

TL;DR
- What are multimodal models, in simple terms?
Multimodal models are machine learning and artificial intelligence systems that process multiple data types (modalities) together. Instead of treating each data type separately, a large multimodal model learns joint representations so it can align visual cues, textual descriptions, and other modalities in a shared space. This lets one model handle tasks like image captioning, visual question answering, text-to-image search, and image generation using the same backbone.
- What is the difference between multimodal models and LLM?
Traditional unimodal models focus on a single input, like text-only large language models or image-only image recognition systems. Multimodal AI combines a language model with one or more encoders (vision encoder, audio encoder, and more) plus a fusion module that integrates data from different modalities into unified, cross‑modal representations. It lets models process data from multiple modalities at once and generate text descriptions, answer questions, or even generate images conditioned on text.
- What can modern multimodal models actually do in production?
Modern vision language models and large multimodal models support many real‑world tasks: image captioning, visual question answering, OCR and document understanding, chart and table reasoning, text-to-image search, code generation from UI screenshots, and long‑context multimodal analysis of PDFs, slide decks, or videos. Many models now accept multimodal inputs (text + images + audio, and sometimes video) and can process hundreds of pages or minutes of video in one pass, then generate text outputs such as summaries, explanations, or structured data.
- Why do multimodal models matter for AI teams today?
Multimodal capabilities let AI systems integrate data from multiple types at once, which improves accuracy compared to models trained on a single modality. For example, combining visual data and textual data can reduce ambiguity and make models less sensitive to noise in one modality. As generative AI systems move beyond pure text, multimodal learning and multimodal datasets become central to competitive AI products.
- What are the key challenges with multimodal models?
The main challenges include building large, well‑aligned multimodal datasets, synchronizing multiple data modalities, high compute and memory costs, robust evaluation of cross‑modal reasoning, managing hallucinations when models invent non‑existent visual details, and dealing with bias, privacy, and copyright in multimodal data. There are also engineering challenges around integrating multimodal systems into products and fine tuning them safely on domain‑specific text data, images, and other modalities.
We have moved past the time when AI systems only processed text. Now, they can work with different data types, such as text, images, audio, sensor data, and more.
They understand how these multiple modalities of information relate and can produce one modality from another (generating images from text descriptions).
And multimodal models make this possible.
Multimodal models help build many real-life multimodal applications, such as visual assistants capable of diagnosing medical imaging or debugging codebases from a screenshot.
In this guide, we'll cover:
- What are multimodal models?
- How multimodal model architectures work
- Multimodal model key use cases and applications
- Top multimodal models
- Challenges and future trends
If you’re building or fine-tuning AI models, high-quality annotated datasets matter as much as your model choice. We at Unitlab AI help you create and manage data with AI‑assisted annotation for images, video, text, audio, and medical images in a single workspace.
Try Unitlab AI for free and see how it accelerates your AI project!
What are Multimodal Models?
Multimodal models are trained to process and reason over multiple modalities of input. The types of input a model works with depend on the task it is built for. For example, you train a model on medical imaging and textual data to support diagnosis.
Popular data types include text data, image pixels, audio waveforms, and video frames. Some specialist models may also use data types such as time-series sequences and geospatial data when the use case requires it.
Multimodal model tasks include:
- Visual question answering (VQA)
- Image captioning
- Object detection and image classification
- Document OCR
- Object counting
- Text‑to‑image and image‑to‑text generation
Understanding the distinction between unimodal vs. multimodal models is critical for selecting the right approach for a real application.
Unimodal models work within a single data domain. For example, BERT can process text-only data, while ResNet and WaveNet (for audio synthesis) are image- and audio-specific, respectively.
On the other hand, a multimodal model can take that image plus an accompanying text caption (or question) and use both sources of information.
Multimodal systems also tend to be more robust, as if one modality is noisy or missing, they can rely on others. For example, if a camera image is blurry, a multimodal model might still infer correct information from a related text caption or audio clue.
How Multimodal Model Architectures Work
Although implementations vary, most modern multimodal systems follow a similar high‑level architecture. They start by encoding each modality with a dedicated sub-network, then merging those representations. The modality encoder can include:
- Vision Encoder (Image Encoder): A convolutional network or, more often, a Vision Transformer (ViT) that turns image pixels into a sequence of visual tokens (image embeddings).
- Text encoder or Base Language Model: A transformer‑based language model that processes text tokens.
- Audio Encoder: A convolutional or Conformer‑style network that converts raw audio or spectrograms into audio embeddings.
- Video Encoder: A temporal vision transformer or 3D CNN that encodes sequences of frames into spatiotemporal tokens.
Once each modality is embedded, the model fuses them. There are two broad architectural styles:
- Unified-Decoder Approach: Convert every input into a single stream of token embeddings, then feed them together into a standard decoder LLM. In this embedding-decoder architecture, image embeddings are treated the same as text tokens. The model’s self-attention layers then learn relationships across the sequence (both visual and textual tokens).
- Cross-Attention Approach: Keep separate encoders for each modality and use cross-attention layers to let them interact. In many vision-language models, you have a vision encoder and a language model decoder that are initially separate. The language decoder includes special cross-attention layers that query the image encoder’s output (vision embeddings). During training, these cross-attention modules learn to align vision features with text features.
