Computer vision (CV) is a fascinating branch of computer science and AI that revolves around giving machines the ability to “see” and interpret the world the way humans do. While we often hear about CV’s use in cutting-edge applications, many people new to the field want to know the basics: What is computer vision, and why does it matter?
By the end of this post, you will have learned:
- What computer vision is
- How CV and AI differ and complement each other
- How CV works
- Common types of CV
- Real-world use cases
- Challenges and solutions in CV
What is Computer Vision?
Computer vision involves the techniques and technologies that enable machines to interpret visual information, images, videos, and even real-time streams, and to use this understanding to perform tasks that once required human involvement. Essentially, it’s the process of developing algorithms and models that extract information from visual data.
Traditionally, computers have replaced many forms of manual labor. With computer vision, they’re now taking on repetitive or time-consuming visual tasks, from image data annotation for AI models to advanced image labeling for manufacturing. These tasks don’t necessarily replace human expertise; they enhance it by freeing us to focus on more nuanced decision-making.
CV is not AI
Computer vision and AI are closely related but not the same. AI is a broad field focused on creating machines that “think” in ways analogous to humans. It encompasses sub-fields like machine learning (ML), natural language processing (NLP), and of course, computer vision.
CV is more specific in its focus. It focuses on interpreting visual data and generating outputs (like identifying objects in a photo) that AI can then use for decisions. In other words, computer vision gives AI its “eyes.”
How CV and AI Work Together
Because AI doesn’t perceive the world as humans do, it needs an interface to convert raw pixels into machine-readable data. That’s where computer vision comes in. For example, home security cameras can automatically detect people, animals, and vehicles because CV transforms the camera feed into a digital format, and a trained AI model then recognizes and classifies what it sees.
Other Examples
- Healthcare: CV scans medical images (like X-rays) to spot anomalies, while AI weighs those findings against a patient’s history.
- Retail: CV tracks items that customers pick up in cashier-less stores, while AI manages billing, updates inventory in real time, and handles AI datasets that keep the system’s accuracy high.
How CV works
When discussing “how CV works,” we typically refer to the steps involved in creating models that can detect, classify, or label objects. Below is a four-step high-level overview, which can change depending on the specific use case:
Step 1: Data Acquisition
First, define the model’s purpose. Are we detecting cars on a busy street, aiding in medical diagnosis, or managing items in a warehouse? This is also where dataset management comes into play. Collecting relevant visuals, whether that’s a massive set of city street photos for a self-driving car project or thousands of medical scans for research, is the key.
Therefore, the process begins with collecting visual data (images or videos) from cameras, sensors, or other devices. We want to gather as many relevant visual data as possible. Essentially, a CV model learns patterns: as it sees more and more visual data, its patterns become stronger, after which it can apply its patterns to the new visual data.
After collection, data is split into training and testing sets. A common approach is an 80/20 split, but this may vary depending on the model. Effective dataset version control helps keep track of changes to your images and labels and controls versioning as the project evolves.
Step 2: Data Annotation
Once we gather the relevant data, we need to teach our visual AI/ML models by using annotated datasets. Data annotation involves labeling the important information or metadata in the dataset so the model knows what appears in our images and videos. Essentially, it’s all about identifying and marking the elements of an image (or video) in a way our computer vision model can understand.
In a home security setting, for example, an AI model is trained on a large annotated dataset to detect and classify objects in different scenarios. Human labelers go through images and videos to mark what constitutes a human, animal, or vehicle. With enough labeled examples, the AI extracts patterns and learns to recognize and categorize objects with increasing accuracy.
This step is considered the hardest phase in building visual AI models because there are many moving parts and constraints. Creating accurate computer vision models demands large, consistent, and precisely annotated datasets.
While manually labeling thousands of images is effective, it’s also time-consuming and costly. Meanwhile, auto-annotation tools are more cost-efficient but can be less reliable in certain cases. To make this phase as effective as possible, it’s also crucial to implement efficient dataset management, version control, and performance metrics.
Step 3: Model Training
With annotated data in hand, data scientists train a machine learning or deep learning model (often a Convolutional Neural Network) to identify features in the images. The model sees many examples of labeled data and “learns” to generalize. Over time, it adjusts its internal parameters to reliably recognize the objects or patterns you’ve annotated.
