

Auto-annotationFoundation models have dramatically changed the pace of data annotation. With the emergence of SAM models and large-scale detection architectures like YOLO, auto annotation tools can now generate masks, bounding boxes, and labels across massive datasets in minutes. What once required weeks of manual data labeling and annotation services can now be accelerated through AI-powered labeling software and labeling automation tools.
This transformation is reshaping the entire ecosystem. From every data annotation startup to established dataset labeling companies and annotation service providers, organizations are investing in scalable annotation workflows, annotation workflow automation, and AI-accelerated annotation tools. Whether through a data labeling platform, dataset annotation tool, ML model annotation service, or enterprise data annotation platform, automation is becoming the new default in machine learning data labeling.
The numbers look promising. Throughput increases. Costs decrease. Computer vision annotation pipelines scale across domains such as medical image labeling, geospatial image annotation, robotics dataset annotation, and industrial automation dataset preparation. Zero-shot segmentation from foundation models makes image annotation for computer vision appear almost effortless.
And that is precisely where the misconception begins.
If foundation models are this powerful, if automated image labeling tools can generalize across tasks, and if AI labeling tools can generate training data at scale, do we still need quality assurance in data annotation for machine learning?
Is QA becoming redundant in the era of foundation models?
Or is something more subtle happening inside modern annotation pipelines?
Auto annotation tools are redefining efficiency. But efficiency alone does not define reliability. As computer vision ML data becomes more complex and applications move closer to safety-critical production environments, the question is no longer how fast we can label data. The real question is how confidently we can trust it.
To understand why this distinction matters, we need to examine how auto-annotation tools actually behave at scale and where hidden risks can emerge within modern data labeling solutions.
That is where the real story begins.
The Rise of Auto-Annotation
Before automation became central to modern AI development, data annotation for machine learning was primarily a manual operation. Image dataset labeling required annotators to draw bounding boxes, polygons, and segmentation masks using computer vision annotation tools. Dataset labeling companies scaled by expanding annotation teams, while data labeling outsourcing companies focused on workforce efficiency rather than technological acceleration.
As computer vision ML data demands increased, traditional workflows began to struggle. Manual bounding box labeling tools and segmentation dataset tools could not keep pace with the volume required for robotics dataset annotation, medical image labeling, geospatial image annotation, and industrial automation dataset preparation. The pressure to produce large-scale, high-quality training data pushed the industry toward automation.
The structural shift occurred when AI-powered labeling software evolved from simple assistance to full automation. Modern auto-annotation tools began generating complete annotations across object detection labeling tool pipelines and instance segmentation labeling workflows. Annotation workflow automation and annotation pipeline automation became embedded within enterprise data annotation platforms and dataset management platforms.
Instead of drawing every object manually, annotators increasingly review, refine, and validate AI-generated outputs from automated image labeling tools.

The image above showcases auto annotation inside Unitlab’s data labeling platform. In a dense traffic scene, Unitlab’s AI-powered labeling software automatically generates bounding boxes and multi-class labels such as car, bus, truck, motorcycle, and person-head across dozens of objects simultaneously.
Instead of manually drawing each object, annotators receive pre-generated labels through Unitlab’s AI-accelerated annotation tool. This significantly reduces labeling time while maintaining structured, scalable annotation workflows. With high-density object detection handled automatically, teams can focus on validation rather than drawing — transforming traditional image dataset labeling into an efficient, review-driven process.
This is how modern enterprise data annotation platforms move from manual annotation to intelligent labeling automation.
This example highlights several important characteristics of modern dataset annotation tools:
- High-density object detection labeling within a single frame
- Simultaneous multi-class annotation
- Real-time visual overlay inside the computer vision annotation tool
- Scalability across complex scenes
In traditional workflows, each bounding box would need to be drawn manually. In contrast, AI-accelerated annotation tools pre-generate these labels instantly, allowing the annotator to shift from drawing to reviewing.