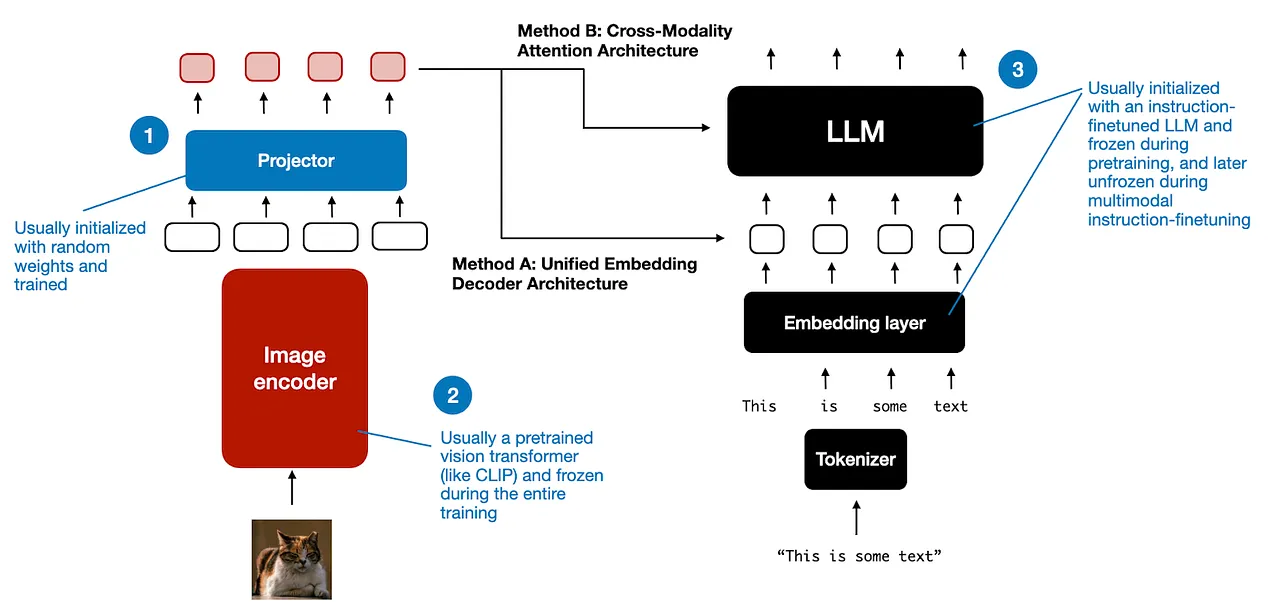
During training, multimodal models use large multimodal datasets of aligned modalities. The training objective may combine language modeling (predict next word) with contrastive or alignment losses across modalities.
In inference, the model can generate outputs in one or more modalities. For instance, given a prompt with an image and text, it might generate a textual caption, or given text it might produce an image (in a generative model).
The output modality depends on how the model is designed (some models generate only text, others can generate images or audio using diffusion or autoregressive methods).
Besides the main architectures above, multimodal models also use specific fusion methods:
- Early fusion: Merge modalities at the input level (concatenating image and text embeddings from the first layer).
- Late fusion: Process each modality mostly independently and combine high-level outputs at the end (e.g. ensemble of a vision model and a language model).
- Hybrid fusion: Mix early and late fusion or use multiple cross-modal blocks at different layers.
These techniques ensure the model can capture both fine-grained visual representations (image pixels, spatial info) and language context together.
Large models may have millions or billions of parameters across encoders and decoders, and enable them to handle many tasks like image captioning, VQA, and even cross-modal retrieval.
Multimodal Model Key Use Cases and Applications
Multimodal models are now applied across many industries and domains. Including:
Healthcare
Models can analyze medical images (X-rays, MRIs, retina scans) together with patient records. For example, a model might interpret an X-ray image, factor in the patient’s medical history (text) and vitals (sensor data), and then generate a diagnostic report.
Google’s MedGemma and other health-focused VLMs are speeding up radiology analysis and report generation. Multimodal AI also aids telemedicine, where an AI assistant could watch a doctor-patient video (vision+audio) and summarize the visit in text.
Education
Interactive educational tools use multimodal AI to improve learning. A system might combine textbook text, diagrams, and spoken questions to give more detailed explanations.
For example, a teaching bot might show a student a math problem image and talk through the solution. Multimodal models can also help language learners by showing pictures of vocabulary words or reading them aloud.
Finance
In finance, a multimodal model can process a financial report’s PDF (text + embedded graphs) to extract insights. It might answer complex questions like “What does the trend in the earnings chart imply about next quarter?” by reading the visual graph and explanatory text together.
Similarly, it could monitor news articles (text) and stock chart images to alert traders to market anomalies.
Agriculture
Farmers increasingly use drones and sensors. A multimodal AI system could analyze aerial images of a field (vision) along with sensor data (soil moisture, weather forecasts) to recommend irrigation or detect disease. For example, spotting a discolored patch in a drone image and cross-referencing it with dryness sensors to suggest watering schedules.
Augmented Reality (AR) and Virtual Reality (VR)
Augmented reality apps overlay digital information on real-world scenes. A multimodal model can take a live camera feed and user voice commands to identify objects and labels in real time.
For instance, wearing AR glasses and asking “What plant is this?” could trigger a vision+language model to recognize the plant and speak its name.
In virtual reality, multimodal AI can interpret hand gestures, speech, and environmental context to create immersive interactions.
Logistics and Inventory
In the supply chain, documents (labels, invoices) and images (package photos) are common. A multimodal model powered system could scan a shipping label (image) and the associated text form to automatically update inventory.
It could also read packaging images and text to verify contents. This reduces manual entry errors and speeds up warehouses.
Top Multimodal Models (2026)
Now lets discuss a few popular multimodal vision models. But before diving into each model, the following table summarizes the technical specifications of the top multimodal models (open source and proprietary).
