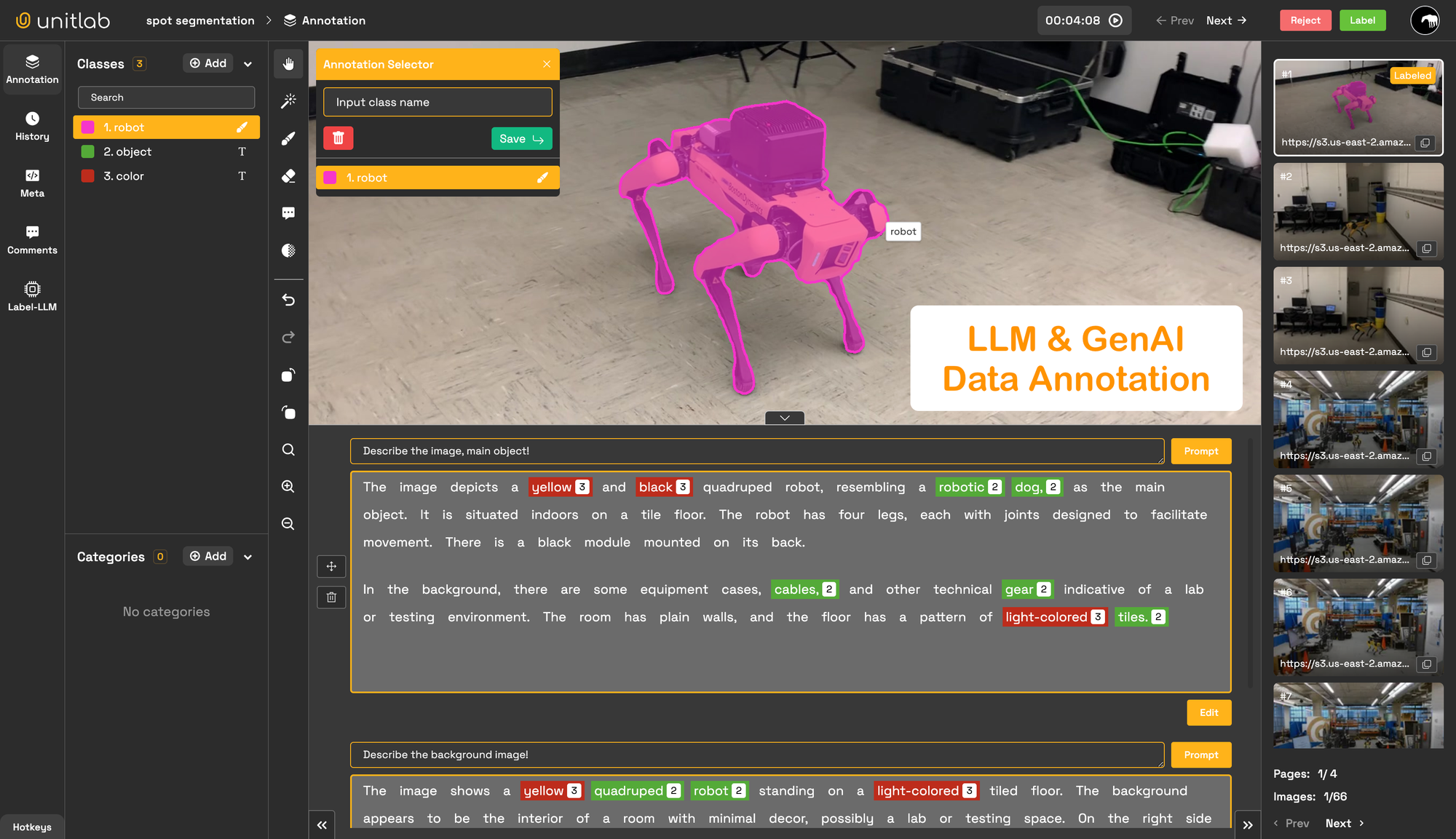
We are excited to announce that you can collect end-to-end training data for your LLMs and GenAI models. Everything is automated, and human-in-the-loop processes ensure high-quality data. Fine-tune your LLMs and GenAI models with custom data that is easily built in Unitlab.
What is LLM?