Step 4: Inference and Decision-Making
Once trained, the system can infer or make predictions on new, unseen images or video frames. It might locate people and cars on a street or detect an anomaly in an X-ray. This output then feeds into a larger AI system for real-time decision-making: stopping a self-driving car, alerting hospital staff, or updating a warehouse’s inventory system.
Types of Computer Vision Models
Several types of CV models are commonly used:
1. Image Classification
This type of model assigns labels to an entire image. Depending on the image’s content, it may have a single label (e.g., “dog” or “river”) or multiple labels (e.g., “dog,” “river,” and “forest”). An image classification model can even generate descriptive labels such as “a dog running alongside the river in the forest.”

This approach is widely used by social media platforms and search engines to locate relevant digital content, since searching by text is generally more straightforward than searching by image or video.
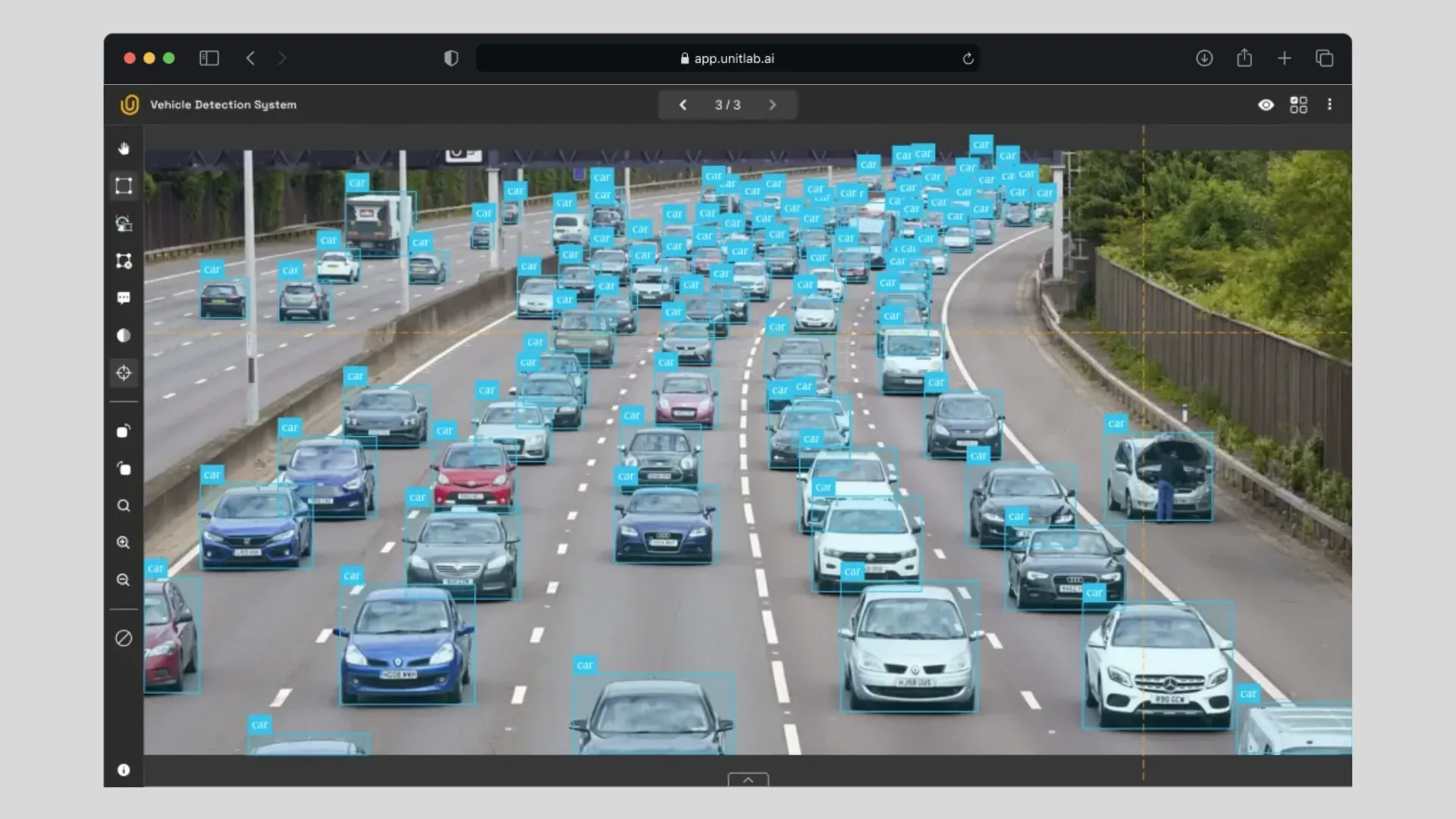
2. Object Detection
Object detection takes classification further by identifying and locating multiple objects within an image. The model draws bounding boxes around each detected object and generates machine-readable coordinates indicating their positions. This type of CV model is both very common and quite popular.