Leading Open-Source Multimodal Models
Meta Llama 4 Family (Scout & Maverick)
Llama 4 Scout and Llama 4 Maverick are Meta’s first natively multimodal open‑weight models, built with a mixture‑of‑experts (MoE) transformer backbone.
Unlike previous Llama iterations that relied on adapters for vision, Llama 4 integrates vision tokens directly into the model backbone using an early fusion strategy.
The architecture employs iRoPE (interleaved Rotary Positional Embeddings). It is a positional encoding scheme that lets the model process mixed sequences of text and images of arbitrary lengths without losing spatial context.
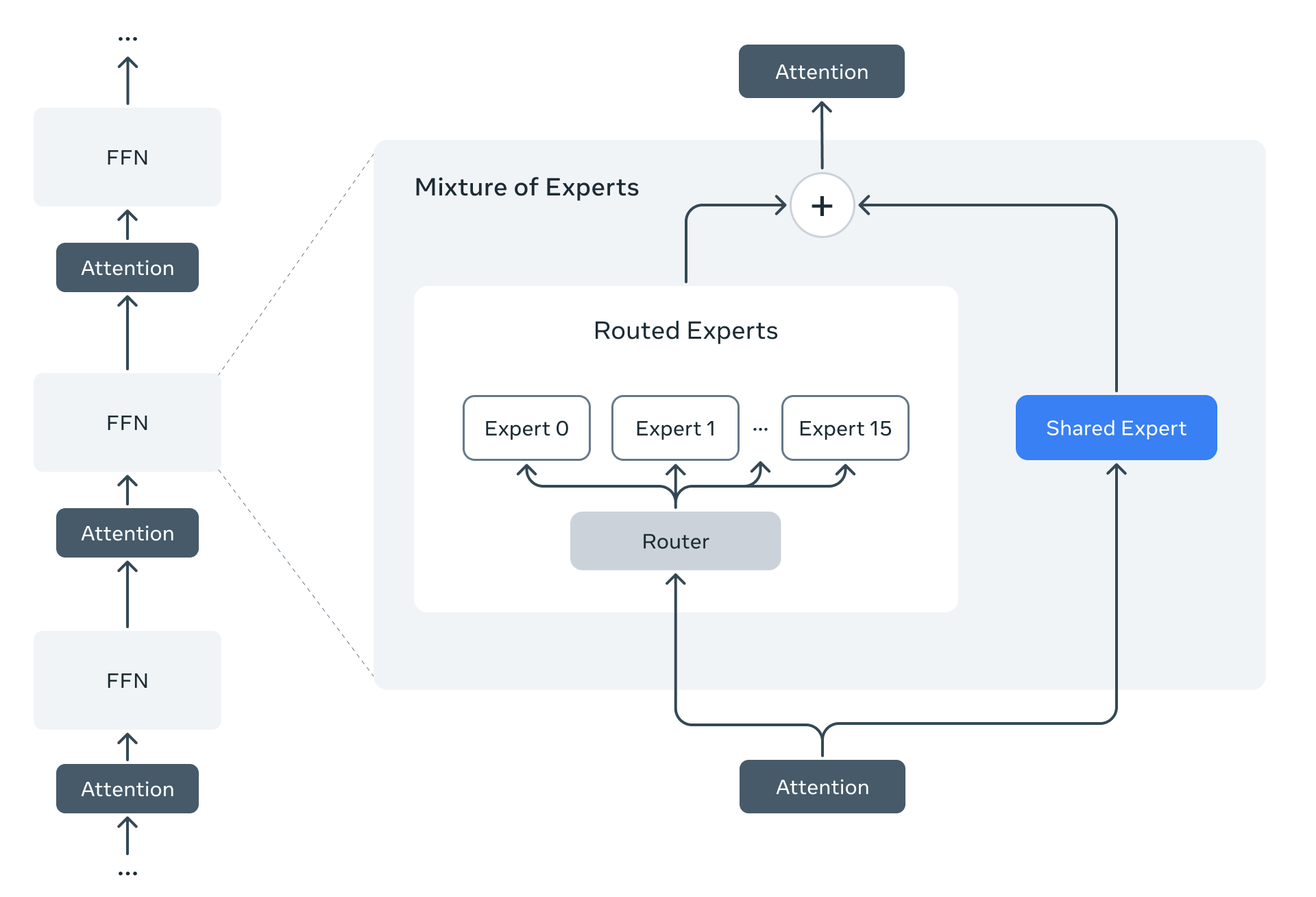
Key Features:
- 10 Million Token Context: Llama 4 Scout has the largest context window available in open-source models. It can process entire corporate archives or thousands of minutes of video
- MetaP Training: A training technique that stabilizes hyperparameter tuning when working with large batch sizes and model widths.
- Native Multimodality: Eliminates the need for separate vision encoders, reduces latency, and improves feature alignment.
Use Case
Llama 4 Scout can help with lightweight multimodal tasks where cost matters, such as image captioning, visual question answering, and multimodal educational tools. And use Maverick when you need frontier‑level reasoning over text and images.
DeepSeek-V3 and V3.2
DeepSeek-V3 and V3.2 use a Multi-head Latent Attention (MLA) mechanism that compresses the Key-Value (KV) cache to reduce memory requirements during inference.
DeepSeek‑V3 is a MoE transformer with 671B total parameters and 37B active parameters per token. And V3.2 introduces DeepSeek Sparse Attention (DSA) to further accelerate long-context processing.