This capability is particularly valuable in:
- Robotics dataset annotation and obstacle detection training data
- Smart city and traffic computer vision projects
- Warehouse robot dataset annotation
- Autonomous vehicle dataset preparation
- Large-scale CV dataset creation
For data annotation startups and annotation service providers, this transformation changes the operational model. A data labeling platform is no longer just a manual interface; it becomes a scalable annotation workflow engine supported by labeling automation tools and CV labeling automation systems.
Evolution of Data Annotation Workflows
| Aspect | Traditional Data Annotation | Modern Auto-Annotation Era |
|---|---|---|
| Workflow Driver | Human annotators | AI-powered labeling software |
| Primary Tools | Bounding box labeling tool, polygon annotation tool | Auto annotation tools, AI labeling tools |
| Scalability Model | Workforce expansion | Annotation workflow automation |
| Speed of Image Dataset Labeling | Resource-dependent | High-throughput via automated image labeling tool |
| Dataset Management | Manual tracking | Integrated dataset management platform |
| Cross-Industry Expansion | Limited by human capacity | Scalable across robotics, medical imaging annotation, geospatial image annotation, and manufacturing data annotation |
| Quality Control | Manual review cycles | Hybrid human-in-the-loop + annotation QA automation |
This transformation has reshaped how dataset labeling companies, data labeling outsourcing companies, and computer vision outsourcing companies position themselves. Instead of competing purely on workforce size, organizations increasingly differentiate through AI dataset creation service capabilities, annotation workflow automation depth, and enterprise data annotation platform infrastructure.
From the outside, the results appear technologically mature. Bounding box labeling outputs look aligned. Multi-class detection appears precise. Machine learning data labeling pipelines operate at unprecedented scale.
Yet visual precision does not automatically guarantee structural reliability.
To understand why even dense, visually convincing outputs from advanced auto-annotation tools can still introduce hidden weaknesses into computer vision ML data, we must examine the illusion of perfect automation.
The Illusion of Perfect Automation
Auto-annotation tools powered by foundation models produce visually convincing results. Bounding boxes align tightly. Instance segmentation masks appear precise. Multi-class detection scales across thousands of images. From a surface perspective, modern data annotation tools appear production-ready.
But visual correctness is not the same as structural reliability.
Most teams evaluate labeling quality using model performance metrics such as mAP (mean Average Precision). When mAP scores are high, it creates confidence that machine learning data labeling pipelines are accurate. However, mAP measures model prediction performance — not dataset consistency.
This distinction is critical.
Auto annotation tools optimize speed and pattern recognition. They do not inherently optimize:
- Cross-image consistency
- Boundary precision uniformity
- Rare class reliability
- Edge-case robustness
- Temporal stability in video annotation
In large-scale computer vision ML data projects, small inconsistencies can accumulate silently.

The example above shows peppers automatically labeled using a dataset annotation tool. On the right side, the bounding boxes appear aligned and consistent. Every object is detected. At first glance, the output looks correct.
However, the class label reads “paper.”
The mistake is subtle. The bounding box labeling looks clean. The segmentation overlay is precise. Yet the semantic label contains an error. If this label propagates across a scalable annotation workflow, the mistake becomes systemic within the computer vision ML data pipeline.
This illustrates a key limitation of automated image labeling tools: they replicate patterns efficiently, including incorrect ones.
In an enterprise data annotation platform, such inconsistencies may affect:
- Model training data integrity
- Ontology alignment across datasets
- Class distribution statistics
- Downstream model generalization
Automation accelerates labeling. It does not validate semantics.
However, the illusion of perfect automation arises because outputs look accurate. Bounding boxes are tight. Objects are detected. The interface is clean. Productivity increases.
But dataset reliability depends on more than visual alignment.
Below is a structural comparison between what labeling automation tools optimize and what they often overlook:
Automation Performance vs Dataset Integrity
| Dimension | What Auto Annotation Optimizes | What It Does Not Automatically Guarantee |
|---|---|---|
| Detection Coverage | High object detection recall | Semantic correctness of labels |
| Visual Precision | Tight bounding box alignment | Consistent boundary standards across datasets |
| Scalability | High-throughput image dataset labeling | Rare class robustness |
| Efficiency | Reduced manual drawing time | Ontology consistency |
| Pattern Recognition | Strong performance on dominant classes | Edge-case reliability |
| Confidence Scores | High prediction confidence | Dataset-level validation |
When data labeling platforms rely heavily on AI-powered labeling software without structured validation, inconsistencies can propagate across thousands or millions of labeled samples.
