
Many modern tech buzzwords, AI, ML, Deep Learning, Computer Vision, Cloud, Big Data, Blockchain, get tossed around so often that people sometimes apply them to tasks that aren’t actually related (for instance, combining statistics with ML doesn’t automatically make it AI).
This overuse in media and everyday conversation can lead to misunderstandings about what these terms really mean. One such term we’ll examine here is data annotator, also known as data labeler.
Most people are aware that data annotators contribute to AI/ML work, particularly by preparing the training and testing datasets used by data scientists and ML engineers. However, that’s not all data labelers actually do. Within the broader AI domain, data annotation is a fundamental component that supports the advancement of AI technologies and applications.

In this post, we’ll take a closer look at data annotation, focusing on its importance and role in artificial intelligence. By the end, you’ll understand:
- What data annotation is
- Why it matters
- Different types of data labeling
- Key responsibilities and skills required of data labelers
- Career prospects in this field
Let’s get started!
What is Data Annotation?
According to Wikipedia:
Data annotation is the process of labeling or tagging relevant metadata within a dataset to enable machines to interpret the data accurately. The dataset can take various forms, including images, audio files, video footage, or text.
Essentially, data labeling helps machines learn from whatever dataset they’re given and identify which patterns exist. Because raw data frequently appears in semi-structured or unstructured forms (emails, text, images, audio, video) computers can’t interpret it without being guided by a specific structure.
Raw data, on its own, isn’t all that useful until it’s organized to meet a particular goal, which turns it into actionable information. Therefore, data labeling involves adding tags or metadata to large volumes of unorganized data, making them machine-ready for analysis and usage. The annotation process also includes quality assurance measures to ensure the reliability of the labeled data.
The people who handle this task are known as data annotators. Various annotation techniques, such as bounding boxes, segmentation, and text classification, are used to ensure the data is properly organized and labeled for machine learning applications.
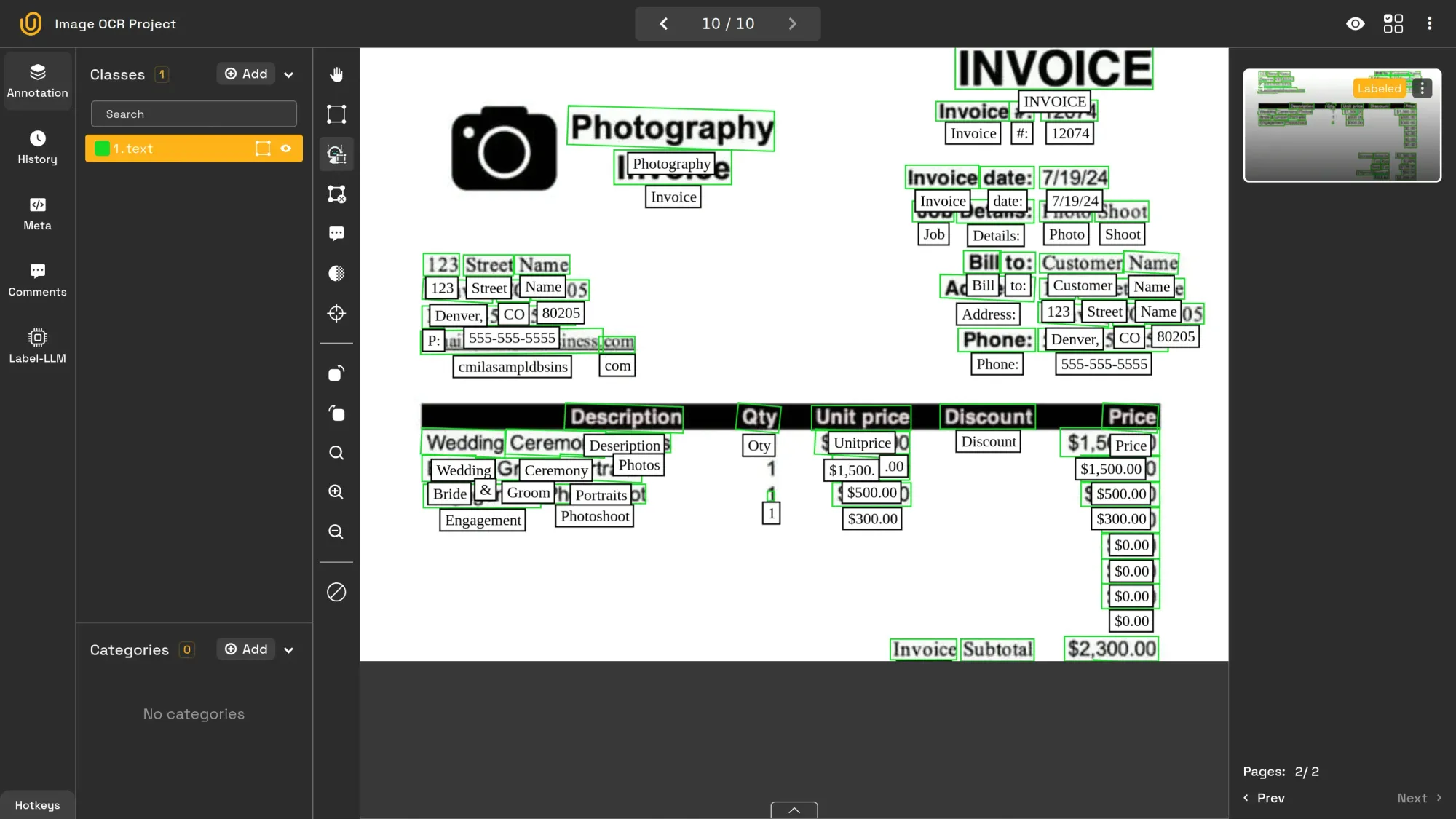
For example, below is the process of adding bounding boxes to an image to specify the locations of the cars:
Data Annotator Labeling Cars | Unitlab Annotate
Although it’s most often associated with AI/ML, data annotation has wide-ranging applications across many industries. Any company that depends on data for insights and decision-making typically engages in some form of labeling, whether or not they explicitly refer to it as “data annotation.”
