 5.4 |
| YOLO26s | 640 | 48.6 | 87.2 ± 0.9 | 2.5 ± 0.0 | 9.5 | 20.7 |
| YOLO26m | 640 | 53.1 | 220.0 ± 1.4 | 4.7 ± 0.1 | 20.4 | 68.2 |
| YOLO26l | 640 | 55.0 | 286.2 ± 2.0 | 6.2 ± 0.2 | 24.8 | 86.4 |
| YOLO26x | 640 | 57.5 | 525.8 ± 4.0 | 11.8 ± 0.2 | 55.7 | 193.9 |
The table above provides a detailed overview of the YOLO-26 model variants, comparing their performance across key metrics such as detection accuracy, inference latency on CPU and GPU, parameter count, and overall computational complexity. Moreover, for more detailed information, please refer to the official YOLO GitHub repository.
Moreover, it is useful to examine how YOLO-26 compares with previous YOLO versions. Relative to earlier releases, YOLO-26 places a stronger emphasis on deployment efficiency, simplified inference, and improved CPU performance, while maintaining competitive detection accuracy across different model scales, as shown in the following table. These changes highlight a shift in YOLO development toward practical usability in real-world systems, particularly for edge deployment, large-scale pipelines, and production environments.
| Model | Variant | mAP (50–95) | CPU ONNX (ms) | T4 TensorRT (ms) | Params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv5 | n | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
| YOLOv8 | n | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8 | s | 44.9 | 128.4 | 1.90 | 11.2 | 25.9 |
| YOLOv8 | m | 50.5 | 197.5 | 3.30 | 25.9 | 63.3 |
| YOLO11 | n | 39.5 | 56.1 | 1.5 | 2.6 | 6.5 |
| YOLO11 | s | 47.0 | 90.0 | 1.9 | 9.2 | 16.7 |
| YOLO11 | m | 50.3 | 171.0 | 3.0 | 20.0 | 44.8 |
| YOLO-26 | n | 39.8 (40.3 e2e) | 38.9 | 1.7 | 2.4 | 5.4 |
| YOLO-26 | s | 47.2 (47.6 e2e) | 87.2 | 2.7 | 9.5 | 20.7 |
| YOLO-26 | m | 51.5 (51.7 e2e) | 220.0 | 4.9 | 20.4 | 68.2 |
| YOLO-26 | l | 53.0–53.4 | 286.2 | 6.5 | 24.8 | 86.4 |
Overall, the comparison shows that YOLO-26 continues the trend toward deployment-oriented efficiency while maintaining competitive detection accuracy across model sizes. Compared with earlier YOLO versions, YOLO-26 delivers similar or improved mAP with reduced model complexity, particularly in the Nano and Small variants. The introduction of end-to-end predictions enables comparable accuracy without post-inference suppression, while improvements in CPU inference performance and parameter efficiency make YOLO-26 especially suitable for real-time and resource-constrained deployment scenarios.
YOLO-26 in Practice with Ultralytics
This section demonstrates how to quickly test YOLO-26 using Ultralytics. The goal is to verify that the model runs correctly on your machine and to run a simple inference test on an image or video using both the command line and Python.
1) Install Ultralytics
pip install -U ultralytics
This step installs the official Ultralytics Python package, which provides the YOLO-26 models and a unified API for training, inference, and deployment. Running this command will download all required dependencies and make the YOLO class available in your Python environment.
After installation, you are ready to load pretrained YOLO-26 models and run inference without additional setup.
2) Load, Train, and Test YOLO-26 Using Python
from ultralytics import YOLO
# Load a COCO pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset
train_results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference on an image
predict_image = model.predict(source="path/to/bus.jpg", conf=0.25, save=True)
# Run inference on a video file
predict_video = model.predict(source="path/to/video.mp4", conf=0.25, save=True)
# Run inference on a webcam (0 = default camera)
predict_webcam = model.predict(source=0, conf=0.25, show=True)
This step shows how to work with YOLO-26 using the Python API.
First, a pretrained YOLO26n model is loaded. The Nano variant is lightweight and ideal for quick testing and experimentation.
Next, the model is trained on the COCO8 example dataset. COCO8 is a small subset of the COCO dataset and is commonly used to verify that the training pipeline is working correctly. Training for a limited number of epochs allows you to test the full workflow without long runtimes.
After training, inference is demonstrated on multiple input sources:
- Image inference runs object detection on a single image file and saves the annotated result.
- Video inference processes each frame of a video and outputs a labeled video file.
- Webcam inference performs real-time detection using your default camera, allowing you to visually confirm that YOLO-26 is working interactively.
All prediction outputs are automatically saved to the runs/ directory unless disabled, making it easy to inspect results and verify model behavior.
Use Case of YOLO-26
Like other YOLO models, YOLO 26 belongs to a family of real-time computer vision models designed to support a wide range of tasks, including object detection, instance segmentation, pose estimation, image classification, and oriented object detection. This versatility makes YOLO 26 particularly well-suited for automated data annotation workflows, where speed, consistency, and scalability are critical.
One important use case of YOLO 26 is automated data annotation, where the model is used to generate initial labels for large image and video datasets. Instead of manually drawing bounding boxes or masks from scratch, practitioners can apply a pretrained YOLO 26 model to automatically produce annotations, which are then reviewed and refined by human annotators. This human-in-the-loop approach significantly reduces labeling time and cost while improving consistency across datasets.
In practice, YOLO 26 can be integrated into modern annotation platforms such as Unitlab, where automated predictions are used to accelerate labeling workflows. YOLO 26 serves as a pre-annotation engine, generating object proposals, regions of interest, or task-specific outputs that annotators can quickly validate or correct. This combination of automated inference and human oversight enables scalable and production-ready annotation pipelines.
The deployment-oriented design of YOLO 26 further supports this use case by enabling fast batch inference and efficient execution across different hardware environments. Its ability to run on both CPU and GPU allows annotation workflows to scale flexibly, whether deployed on premises or in cloud-based systems.
Beyond data annotation, YOLO 26 is widely applicable to real-time perception tasks such as video analytics, robotics, smart surveillance, traffic monitoring, and industrial inspection. Its deployment-oriented design and end-to-end prediction behavior allow it to produce compact predictions directly, simplifying system integration and reducing inference latency in high-throughput environments.
YOLO 26 also performs well in challenging conditions involving small or densely packed objects, making it suitable for aerial imagery, retail scenes, and edge device data from drones, smart cameras, and mobile robots. Efficient execution on both CPU and GPU further enables flexible deployment across on-premises systems and cloud-based pipelines.
Conclusion
YOLO-26 reflects a clear shift toward deployment-oriented computer vision, emphasizing simplified inference, stable training, and efficient execution across diverse hardware environments. Its end-to-end prediction design and streamlined architecture improve usability while maintaining competitive detection accuracy.
With multiple model variants and support for a wide range of vision tasks, YOLO-26 is well-suited for real-time applications, large-scale pipelines, and automated data workflows. Combined with the Ultralytics ecosystem, it offers a practical and production-ready solution for modern computer vision systems.
References
- YOLO26 (2025). YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection.
- Ultralytics YOLO Evolution: An Overview of YOLO26, YOLO11, YOLOv8, and YOLOv5 Object Detectors for Computer Vision and Pattern Recognition.
- Mastering All YOLO Models from YOLOv1 to YOLOv12: Papers Explained.
- Ultralytics. YOLO Documentation
- Roboflow. YOLO Models Explained and Compared.