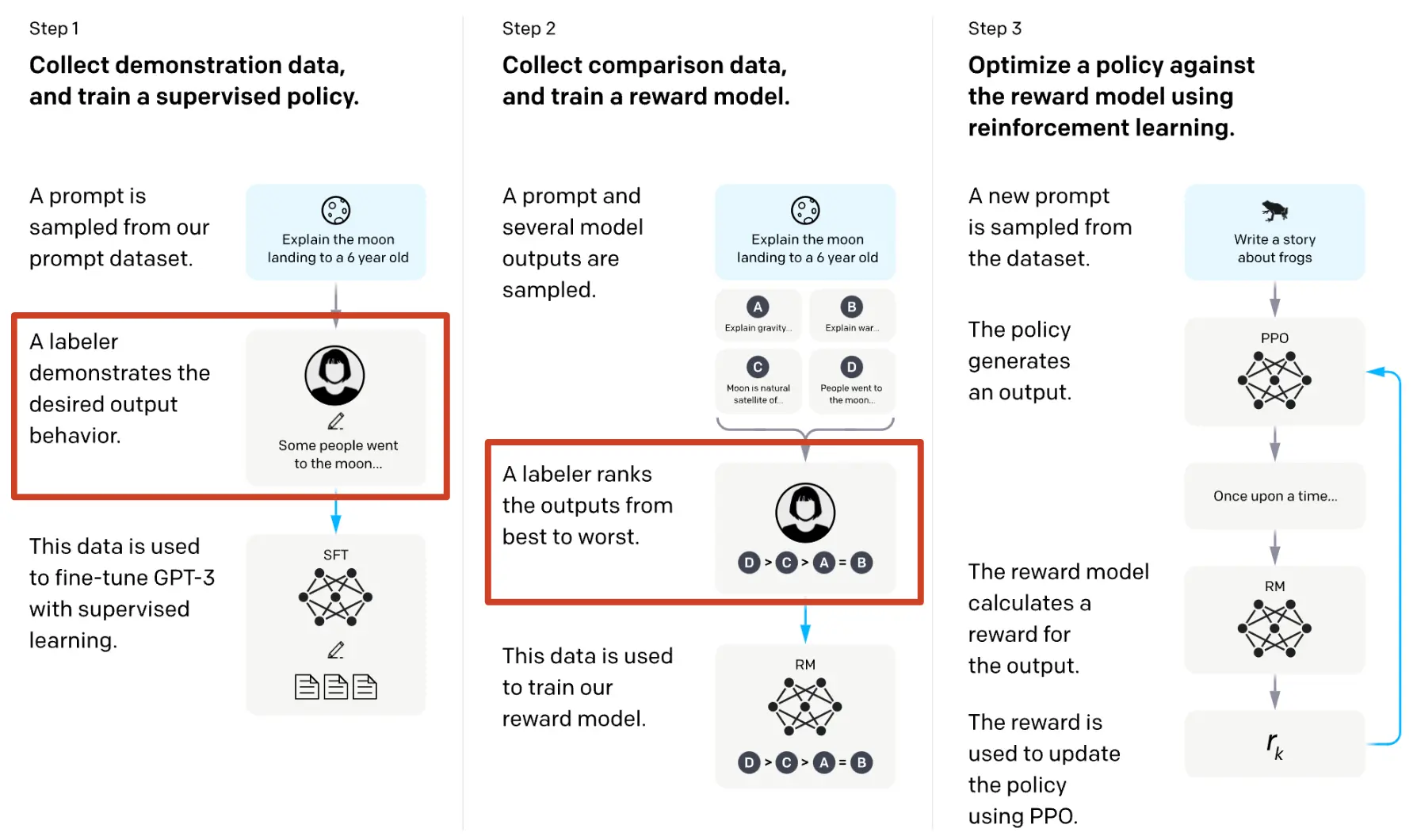
A large language model (LLM) is a type of AI used in OpenAI's ChatGPT. It is designed to understand, generate, and manipulate human language. LLMs are typically large models that consume massive amounts of data during training. The LLM used in ChatGPT is called GPT (Generative Pre-trained Transformer), which is based on Transformer models. To follow human context and dialogue, GPT models are fine-tuned using RLHF (Reinforcement Learning from Human Feedback). In this method, humans rate different responses from the model, guiding it towards more desirable outputs. This iterative process helps the model understand context better and generate responses that align more closely with human expectations. To build and fine-tune a new LLM model, human dialogue pair data (prompt and response pairs) are required. These pairs need to be annotated, including ratings for each multiple answer. The annotated data are used to fine-tune LLMs using RLHF.