Car Detection with Bounding Boxes | Unitlab Annotate
3. Semantic Segmentation
Semantic segmentation, sometimes referred to as pixel-perfect segmentation, classifies every pixel in the image, providing a detailed and precise understanding of its content. Because each pixel is classified into a specific category, this approach yields highly accurate results. As a result, industries that require extreme precision often use semantic segmentation.
Semantic Fashion Segmentation | Unitlab Annotate
Why not use it for everything then? Semantic segmentation has its drawbacks. It’s difficult to train such models, and they cannot distinguish between separate instances of the same class. For instance, two people in the same image would both be labeled simply as “person,” without differentiation. Moreover, the higher precision may not always justify the higher costs and longer development times.
4. Instance Segmentation
Instance segmentation is essentially a hybrid of object detection and semantic segmentation. Like object detection, it pinpoints individual objects, but instead of placing bounding boxes around them, it outlines the exact edges of each object, much like semantic segmentation.
Car Instance Segmentation with Polygons | Unitlab Annotate
The key difference is that instance segmentation can distinguish among multiple objects of the same type (for example, identifying two separate dogs in one image).
5. Optical Character Recognition (OCR)
OCR is a specialized model designed to scan images and extract text. This allows it to digitize printed documents or even process invoices automatically. A common example is Google Translate: when you scan an image, the software first extracts the text, then translates it into another language.
Fintech OCR Annotation | Unitlab Annotate
Common Applications of CV
1. Autonomous Vehicles
How do self-driving cars actually drive themselves? By “seeing” the road and making decisions based on visual data. Computer vision is critical for these vehicles, helping them detect obstacles, recognize traffic signals, and navigate complex environments safely.
2. Healthcare
In medical imaging, CV analyzes medical images to detect diseases at early stages, examine X-rays, and identify abnormalities. Early detection often leads to more effective treatments and improved patient outcomes.
3. Manufacturing
In manufacturing, computer vision is often employed on production lines. Traditionally, quality control relied on acceptance sampling, a manual, labor-intensive process. By contrast, CV systems continuously inspect products in real time, flagging defective items so that human operators only need to check those specific cases. This approach streamlines the process, reduces overall labor costs, and assures the quality of the production line.
4. Retail
Retail and manufacturing companies frequently need to manage large inventories. AI models that use computer vision for inventory management can significantly assist workers in warehouses and distribution centers. By automating tasks such as product tracking and stock counting, these solutions enhance efficiency and reduce errors.
Challenges
Building and deploying computer vision models successfully presents its own set of challenges—much like any endeavor worth pursuing.
1. Data Quantity and Annotation Quality
The most critical requirement is having a sufficient volume of data and ensuring high-quality annotations. Depending on your AI model’s use case, the required dataset might be relatively small or extremely large. To develop a robust model, it must be trained on various edge cases. In some industries, particularly those dealing with rare diseases, a lack of sufficient data becomes a significant obstacle.
Even if you have an abundant supply of images or videos, annotating them consistently and accurately is often quite challenging due to shifting requirements and constraints. Numerous data annotation platforms are available, and several factors can guide your choice.
In short, training accurate CV models requires large, diverse, and well-annotated datasets. A lack of data or poorly annotated data often results in what we jokingly call Garbage AI.
2. Computational Demands
Like any ML model (especially those leveraging deep learning) CV models are resource-intensive. They typically require powerful GPUs or CPUs to handle the heavy computational load during training.
3. Edge Cases and Complexity
No matter how large or well-annotated your dataset may be, there will always be unexpected or rare scenarios your CV model struggles with, especially in dynamic fields like autonomous driving or medical imaging. This isn’t necessarily a flaw in the model; rather, it reflects the inherent complexity and unpredictability of the real world. Consequently, you should implement systems to handle these edge cases effectively.