For example, imagine a large clothing retailer with a massive inventory. To keep its warehouse efficient and make searches easier, it might add specific metadata:
- Fabric type ("cotton", "polymer")
- Specific style ("bohemian," "athletic")
- Target demographic ("teen," "adult")
Categorizing data in this way helps improve search functionality and inventory management, ensuring that products are easily found and organized.
Still, it’s in AI/ML where data annotation truly shines. These models are advanced programs designed to understand, interpret, and learn from data so they can act on it later.
Because they rely on high-quality information, labeling these datasets becomes a critical step. To develop AI/ML systems that can solve real-world problems, you generally need large quantities of diverse, accurately labeled data.
Why Does Data Annotation Matter?
In short, data annotation matters because AI itself matters. Most of us interact with AI/ML products daily with ChatGPT and Gemini being two well-known examples. Other popular services, like Google Translate and Apple Maps, are also specialized ML models. AI and machine learning have broken out of their niche and now significantly influence everything from self-driving cars and medical diagnostics to virtual assistants and social media analytics.
Since AI/ML systems depend on large, high quality data and high quality training data, data annotation is vital for ensuring these systems work properly. High quality annotated data is essential for effective model training, as the quality of any AI model or AI system can’t exceed that of the training data it’s trained on.
This illustrates the well-known principle of “garbage in, garbage out”. Data annotation is important for AI and machine learning because it enables models to accurately learn from raw data, ensuring reliable performance across various applications.
Types of Data Annotation
Comprehensive data annotation is essential across industries such as autonomous vehicles, finance, social media, and manufacturing, as it provides the detailed and accurate labeling needed for effective AI and machine learning model development.
Most data is unstructured and requires labeling to become useful; that is, to become something machines can parse effectively. The data annotation process involves applying various data annotation techniques, which are chosen based on the type of data and the specific requirements of the AI model.
Many organizations rely on annotation services to obtain high-quality labeled data for training their machine learning models. Below are the primary types of data labeling:
Image Annotation
Also referred to as image labeling, this task involves marking important objects in images, typically supporting computer vision models. These models digest visual data for applications such as self-driving cars, facial recognition systems, medical imaging, and medical images like X-rays and CT scans.
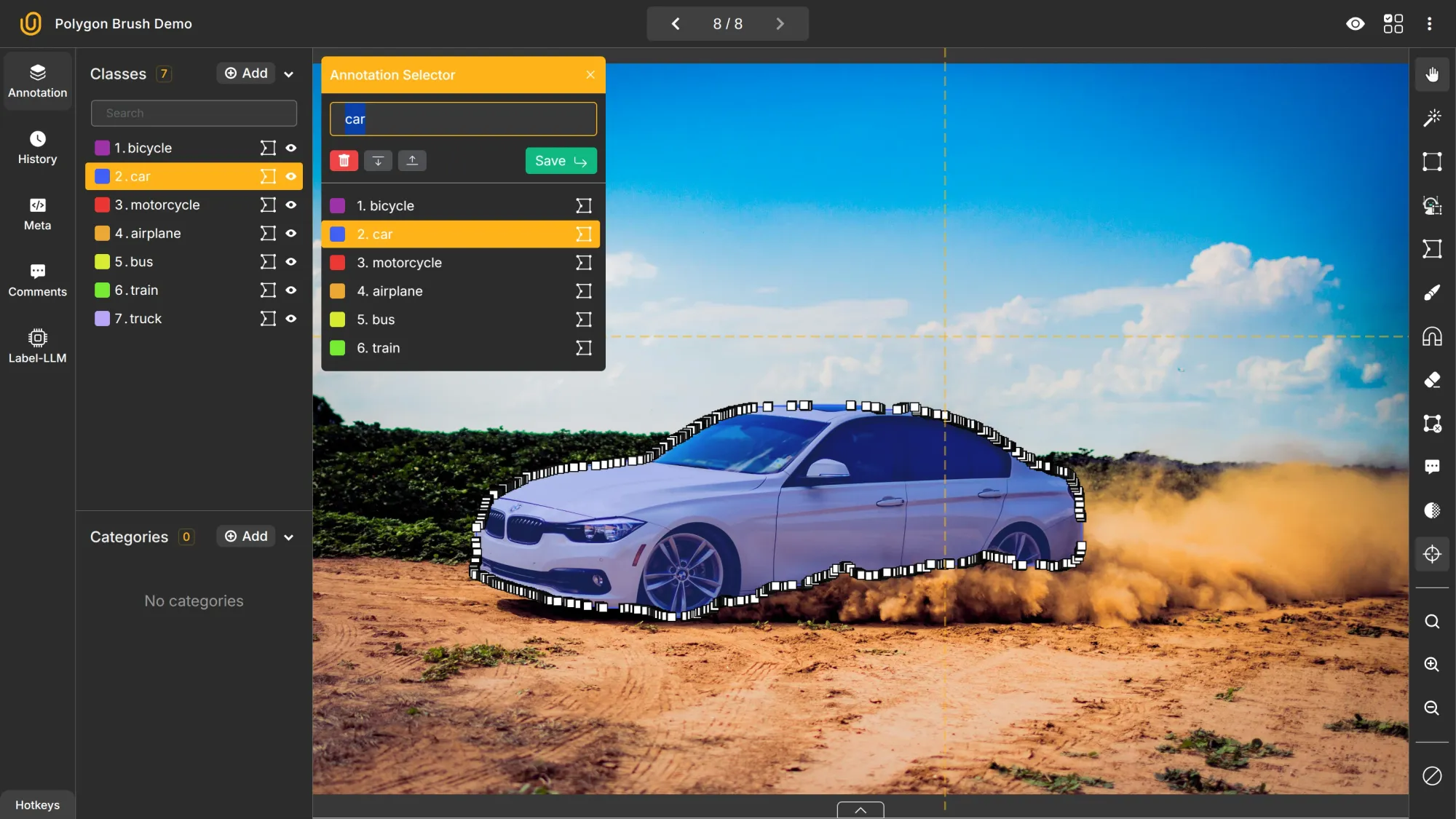
Object Detection and Classification
You might be tasked with identifying, classifying, and drawing bounding boxes around objects of interest, like vehicles, pedestrians, or road signs in the case of the smart street systems.