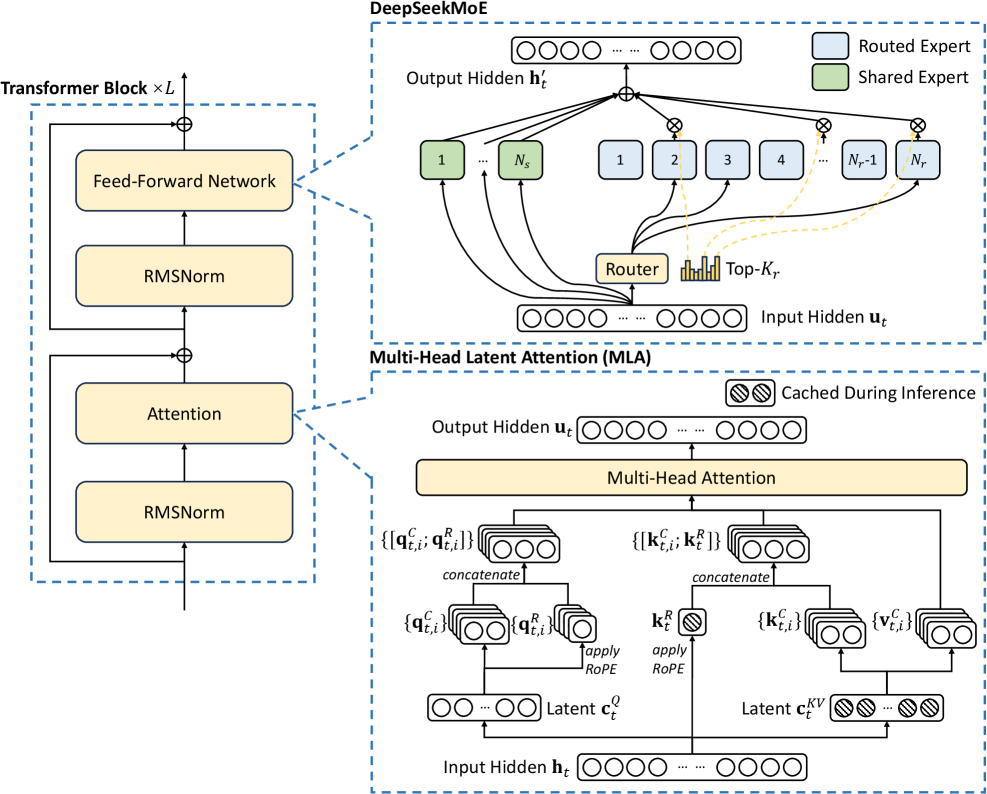
Key Features:
- Auxiliary-Loss-Free Load Balancing: A strategy to ensure expert networks are utilized evenly without the performance penalties associated with traditional auxiliary losses.
- Cost Efficiency: The training process was optimized to require only 2.8 million H800 GPU hours, setting a new standard for training economy.
Use Case
DeepSeek-V3 and V3.2 can help with high-frequency code generation and complex mathematical modeling. They are also ideal for scenarios where inference cost and latency must be minimized without sacrificing reasoning depth.
Alibaba Qwen3-VL Series
Qwen3‑VL is Alibaba’s latest vision language model series. It employs a Naive Multimodal Pre-training approach where the vision encoder and LLM interact from the earliest stages of training.
The model supports a dynamic resolution input mechanism to process images of varying aspect ratios and resolutions (M-HighRes) without distortion or artificial padding.
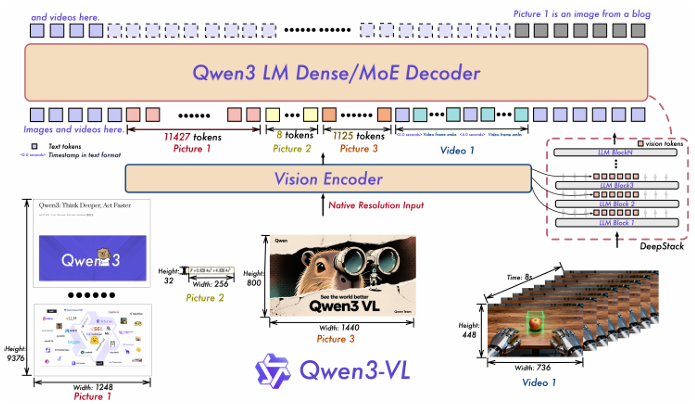
Key Features:
- System 2 Visual Reasoning: The "Thinking" variants can "ponder" visual inputs, breaking down complex geometry or logic puzzles into intermediate steps before answering.
- Full-Stack Embedding: The series includes specialized VL-Embedding and VL-Reranker models that enable high-performance multimodal information retrieval.
- Video Understanding: They can process long-form video with high temporal accuracy and identify specific events within hours of footage.
Use Case
Qwen3‑VL can help in visual search, advanced e-commerce recommendation systems, and automated video surveillance analysis.
OpenGVLab InternVL 3.0
InternVL 3.0 integrates Variable Visual Position Encoding (V2PE), which allows the model to adaptively assign positional embeddings based on the visual complexity and aspect ratio of the input.
It uses a dynamic resolution strategy, dividing images into 448x448 tiles, and connects a vision encoder (InternViT) to the large language model (InternLM 3 or Qwen backbones) via an MLP projector to maximize feature retention.