In robotics dataset annotation, a small misclassification can impact obstacle detection training data.
In medical image labeling, a subtle segmentation drift may affect organ boundary precision.
In geospatial image annotation, slight misalignment can distort the mapping dataset's annotation accuracy.
The problem is not that auto-annotation tools fail.
The problem is that they succeed convincingly.
And that success can mask structural weaknesses in data annotation for machine learning.
Understanding this illusion is essential before examining what happens when such datasets move from annotation environments into real-world production systems.
Where Auto-Annotation Breaks in Production
The illusion of perfect automation becomes visible not inside the annotation interface — but in production environments.
When datasets move from a data annotation tool into real-world systems, hidden inconsistencies surface under operational pressure. Models trained on visually convincing yet structurally inconsistent training data may perform well in controlled validation settings but degrade in dynamic environments.
Auto annotation tools optimize pattern recognition based on historical data distributions. Production systems, however, operate under distribution shifts:
- Variations in lighting conditions
- Changes in object orientation and scale
- Emergence of rare or underrepresented edge cases
- Increased environmental noise and distortion
- Operationally significant class imbalance
These are the conditions where subtle dataset weaknesses amplify.

The image above illustrates how detection performance changes under adverse weather and lighting scenarios. In fog, rain, snow, and nighttime conditions, visibility is reduced, contrast shifts, and object boundaries become ambiguous. Even high-performing object detection labeling pipelines begin to miss detections, lower confidence scores, or misclassify objects.
This degradation is not necessarily due to poor model architecture. In many cases, it reflects limitations in the original machine learning data labeling process.
If the image dataset labeling pipeline did not enforce:
- Boundary precision consistency
- Rare class validation
- Robust segmentation standards
- Cross-environment dataset coverage
- Systematic annotation QA automation
then small inconsistencies become magnified during deployment.
The relationship between annotation quality and production stability becomes clearer when mapped structurally:
| Production Factor | Annotation Assumption | Real-World Impact |
|---|---|---|
| Lighting Variation | Clean daytime training data | Reduced detection confidence at night |
| Weather Distortion | Clear object boundaries in dataset annotation tool | Missed detections in fog or rain |
| Rare Objects | Dominant-class-focused labeling | Failure on underrepresented classes |
| Scale Variation | Uniform bounding box standards | Inconsistent localization performance |
| Occlusion | Fully visible training samples | Partial detection or false negatives |
| Dataset Consistency | High mAP in validation | Unstable predictions under distribution shift |
High mAP during validation does not measure resilience under environmental stress.
And this is where the operational cost begins.
Moreover, in robotics dataset annotation, slight misclassification can affect obstacle detection training data and path planning reliability.
Furthermore, in medical image labeling, subtle segmentation drift may impact organ boundary precision and downstream diagnostic models.
In another example in geospatial image annotation, small polygon inconsistencies can distort mapping dataset annotation outputs at scale.
In industrial automation dataset preparation, minor bounding box misalignment can reduce industrial robot vision labeling stability in conveyor belt object detection data.
The failure is rarely immediate or catastrophic.
It appears as:
- Gradual performance degradation
- Increased retraining cycles
- Rising QA overhead
- Model instability in edge cases
- Escalating operational risk
Auto annotation tools accelerate scalable annotation workflows.
They do not automatically guarantee production resilience.
This is the moment where quality assurance transitions from optional review to structural necessity.
Why QA Is Structural, Not Optional
Modern data annotation platforms should treat QA the way production systems treat monitoring and validation as built-in safeguards.
Automation generates labels. QA validates structure.
Automation focuses on speed and pattern recognition.
QA focuses on dataset integrity and long-term reliability.