RLHF Dataset (prompt and response pairs)
You don't have to fine-tune LLMs from scratch. Instead, you can use open-source pre-trained LLMs and fine-tune them with RLHF using dialog data. But how can you collect dialog data for your custom LLM models? We are proud to offer a solution for this, where you can easily collect and annotate dialog data (including images and text) automatically with human involvement in Unitlab AI
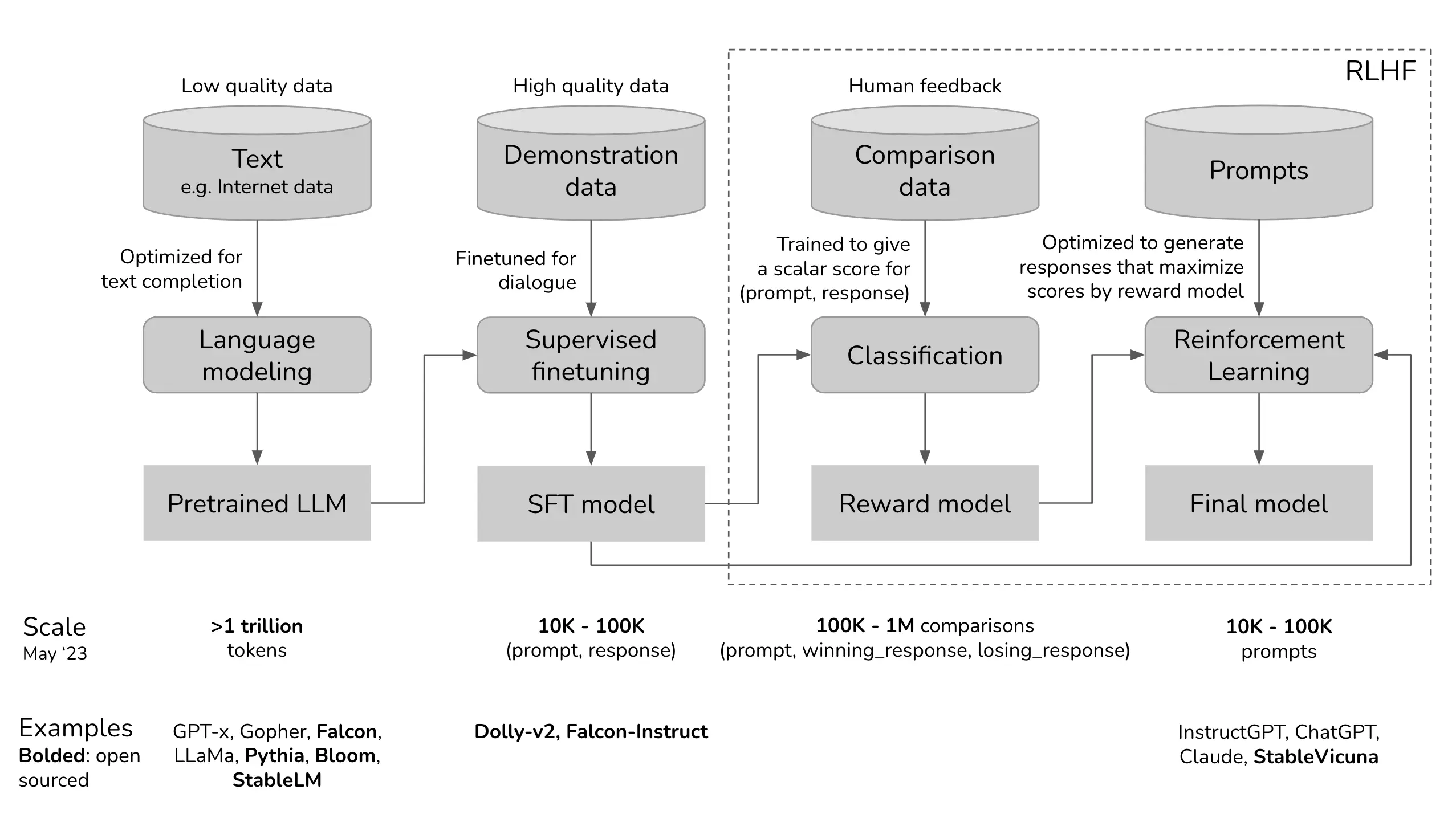
How does RLHF operate?
- Data Collection:
- Gather large datasets of human interactions with the model, such as dialogues, search results, or other task-specific data.
- Initial Model Training:
- Train a base language model using supervised learning on the collected dataset. This serves as the starting point for further refinement.
- Human Feedback Collection:
- Present the outputs of the base model to human annotators who provide feedback. This feedback often includes rankings, preferences, or specific instructions on how to improve the responses.
- Reward Model Training:
- Use the human feedback to train a reward model. This model learns to predict the quality of the model's responses based on the human-provided feedback.
- Reinforcement Learning:
- Implement a reinforcement learning algorithm (e.g., Proximal Policy Optimization - PPO) that uses the reward model to fine-tune the base language model. The reward model provides a reward signal that guides the optimization process, encouraging the model to produce higher-quality responses.
- Iteration:
- Repeat the process iteratively: collect more human feedback, update the reward model, and further fine-tune the language model using reinforcement learning. This continuous loop helps the model improve over time.
- Evaluation and Testing:
- Continuously evaluate the model's performance using both automated metrics and human evaluations to ensure that it meets the desired quality and safety standards.
- Deployment and Monitoring:
- Deploy the refined model in a real-world setting and monitor its performance. Collect user feedback and use it to further improve the model through additional RLHF cycles.
Unitlab: Collect LLMs Datasets
Unitlab AI offers the collection of LLMs and GenAI datasets with prompt and response pairs for both text and vision. You can add unlimited prompts followed by their responses; the order defines the rating. Additionally, you can assign tags to the text data of a response.
Demo: Data Collection and Annotation for LLMs and Generative AI using Unitlab AI