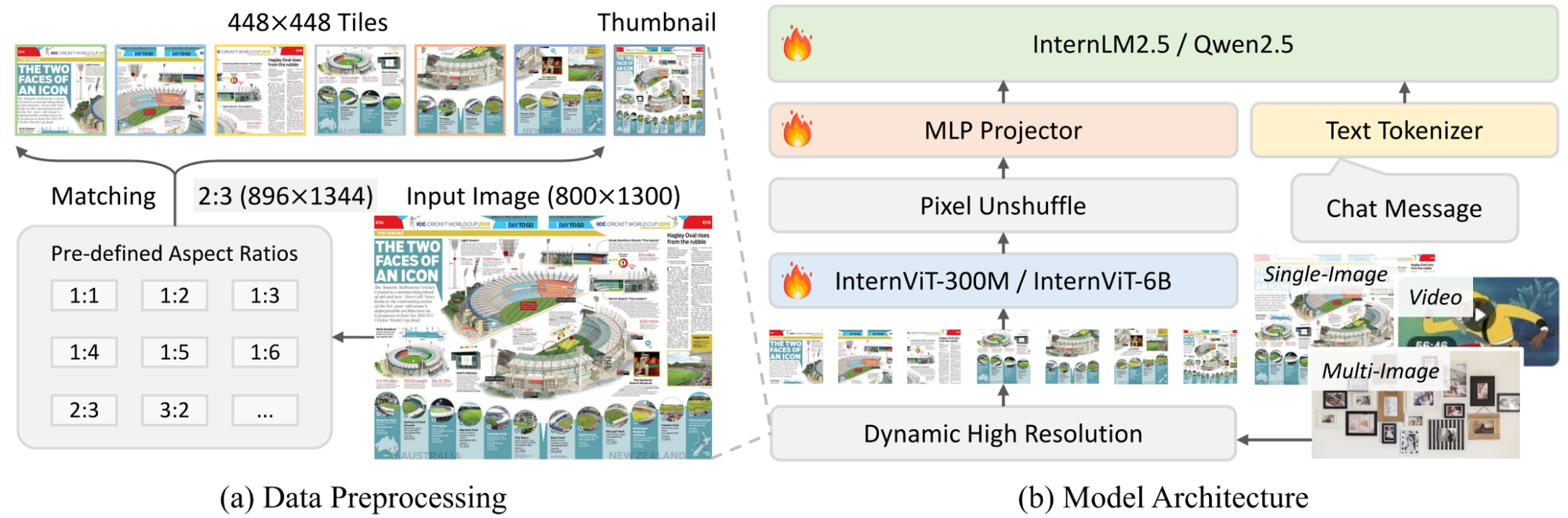
Key Features:
- Native Multimodal Pre-Training: Ensures visual and textual representations are aligned.
- Long Context Vision: V2PE support superior understanding of multi-image sequences and long-form videos.
- Industrial Analysis: The model is fine-tuned for high-precision tasks like industrial defect detection and 3D vision perception.
Use Case
InternVL can help users with industrial automation (QA/QC), high-precision document digitization, and the automated analysis of scientific charts and diagrams.
Mistral Pixtral
Pixtral 12B and Pixtral Large are Mistral’s vision language models built by combining a text decoder (Mistral Large 2 for Pixtral Large) with a separate vision encoder.
Pixtral uses 2D RoPE embeddings that let the model support images in their natural aspect ratio and resolution without resizing or padding. Vision tokens are processed directly by the multimodal decoder within a 128K context window.
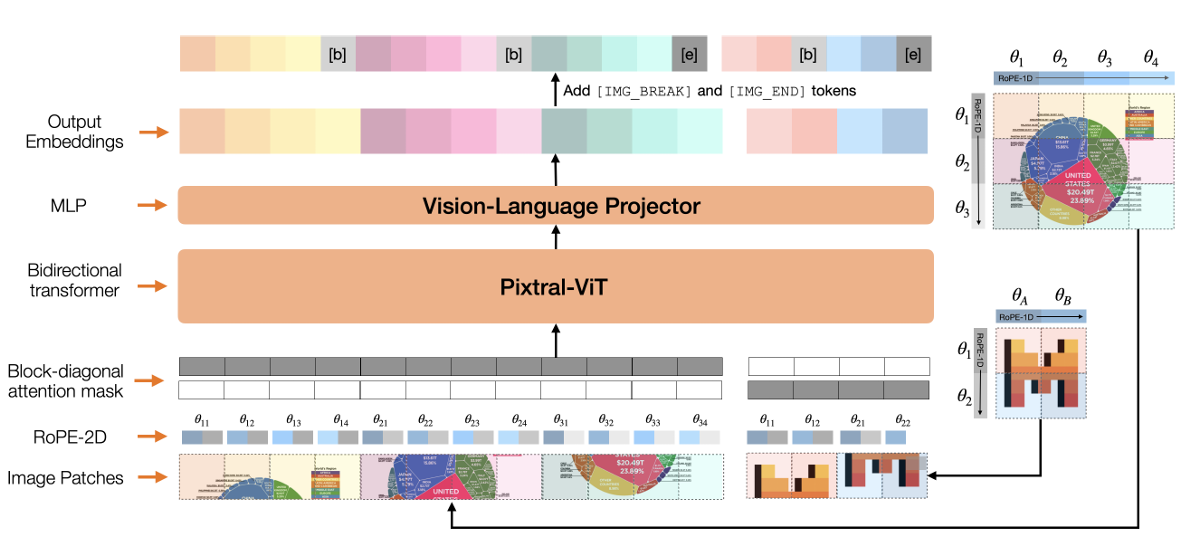
Key Features:
- Native Resolution: Ensures no loss of fine detail due to resizing or cropping, critical for reading dense text or analyzing textures.
- Interleaved Data Processing: Trained seamlessly on sequences of text and images.
- Efficiency and Scale: The 12B model offers high efficiency for edge deployment, while the large variant handles frontier-class reasoning tasks.