; is a simple view of how automation feeds into validation, rather than replacing it:
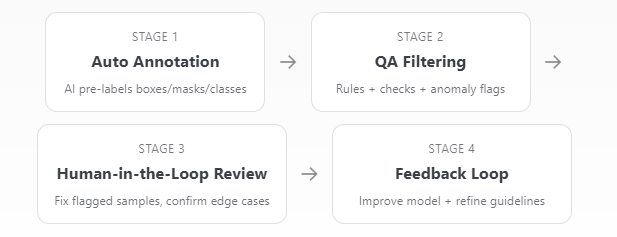
The workflow above illustrates a critical shift in modern data annotation platforms. Auto annotation generates speed, but QA filtering and human-in-the-loop validation enforce structural consistency. The feedback loop ensures that corrections are not isolated events; they improve the model and refine future annotation cycles. This transforms annotation from a one-time task into a continuously optimized system.
To understand why this architecture matters, it is useful to compare an automation-only workflow with a QA-integrated annotation platform. The difference is not simply operational; it is structural. One scales volume. The other scales' reliability.
Automation-Only vs QA-Integrated Pipeline
The difference becomes clearer when comparing workflows:
| Dimension | Automation-Only Workflow | QA-Integrated Annotation Platform |
|---|---|---|
| Speed | High-throughput image dataset labeling | High-throughput with structural validation |
| Label Generation | AI-powered labeling software | AI + annotation QA automation rules |
| Consistency | Model-dependent | Cross-dataset enforcement mechanisms |
| Ontology Control | Static class replication | Managed taxonomy governance |
| Rare Class Handling | Pattern-driven | Targeted verification and balancing |
| Drift Detection | Reactive (post-training) | Proactive dataset monitoring |
| Production Readiness | Visually convincing | Structurally validated and deployment-safe |
| Risk Exposure | Hidden dataset bias | Controlled reliability management |
The distinction is not about adding manual review. It is about embedding control mechanisms inside the data labeling platform itself. Structural QA ensures that speed does not come at the expense of reliability, and that scalable annotation workflows remain production-ready rather than visually convincing.
Automation accelerates dataset creation.
QA protects model credibility.
In the era of foundation models, competitive advantage is not defined by how fast you label data.
It is defined by how structurally you validate it.
The Business Risk of Skipping QA
While auto-annotation tools reduce labeling time and operational cost, skipping structural QA introduces a different class of risk, one that becomes visible only after deployment.
When annotation QA automation is absent or underdeveloped, organizations face:
- Increased model retraining cycles
- Escalating dataset correction costs
- Production instability under distribution shift
- Safety and compliance exposure
- Long-term technical debt
The financial impact is rarely immediate. It accumulates.
For example:
In robotics dataset annotation, minor inconsistencies in obstacle detection training data can lead to unpredictable behavior in autonomous systems.
In medical image labeling, segmentation drift can compromise measurement precision in AI-assisted diagnostics.
In geospatial image annotation, small boundary inconsistencies may distort large-scale mapping outputs.
In industrial automation dataset preparation, bounding box misalignment can reduce reliability in real-time conveyor belt object detection data.
What begins as a labeling shortcut becomes a production liability.
Financial and Operational Impact of Skipping QA
| Risk Category | Short-Term Effect | Long-Term Consequence |
|---|---|---|
| Model Stability | Slight accuracy fluctuation | Deployment instability |
| Retraining Cost | Additional fine-tuning cycles | Escalating infrastructure cost |
| Dataset Consistency | Minor annotation drift | Compounded structural bias |
| Compliance | Undetected edge-case gaps | Regulatory exposure |
| Brand Trust | Temporary performance issue | Loss of customer confidence |
| Technical Debt | Patch-based fixes | Architecture redesign |
Organizations that treat QA as optional often discover that correction after deployment is significantly more expensive than structural validation during dataset creation.
In enterprise data annotation platforms, QA maturity directly correlates with production resilience.
Automation saves time. Structural QA saves systems.
The Future of Annotation
Auto-annotation tools, AI-powered labeling software, and scalable annotation workflows have permanently changed how data annotation for machine learning operates. But the competitive advantage is no longer speed alone. It is structural reliability.