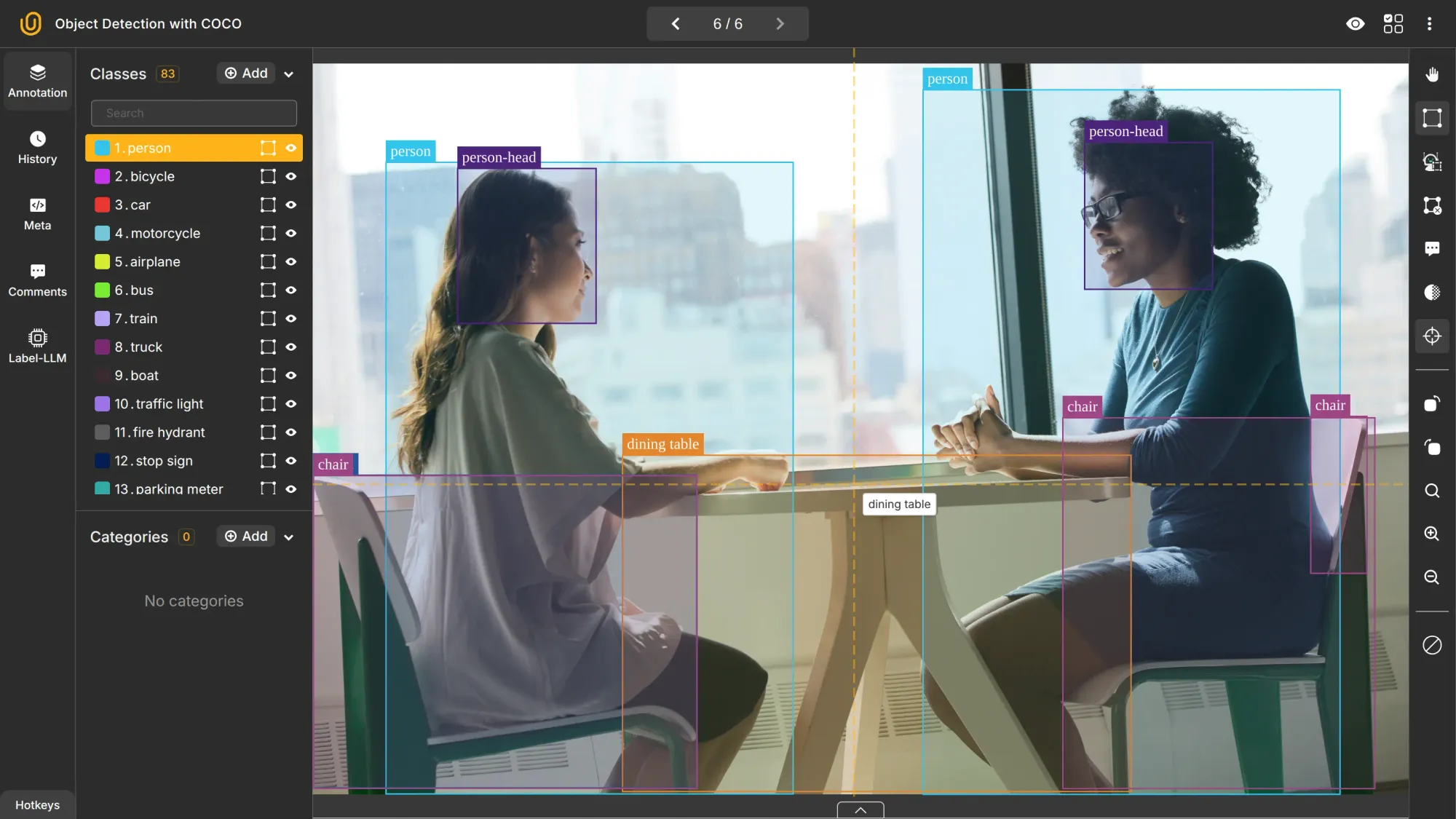
Segmentation
Segmentation means labeling each pixel to define object boundaries and backgrounds more precisely. It’s also often called pixel-perfect labeling because it offers far greater detail than basic object detection.
OCR
OCR (Optical Character Recognition) converts images of text into machine-readable text. This task involves identifying and labeling text within images, a process done by any software that can parse images.
Text Annotation
Text labeling concerns labeling or tagging written content (sentences, paragraphs, or entire documents) to train NLP (Natural Language Processing) models. Text annotation is applied to textual data for various NLP applications. It powers chatbots like ChatGPT, along with translation tools and voice assistants.
Text Classification
Text classification (also known as categorization) involves sorting text into specified groups. For instance, you might label an email as spam or a legitimate promotional message. It can be a simple yes/no answer as well.
Text classification (also known as categorization) involves sorting text into specified groups. For instance, you might label an email as spam or a legitimate promotional message. It can be a simple yes/no answer as well.
Another type is intent annotation. It is a specialized text classification task that labels data to identify the true intent behind user responses, which is crucial for understanding user intent in customer service and other NLP applications.
Named Entity Recognition
This process involves identifying and labeling entities, such as people, places, dates, or organizations. It’s also called text entity detection. Entity annotation is a method used here to identify and categorize named entities within unstructured data.