Use Case
Pixtral 12B can be used in enterprise document OCR pipelines, financial report analysis requiring chart interpretation, and on-premise multimodal agents.
Z.AI GLM-4.6V
GLM‑4.6V is a multimodal extension of the GLM‑4 series, with a transformer backbone trained for native multimodality.
It uses a multimodal context window of about 128–131K tokens and aligns image and text tokens via visual–language compression (inspired by work like Glyph).

Key Features:
- Native Tool Use: Capable of passing screenshots directly as tool parameters without intermediate text conversion.
- Frontend Replication: Optimized to convert UI screenshots into clean, functional HTML and CSS code.
- Visual Web Search: Executes an end-to-end visual search workflow, from perception to query to synthesis.
Use Case
GLM‑4.6V can help users with autonomous web agents, UI/UX design automation, and complex data extraction from web pages.
Microsoft Phi-4-Multimodal
Phi‑4‑Multimodal is a compact yet fully multimodal model that integrates a Phi‑4‑mini text backbone with vision and speech encoders plus modality‑specific projectors and LoRA adapters.
Different LoRA adapters are activated depending on whether the task is speech‑text, vision‑text, or vision‑speech, and allow efficient sharing of the base parameters.
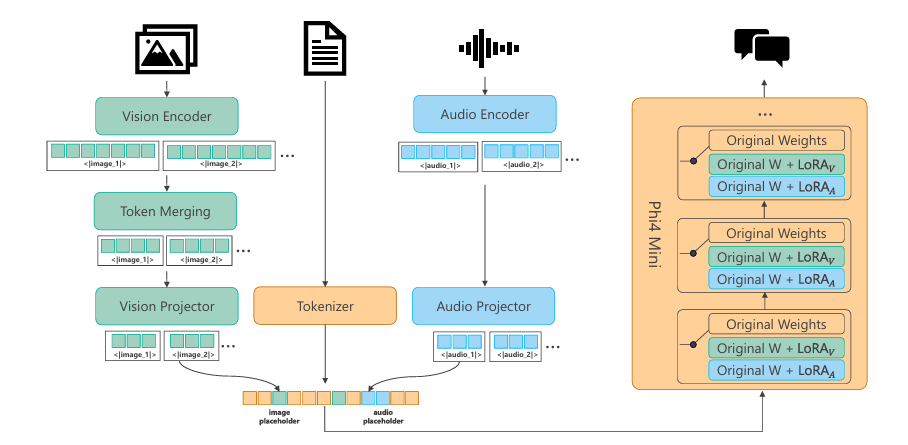
Key Features:
- Speech-to-Speech: Native audio processing enables real-time, low-latency spoken interaction.
- On-Device Capability: Small enough to run efficiently on high-end edge devices and mobile phones.
- Strong Reasoning: It excels in math and coding tasks due to the high quality of its training data.
Use Case
Phi‑4 can be used in mobile assistants, accessibility tools for the visually and hearing impaired, and embedded automotive AI systems.
Proprietary Multimodal Models
Google Gemini 3 Family (Pro, Flash, Deep Think)
The Gemini 3 family is built on the new TPU v6 infrastructure. It utilizes a dynamic MoE architecture. The Deep Think variant introduces a built-in reasoning mode that performs multi-step planning, simulation, and self-correction before outputting a response. Gemini supports real-time video processing at 60 FPS and native 3D object understanding.
Key Features:
- Antigravity Platform: A dedicated agentic development platform that uses Gemini's advanced tool-use capabilities.
- Massive Context: Supports context windows of millions of tokens for the processing of entire code repositories or full-length movies.
- Audio and Video Native: Processes raw audio and video streams without intermediate text conversion to preserve non-verbal cues.
Use Case
The Gemini 3 can be used for scientific research assistants, real-time video analysis for security, and complex software engineering agents requiring deep context.
OpenAI GPT-5 Family
GPT-5 features an automatic routing mechanism that assesses query complexity and switches between fast inference and deep reasoning (Thinking) modes in real-time.
Key Features:
- Unified Experience: Eliminates the need for users to manually select between smart and fast models.
- Agentic Reliability: Greatly improved long-horizon tasks and autonomous tool usage.
- Cybersecurity: Advanced capabilities in Capture-the-Flag (CTF) challenges necessitate new safety protocols.
Use Case
GPT-5 can help users with autonomous coding agents, advanced data analysis pipelines, and enterprise-grade decision support systems.
Anthropic Claude Opus 4.5
Claude Opus 4.5 introduces a parameter that allows users to dictate the balance between token efficiency and response thoroughness.
Its architecture is optimized for coding and complex instruction following, with enhancements in sparse attention to effectively manage a 200K+ context window while reducing latency.
Key Features:
- Effort Parameter: Granular control over High, Medium, or Low thinking effort.
- Computer Use: State-of-the-art capability to control desktop environments and web browsers directly.
- Prompt Injection Resistance: Hardened against adversarial attacks and jailbreaking attempts.
Use Case
Opus is best for automated software development teams, secure enterprise data processing, and complex research synthesis.
xAI Grok 4
Grok 4 takes advantage of the huge computing power of the Colossus cluster, which has 200,000 GPUs. It uses a mix of different neural network designs, with specific parts focused on reasoning and coding.
Grok 4 can handle up to 2 million tokens of information at once and can access real-time data from the X platform.
For complicated problems, Grok 4 has a "Big Brain" mode that uses more computing time per question to thoroughly explore possible solutions.
Key Features:
- Real-Time Knowledge: Unmatched access to real-time news, social sentiment, and event data.