Solutions
However, best-practices have been evolving and refining over time.
1. Improved Data Collection and Annotation
Investing in high-quality, diverse datasets can mitigate the first challenge: volume. More data isn’t always better; more diverse data usually is. Therefore, aim for vast and diverse visual datasets.
Because data annotation is still a relatively new industry, there isn’t yet a universally accepted best practice. That’s why many startups are working on providing standardized solutions. However, using auto-annotation with a human in the loop has shown superiority in terms of accuracy, consistency, and efficiency.
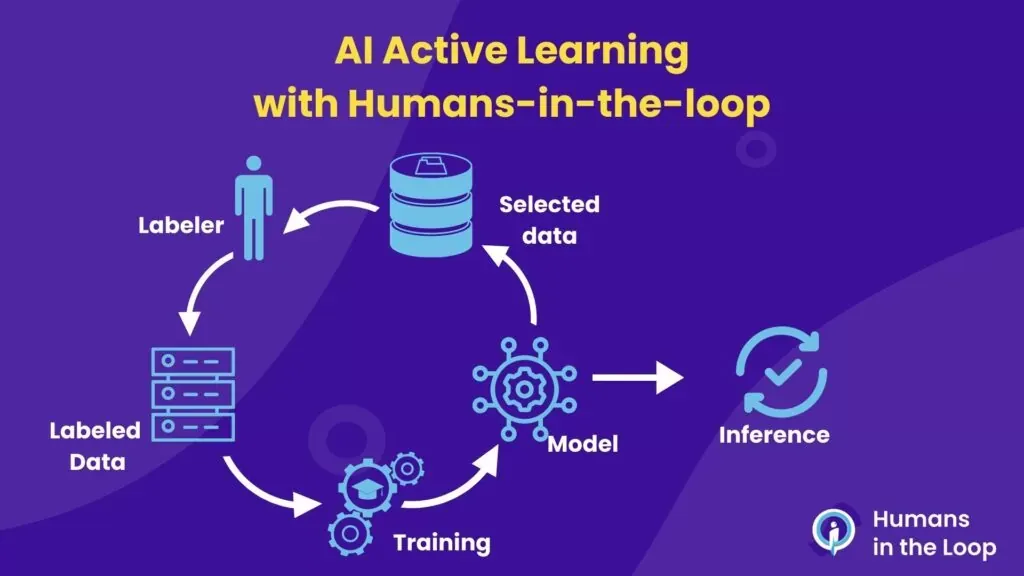
2. Advanced Computing Infrastructure
Cloud-based solutions and edge computing can help address the computational demands of computer vision, enabling faster processing and better scalability. In addition, modern processors are increasingly powerful, making it more feasible to run CV model training and testing in-house.
3. Continuous Learning Models
Because life is filled with complexities and edge cases, one of the best ways to improve AI/ML models is continuous learning. The model is fed more diverse training and testing data over time, allowing it to adapt and become more robust.
Different learning methodologies (deep learning, supervised learning, unsupervised learning) can be employed, but the primary goal is to select the right technique so that the CV model can handle as many real-world scenarios as possible.
Conclusion
At its core, computer vision is a set of techniques that enable machines to “see” and interpret visual data. CV is part of the broader AI field, and they complement each other: computer vision processes visual information and transforms it into a format that AI can use to accomplish specific goals.
A computer vision model, being part of AI, functions similarly to other AI/ML models. However, visual data annotation introduces unique challenges, and numerous startups are working on standardized solutions.
Depending on the industry, there are generally five main types of computer vision, each with its own specific applications:
- Image Classification
- Object Detection
- Semantic Segmentation
- Instance Segmentation
- OCR
CV, especially when powered by AI, has tremendous potential, though it also presents its share of challenges, and possible ways to overcome them.
Explore more:
- 3-step human-in-the-loop data annotation
- Factors in choosing your data annotation platform for AI/ML development
- 7 Ways to Accelerate Your Image Labeling Process
References
- Unitlab Blog
- Unitlab AI
- Wikipedia
- Medium: What is Computer Vision? (History, Applications, Challenges)
- National Library of Medicine: Trade-off between training and testing ratio in machine learning for medical image processing
- Keylabs AI: Overcoming Data Labeling Challenges: Expert Solutions
- Forbes: From Healthcare To Space: Top 10 Transformative Computer Vision Trends In 2024