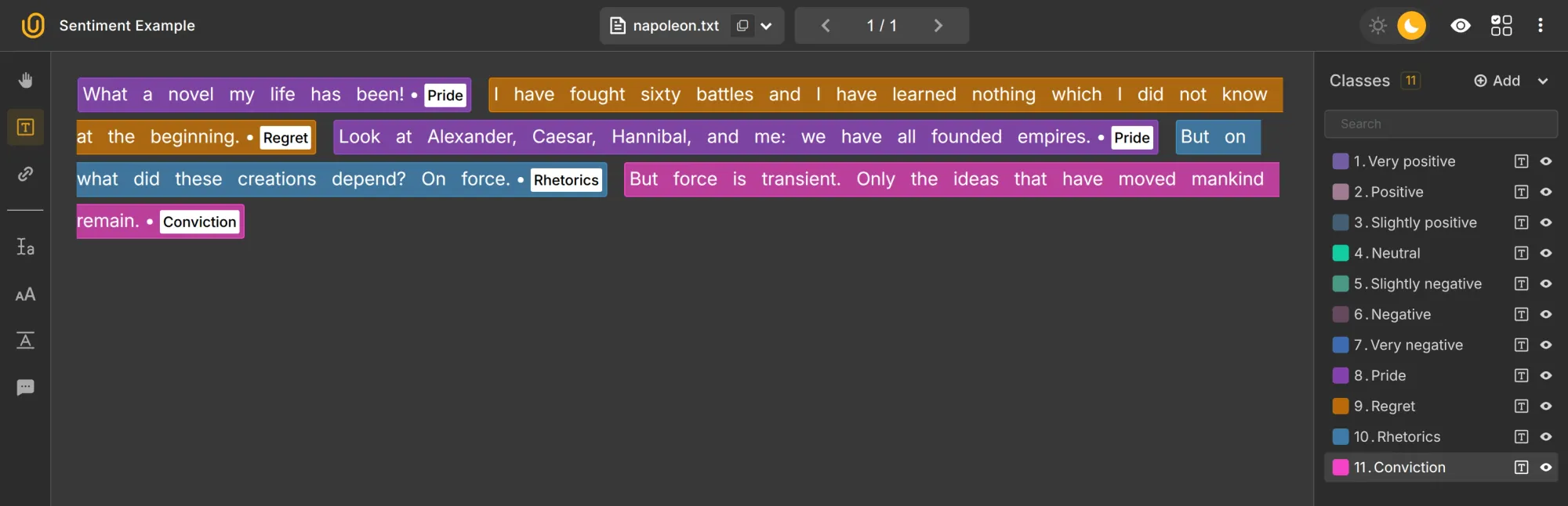
Sentiment Analysis
Here, you analyze the emotional tone of the text, whether it’s positive, negative, or neutral. It’s widely used in social media monitoring, brand management, and content moderation. This mode is considered the most difficult, and ML models heavily rely on human-labeled datasets and human assistance.
Human-annotated data is especially important for capturing nuances like sarcasm or humor. In the realm as complex and nuanced as human emotions, machines have a hard time differentiating emotions and intent: is the text a sarcasm, joke, or genuine expression?
Audio Annotation
Audio annotation involves labeling audio data and speech data for machine learning applications. This process requires listening to recordings and adding suitable metadata to help machines process them accurately.
Audio Classification
Similar to text classification, audio classification groups sound clips into specific categories: “country music,” “waves crashing,” or “busy street chatter,” for example. You might also label the emotional tone or main topic of the audio. Annotating audio data in this way enables machine learning models to recognize and process different sound types effectively.