- Unfiltered Reasoning: Designed to be less constrained in its outputs compared to competitors, offering a different safety profile.
- Spatial Intelligence: Improvements in 3D and physical world understanding.
Use Case
Grok 4 is ideal for real-time financial analysis, news aggregation and synthesis, and unbiased research exploration.
Specialized Multimodal Models
DeepSeek-OCR
DeepSeek-OCR is a specialized vision-language model for document understanding. It employs Context Optical Compression, a technique that maps large 2D document images into highly compressed vision tokens (achieving up to 10x compression).
The architecture consists of a Vision Encoder (DeepEncoder) utilizing SAM (Segment Anything Model) and CLIP, connected to a specialized MoE decoder.
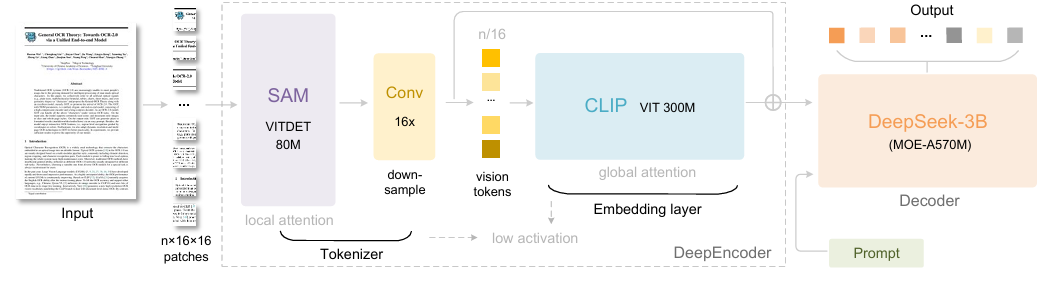
Key Features:
- Token Efficiency: Processes high-resolution documents using a fraction of the tokens required by standard VLMs.
- Box-Free Parsing: Generates full markdown and LaTeX outputs, including tables and formulas, without requiring bounding boxes.
- Multilingual: Strong support for diverse languages and handwritten text recognition.
Use Case
DeepSeek-OCR is the best choice for digitizing historical archives, automated invoice processing, and converting scientific papers into structured data.
Gemma 3 (Google)
Gemma 3 is Google's open-weights contribution to the multimodal model space. It uses a segment-interleaved attention architecture to manage KV-cache memory and prevent an explosion during long-context inference (128K tokens).
It is trained using distillation from larger Gemini models to ensure high performance at smaller parameter counts (1B to 27B).
Key Features:
- Run-Anywhere: Optimized for consumer GPUs and TPUs.
- Multilingual: Supports over 140 languages.
- Visual Understanding: Native ability to process images and video segments without external adapters.
Use Case
Gemma 3 is ideal for on-device translation, educational apps, and local multimodal assistants.
OpenBMB MiniCPM-V 4.5
MiniCPM-V 4.5 is optimized for mobile and edge deployment. It features a Unified 3D-Resampler that compresses spatial-temporal information for both images and videos (achieving up to 96x compression for video tokens).
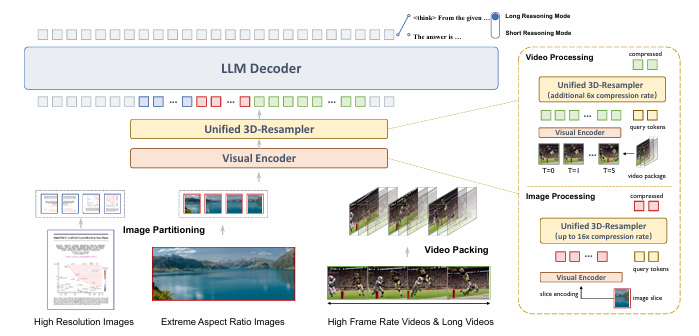
Key Features:
- Hybrid Thinking: Switchable fast/deep reasoning modes.
- Video Understanding: State-of-the-art performance for models under 30B parameters.
- Low Memory Footprint: Runs efficiently on consumer GPUs and mobile NPUs.
Use Case
MiniCPM-V 4.5 is best for mobile video analysis apps, real-time robotics perception, and smart home camera intelligence.
Kyutai Moshi
Moshi is a speech-native multimodal model. It uses the Mimi neural audio codec to process audio as discrete tokens alongside text.
Moshi architecture is full-duplex. It processes user audio and generates system audio simultaneously in parallel streams for natural interruptions and back-and-forth conversation without latency.