Different stakeholders in the ecosystem must adapt accordingly.
For Data Annotation Startups
If you are building a data annotation startup or launching a new data labeling platform, competing on volume or pricing alone is no longer sustainable.
Modern differentiation comes from:
- Annotation QA automation embedded into the dataset annotation tool
- Cross-dataset consistency enforcement
- Scalable annotation workflows with validation layers
- Integrated dataset management platform capabilities
Speed attracts customers.
Structural QA retains them.
For Dataset Labeling Companies
Traditional data labeling outsourcing models focused on workforce scale. Today, dataset labeling companies must evolve into AI-accelerated annotation service providers.
That means:
- Combining auto-annotation tools with human-in-the-loop annotation platforms
- Embedding validation logic inside machine learning data labeling pipelines
- Offering computer vision annotation services supported by a QA infrastructure
- Delivering not just labeled data, but structurally validated training data
Clients are no longer buying boxes and masks.
They are buying reliability.
For Enterprises Building AI Products
Enterprises deploying computer vision ML data into production must treat annotation as infrastructure, not as a preprocessing step.
Production stability depends on:
- Dataset-level validation, not just mAP scores
- Drift monitoring across environments
- Rare-class verification
- Ontology governance inside enterprise data annotation platforms
- Continuous feedback loops between model performance and dataset refinement
The cost of poor annotation is rarely visible during validation.
It becomes visible in production.
For AI Product Teams and Computer Vision Services Companies
For teams building robotics systems, medical imaging annotation pipelines, geospatial image annotation platforms, or industrial automation dataset preparation workflows, annotation QA automation must be treated as a core system layer.
In robotics dataset annotation, minor inconsistencies affect obstacle detection training data and path planning stability.
In medical image labeling, boundary drift impacts diagnostic model confidence.
In geospatial labeling services, small polygon misalignment scales into mapping inaccuracies.
In industrial robot vision labeling, bounding box inconsistency reduces deployment reliability.
Automation scales data.
QA scales trust.
System-Level Implications of Automation
Foundation models such as SAM and modern detection architectures have transformed data labeling for machine learning. Auto annotation tools can now generate massive volumes of training data through AI-powered labeling software and CV labeling automation.
However, as automation scales, so does systemic risk.
The future of data annotation is not about removing human oversight. It is about embedding structural QA directly into the annotation pipeline automation to ensure dataset integrity at scale.
Modern data labeling platforms such as Unitlab reflect this shift by combining auto-annotation capabilities with integrated validation workflows and annotation QA automation. The goal is not just faster labeling — but structurally reliable training data.
Organizations that recognize this transition will build more resilient AI systems. Those who rely solely on visually convincing automation may discover that speed alone does not translate into production readiness.
Conclusion
Foundation models such as SAM and modern detection architectures like YOLO have permanently changed the speed and scale of data annotation. Auto annotation tools can now generate massive volumes of training data in minutes.
But production AI systems are not evaluated by speed. They are evaluated by reliability.
Foundation models optimize prediction patterns — not dataset structure. Without structural quality assurance, small semantic errors, boundary inconsistencies, and rare-class gaps can silently scale across annotation workflows and surface only in production.
Automation increases throughput. Quality assurance safeguards integrity.
In the era of foundation models, the real competitive advantage is not how fast data is labeled — it is how confidently that data can be trusted.
References
- Awais et al. Foundational Models Defining a New Era in Vision: A Survey and Outlook.
- Ahmadzadeha et al. A Guide for Manual Annotation of Scientific Imagery: How to Prepare for Large Projects.
- Jeong et al. WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation.
- Ahmed E et al. Rethinking Software Engineering in the Foundation Model Era: A Curated Catalogue of Challenges in the Development of Trustworthy FMware.
- Emam et al. On The State of Data in Computer Vision: Human Annotations Remain Indispensable for Developing Deep Learning Models.
- Zhang et al. MAGICBRUSH: A Manually Annotated Dataset for Instruction-Guided Image Editing.
- Kumar et al. Object Detection in Adverse Weather for Autonomous Driving through Data Merging and YOLOv8.