Transcription
Transcription, specifically speech transcription, involves converting spoken words into text, often with timestamps. Speech transcription is a key task for training speech recognition models and other related applications. Many streaming and video platforms (e.g., YouTube) use AI-driven transcription models trained on massive datasets.
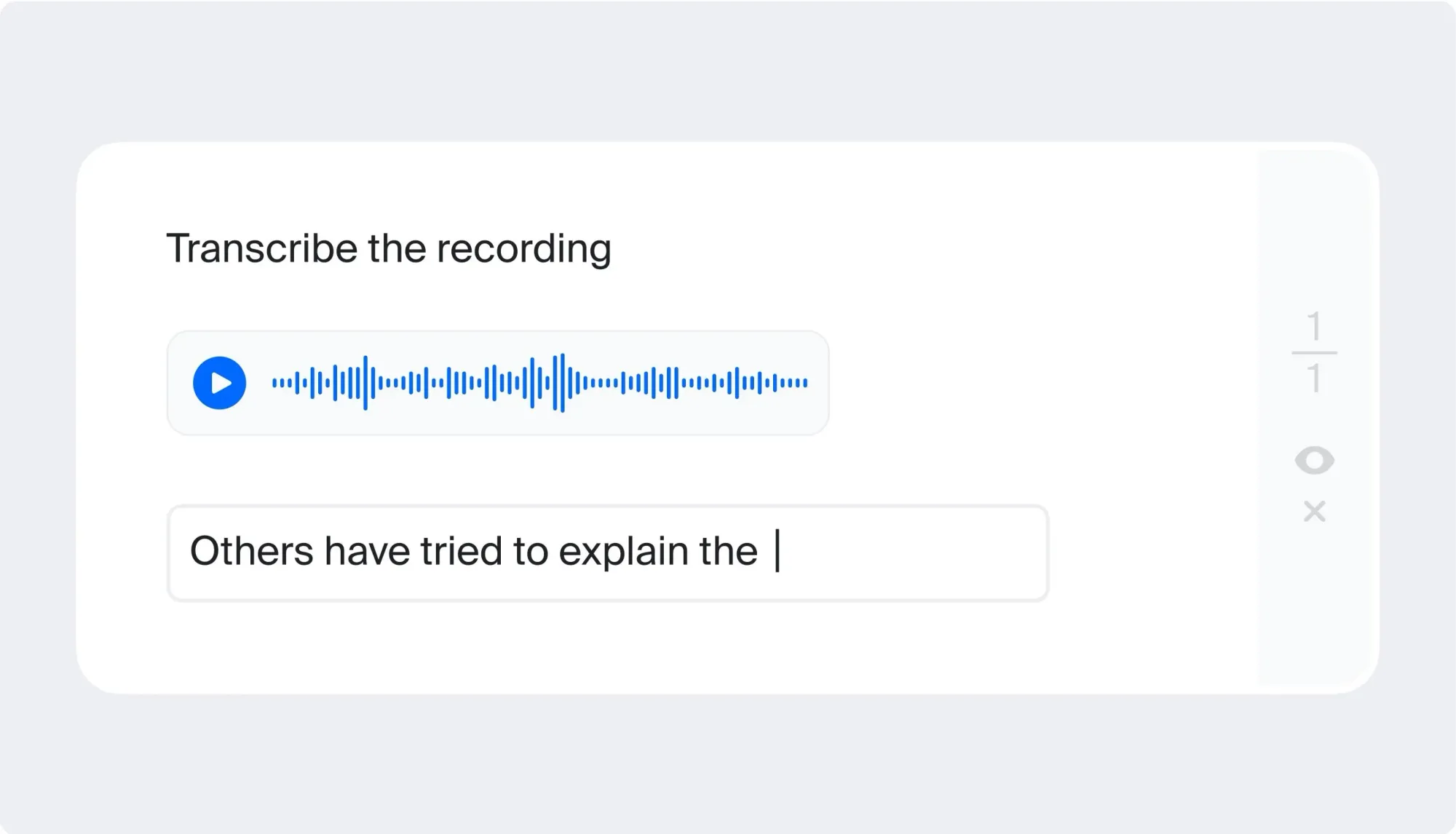
Acoustic Event Detection
Also known as audio segmentation. To separate different sounds, distinct speakers, music, or background noise, ML models rely on well-labeled audio sets. As an annotator, you identify each audio event, allowing the model to focus or filter out those sounds as needed.
Video Annotation
Video Classification
In this process, you might watch whole videos and categorize them: for instance, deciding whether they’re suitable for children, ads, sports highlights, wildlife documentaries, science clips, or adult content with violence or drug use.
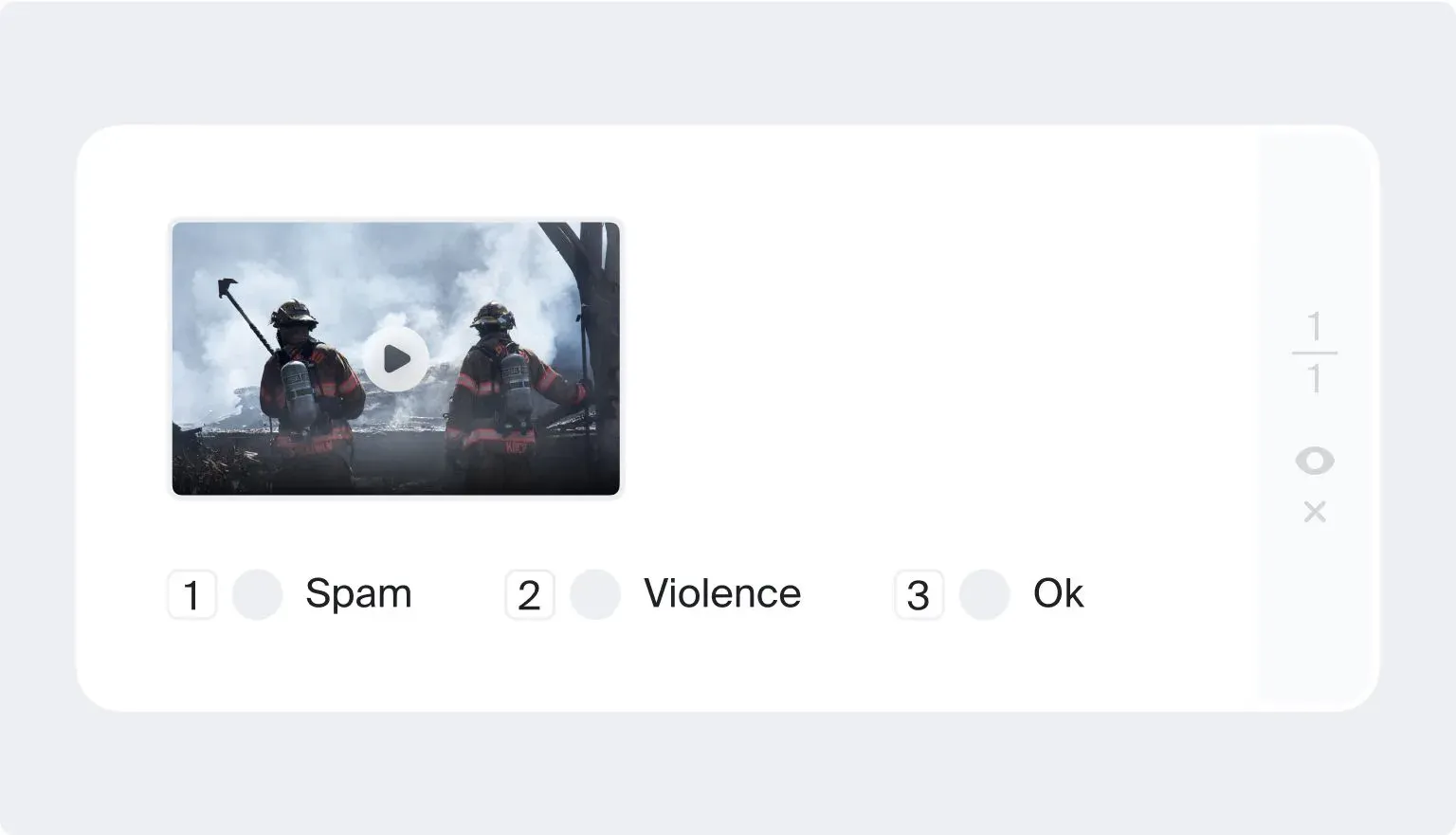
Object Tracking
Here, you follow an object (such as a person or vehicle) throughout a video by drawing bounding boxes in key frames.