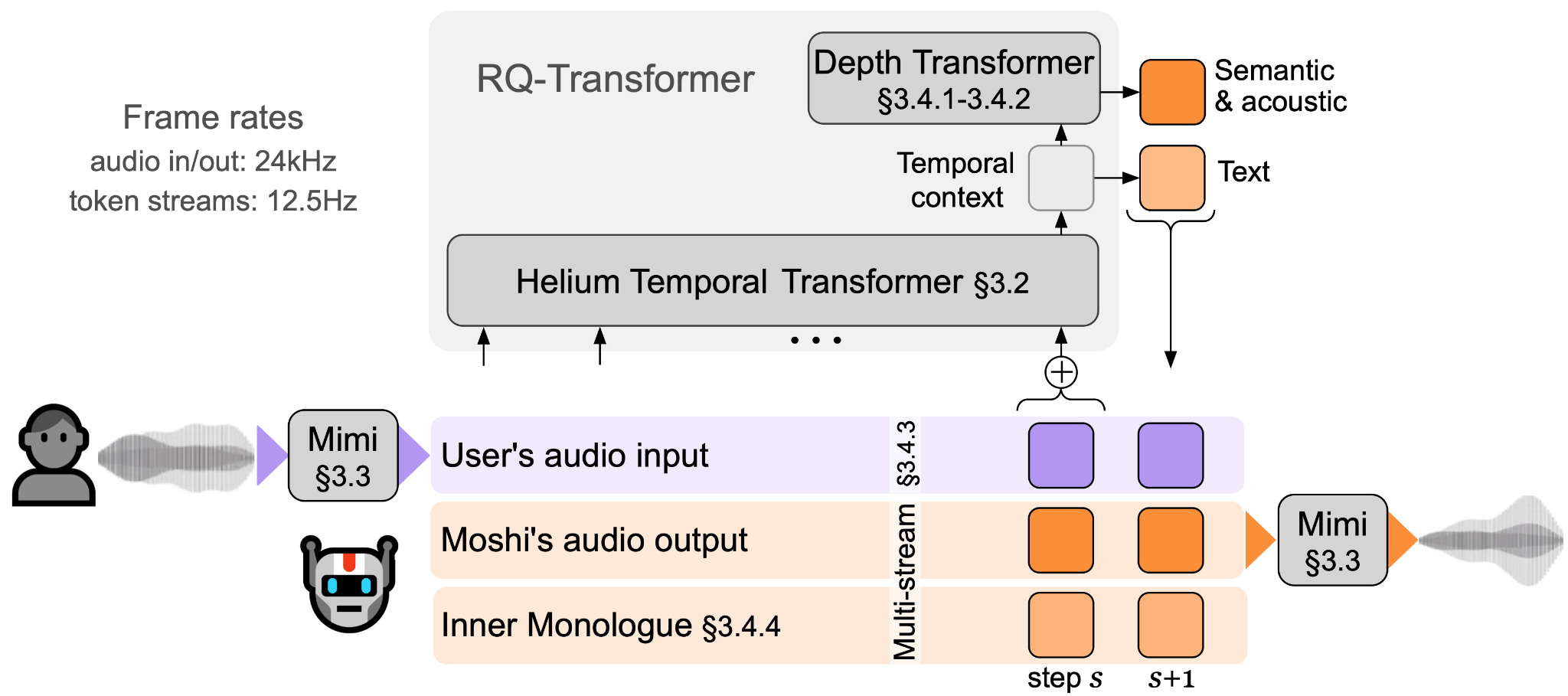
Key Features:
- Zero-Latency: Theoretical latency as low as 160ms; feels instant to the user.
- Emotional Intelligence: Understands and expresses tone, whispers, and emotional nuance.
- Pocket TTS: A lightweight 100M parameter variant capable of running on CPUs.
Use Case
Moshi can help users build voice assistants, empathetic therapeutic AI, and real-time translation devices.
Challenges and Future Trends
Despite the benefits of multimodal models, there are significant challenges you should consider:
- Data Quality and Alignment Across Modalities: High‑quality multimodal datasets that align text, images, audio, and video precisely are difficult to collect and annotate. Misalignment between different modalities, like captions that do not match images, can lead to unreliable multimodal learning and hallucination in multimodal models.
- Scalability and Compute Costs: Training large multimodal models requires significant compute for both text and visual encoders, as well as large‑context training. Even inference can be expensive when processing long documents or many high‑resolution images.
- Robustness and Hallucinations: Multimodal systems can hallucinate text, visual content, and audio, sometimes inventing features that are not present in the data. Although multimodal inputs reduce some hallucinations (by grounding in visual data), misleading or ambiguous inputs can still trigger spurious reasoning.
- Bias, Fairness, and Privacy: Multimodal datasets inherit biases from both text and visual data and lead to fairness issues in deployment. Furthermore, images, audio, and video are sensitive from a privacy perspective and require careful governance and anonymization, particularly in domains such as healthcare and finance.
Future Trends
Looking ahead, future trends include more efficient fusion architectures, such as better cross-attention techniques and unified encoders. There will also be increased focus on fine-tuning and prompt engineering for multimodal inputs.
Also, models are expected to be trained more extensively on data, including robotics logs and simulations, to better understand cause and effect (physical intelligence) in the real world, not just semantic relationships.
Ultimately, the line between input and output modalities will blur, with models natively accepting any combination of inputs and generating any combination of outputs (Any-to-Any) without specialized adapters.
Multimodal Models: Key Takeaways
Multimodal models are changing human-AI interaction by allowing users and businesses to implement AI in complex environments requiring an advanced understanding of real-world data.
Here are a few critical points regarding multimodal models:
- Multimodal Model Architecture: Multimodal models have an encoder that turns raw data from different modalities into feature vectors, a fusion strategy to consolidate data modalities, and a decoder that processes the combined data to produce relevant results.
- Fusion Mechanism: While legacy models used late fusion, modern multimodal models use early fusion and cross-attention layers to consolidate data modalities for immediate reasoning across text and images.
- Multimodal Use Cases: Multimodal models help in visual question-answering (VQA), image captioning, text-to-image search, and complex agentic workflows in healthcare and finance.
- Top Multimodal Models: Llama 4, GPT-5, Gemini 3, and DeepSeek-V3 are popular multimodal models that can process video, image, audio, and textual data with high efficiency.
- Multimodal Challenges: Building multimodal models involves challenges such as data scarcity, high latency in "Thinking" modes, and model complexity. However, experts can overcome these problems through data pipelines, automated labeling tools (such as Unitlab (multimodal data annotation available soon)), and breakthroughs in architectural efficiency.