Now that we have a pretty good understand of what data annotation is, let's see what is expected of data labellers in the job.
Key Responsibilities
Labeling and Tagging
As a data annotator, your main task is to label raw data. Simple as that.
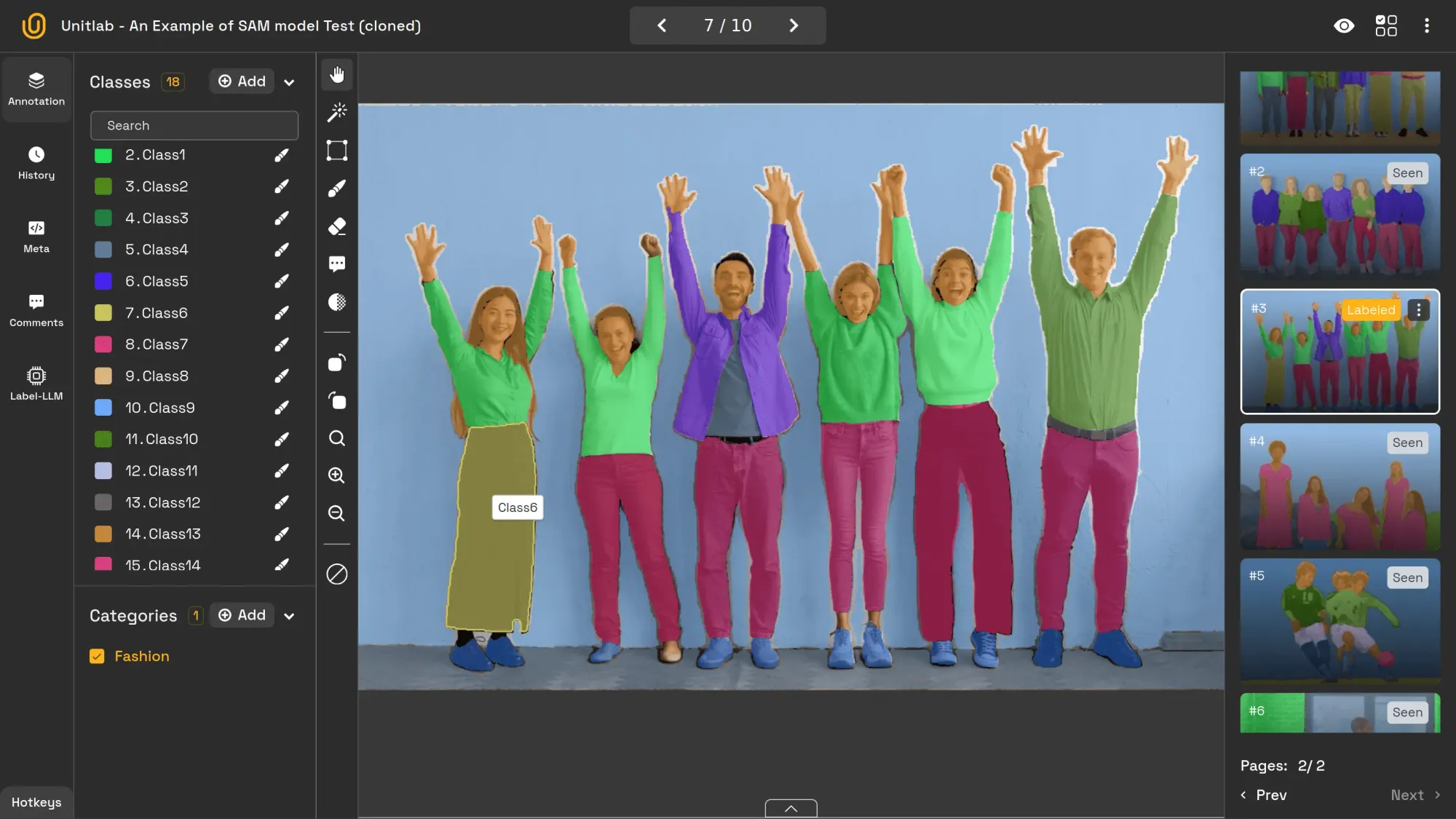
For the sake of simplicity, let's consider you are now labeling images. With images, you might draw bounding boxes or use segmentation with an image labeling tool. You might use different tools or workflows.
However, your goal is clear and concise: create well-annotated data of high quality with efficiency.
Hybrid Approach to Image Skeleton | Unitlab Annotate
Quality Assurance and Guidelines
There exist auto-annotation tools and models that can label raw data automatically, usually in a fraction of the time necessary by human professionals. Still, human data annotators are superior because they produce the highest quality datasets. As a data annotator, your highest responsibility is to beat the machine in terms of labeled dataset quality in a reasonable time.
This includes checking your annotated data for accuracy and resolving labeling conflicts and ambiguities, often collaborating with other image labelers and data analysts. You are expected to follow annotation guidelines to maintain uniformity across the labeled dataset.
Collaboration, Iteration, Feedback
Data annotation is part of the major pipeline that involves project managers, domain experts, ML engineers, and data reviewers. You’ll collaborate with others to clear up ambiguities (such as whether an object is too shadowed to be labeled properly) and make sure the labeling remains uniform across the entire dataset.
Guidelines sometimes change in real-world projects, so it’s normal to adjust as you go labeling. You collaborate with others to get feedback on your work. You iterate this cycle many times throughout the data labeling project.
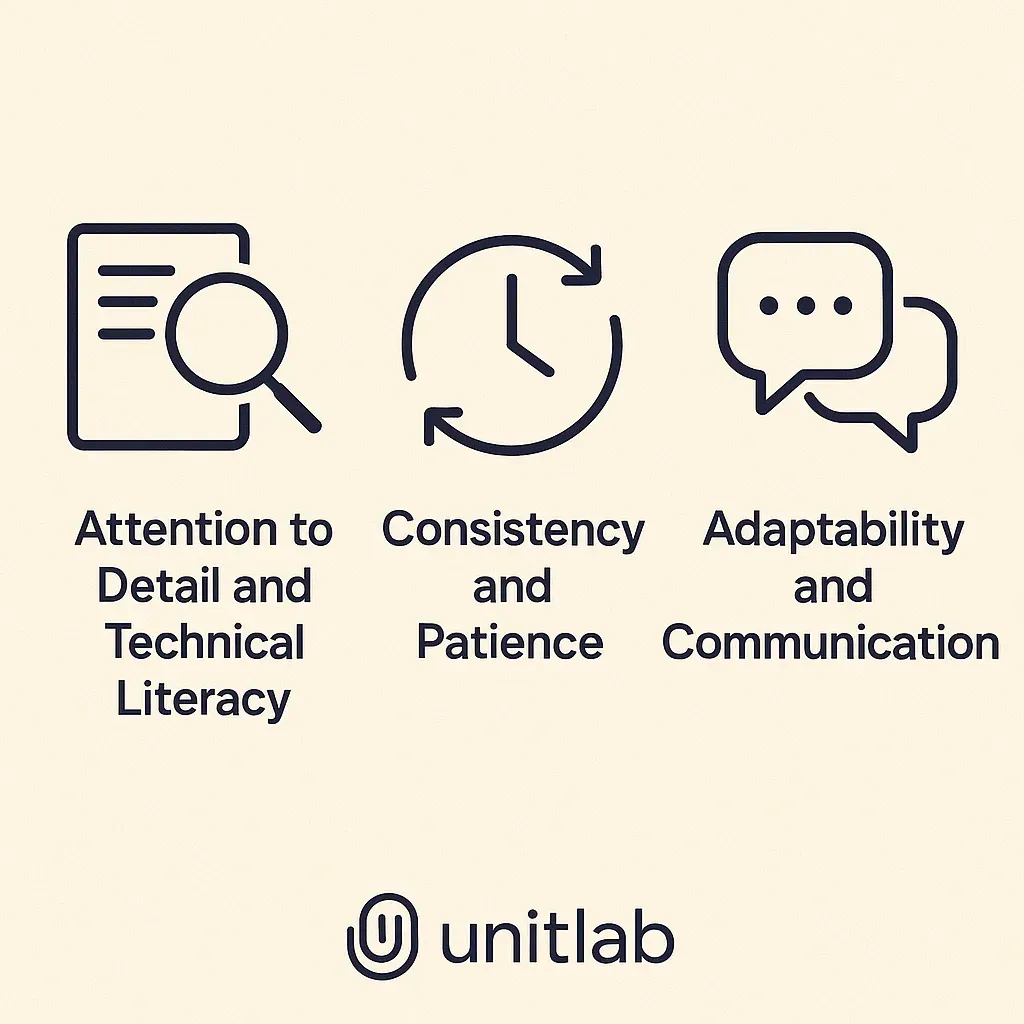
Essential Skills and Qualities
Attention to Detail and Technical Literacy
Accuracy is the foundation of good labeling. Humans still outshine automated methods when it comes to catching subtle, contextual details. You will likely use some data labeling tools or even rely on a specialized data labeling service in your job, so basic technical competence is a must.
Accuracy is the foundation of good labeling. Humans still outshine automated methods when it comes to catching subtle, contextual details. You will likely use some data labeling tools or even rely on a specialized data labeling service in your job, so basic technical competence is a must.
Consistency and Patience
Data labeling is repetitive, often done remotely, so you need discipline to maintain high standards, even when you’re dealing with thousands of near-identical data points. The sheer volume of the task makes the job repetitive and boring, which likely hinders your performance.
In this environment, you may lose focus and attention - the most valuable asset in your job. Therefore, it is a very big plus if you have patience to deal with repetitive tasks.
Adaptability and Communication
Because guidelines, best practices, and even project goals can shift over time, adaptability is the key. Strong communication with coworkers, managers, and domain experts ensures labeling remains consistent and accurate, two traits that contribute to the success of AI/ML datasets most.
Common Tools and Platforms
Data annotators, whether they’re freelancers or part of an in-house data labeling team, generally use special platforms, along with standard business tools for group communication.
Labeling Platforms
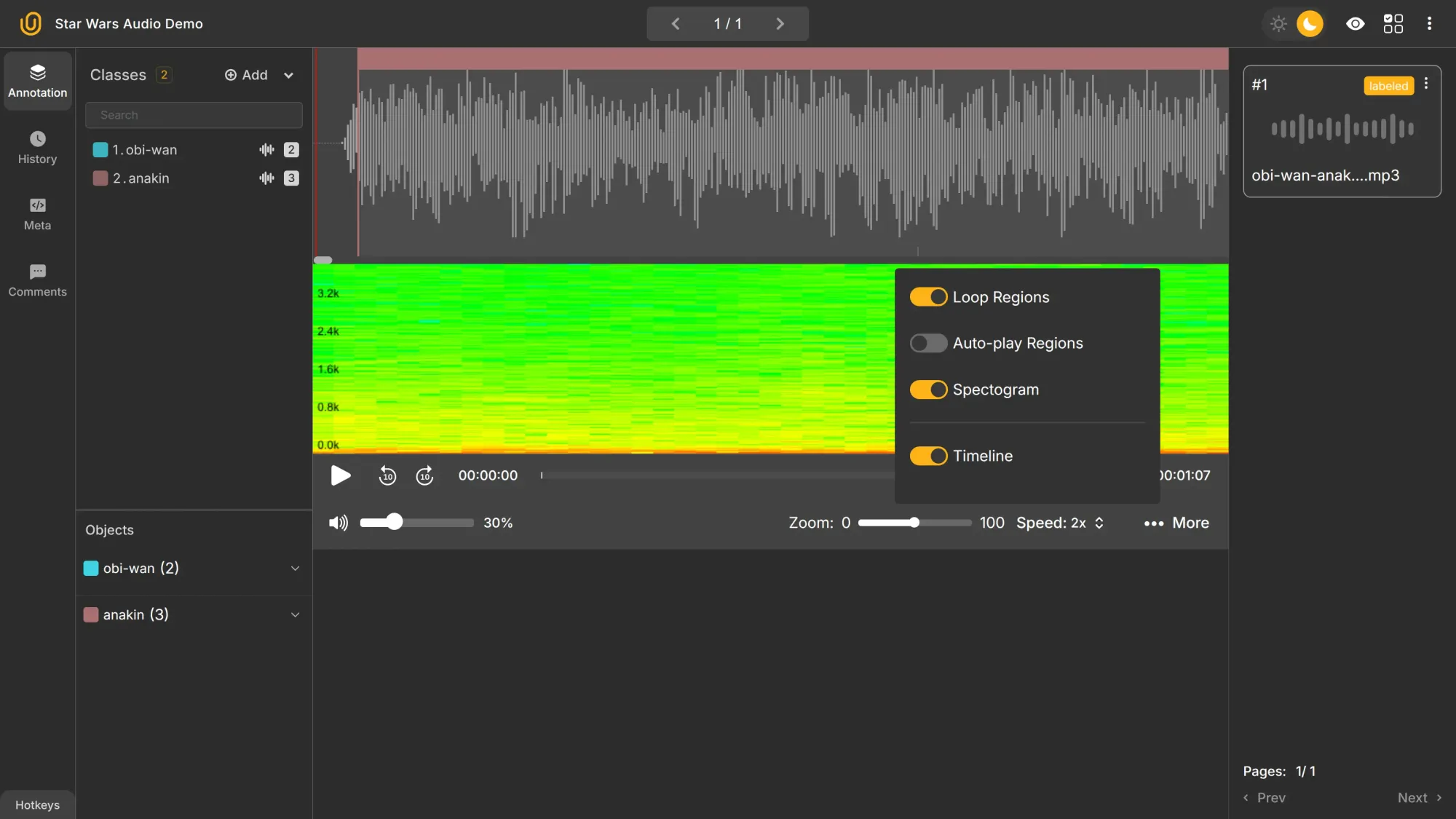
At this stage of tech, data annotation platforms reign supreme. Data annotation tools are essential software that enable efficient and accurate labeling and categorization of datasets. You will likely use different platforms for different data types or projects.
- Freelancers often switch between image labeling service software, such as Unitlab Annotate or Roboflow Annotate, as each client usually has a different system.
- Crowdsourcing platforms like Toloka or Amazon Mechanical Turk provide their own interfaces for labeling.
- In-house teams typically rely on a single, possibly custom-built data annotation solution; thus, data labelers become more efficient over time.
Business Tools
Like most contemporary roles, a data annotator also uses tools such as email, Slack, and Microsoft Teams for business communication. In this job, communication is the key due to large-scale projects with evolving requirements.
Career Prospects
Historically, AI/ML engineers and data scientists used to perform data annotation for their research projects, as large-scale, commercial models were not there yet. Therefore, formal “data annotator job” positions are fairly new in our economy. Many data labelers still work on a freelance basis.
The data annotator job is now recognized as a key entry point into the field of AI, offering opportunities to work on a wide range of ai projects. Data annotators can contribute to speech, image, and text data annotation, gaining hands-on experience and developing valuable skills for future roles in AI and machine learning.
There is no formal statistics about this relatively new role from organizations like the U.S. Bureau of Labor Statistics. However, as AI grows, data annotation is going to grow alongside.
Consequently, there is no formal salary statistics, but you may earn as much as $20/hour on certain online platforms, such as datannotation.tech, with actual rates depending on location, project complexity, and specific domain knowledge (e.g., healthcare or finance).
Career Growth
As AI continues to expand across various industries, the need for high-quality labeled data is most likely to keep rising. Exact figures are limited, but skilled data annotators should find regular opportunities with relative ease.
Data annotators can also explore other related areas:
Entry Point into AI
Working as a data annotator gives you firsthand experience with how machine learning models learn, possibly paving the way for more advanced roles in data or AI.
Quality Assurance and Lead Roles
With enough practice, data labelers can transition into managerial or reviewer positions, overseeing entire annotation teams, data labeling tools, and workflows.
High Demand Across Industries
AI is everywhere (in self-driving technology, healthcare diagnostics, finance, and legal fields) leading to a strong need for domain experts who also understand labeling at a high level. Finding jobs is no issue for experienced labelers.
Conclusion
Essentially, data annotation is about tagging or labeling raw data, transforming it into a structured format that’s actually useful for analysis or training. While this idea applies to many fields, it’s especially critical in AI/ML, where data labeling directly influences model performance.
Since data can be text, images, audio, or video, approaches to annotation will vary, yet the end goal, supplying reliable, organized data, stays the same.
Most data annotators work remotely, labeling data while adhering to consistent guidelines, collaborating with colleagues, and applying feedback. Though data annotation hasn’t always been recognized as a full-fledged career path, the growth of AI/ML is creating a stronger demand for these skills.
Over time, a data annotator can advance into other AI-related roles or project management. If you bring specialized expertise in medicine, finance, or another domain, combining that knowledge with annotation skills can make you exceptionally valuable.
Explore More
For further information on data annotation, check out these posts:
- Four Essential Aspects of Data Annotation [2026]: A helpful overview of the key pillars that define effective annotation processes.
- Data annotation: Types, Methods, Use Cases.: A deeper dive into various annotation methodologies, complete with real-world applications.
- Unitlab Annotate - Data Annotation Platform for Computer Vision: Learn how Unitlab Annotate streamlines the data labeling process for computer vision projects.

