

When we walk through a crowded city street, our brain processes multiple sensory inputs, such as sight, sound, touch, and spatial orientation, to interpret situations.
But machines lack natural senses. Multimodal data combines multiple types of information, like images audio video, text, and sensor data such as LiDAR, into a single dataset that gives these machines a human-like view of information.
Artificial intelligence (AI) enables machines to understand and interpret multimodal data and helps build real-world multimodal applications across industries.
In this article, we will cover:
- What is multimodal data?
- Why multimodal data matters
- Types of multimodal data
- Top multimodal datasets
If you are working with computer vision, natural language processing, medical records, or any domain with diverse data sources, high-quality data annotation is essential for success.
We at Unitlab help AI teams integrate custom AI models directly into their annotation pipelines to speed up the creation of clean, accurate training data. So they can train powerful AI models faster and more efficiently.
What is Multimodal Data?
Multimodal data refers to information that is combined from multiple modalities or sensory channels and integrated into a single model for analysis.
Unlike traditional datasets that focus on sequential numerical values or a single format, multimodal data provides a holistic view of an entity or event by processing diverse data types.
Technically, a modality is a medium for capturing or expressing information. When an AI model processes a video file, it is dealing with a multimodal data structure that includes a sequence of visual data (frames), an audio file (soundtrack), and often textual data (subtitles or transcripts).The key difference between traditional unimodal data and multimodal data is the amount of information they provide to an AI model to make decisions.
Unimodal data involves a single data type. For instance, a conventional vision model might use only images, or a text classifier might use only documents.
In contrast, multimodal AI combines information from different sources to improve learning. For example, image captioning models use both visual data (the image) and textual data (captions) together.
Similarly, speech recognition systems might use audio files and associated video frames or speaker transcripts. Autonomous vehicles fuse camera images, LiDAR sensor data, GPS coordinates, and more through the use of multimodal data.
Here is the summary of unimodal data vs. multimodal data.
Multimodal Data Types
The multimodal data consists of several types, each serving as a vital component in modern artificial intelligence applications:
- Structured Data: Tabular or database records with defined fields. Examples include spreadsheets of financial metrics, rows of customer information (age, income, purchase history), or electronic health records (patient vitals, lab results). These data types have fixed schemas. In multimodal data, structured data might be combined with images or text.
- Text Data (Unstructured Text): Free-form text such as news articles, social media posts, medical notes, or subtitles. Common examples are product reviews, research papers, tweets, or transcripts of speech.
- Time-Series Data: Sequential numerical data recorded over time. It includes signals like heart rate sensor logs, stock prices, weather readings, or engine sensor streams. In multimodal data, time-series data is often synchronized with other modalities, such as heart rate readings aligned with patient EEG signals and medical video. Similarly, it might complement video (motion sensor + video) or audio (accelerometer + microphone data).
- Imaging Data: It includes digital images from cameras or scans. Medical imaging (X-rays, MRIs, CT scans), satellite and aerial photographs, or product photos are typical examples. In multimodal data, images can be paired with a chest X-ray, the patient’s EHR, and genomic markers, or with a photograph and its description.
- Audio Data: It includes sound recordings or waveforms, such as speech, music, or environmental sounds. Examples include voice recordings, podcast audio, sirens and alarms, and machine noise. In multimodal data, audio often pairs with video, text (speech transcripts), or sensor data. An audio clip can provide cues like speaker identity or emotion to complement facial images or action recognition in video.
- Video Data: Videos are sequences of images (frames) over time, often with synchronized audio. In multimodal data datasets, video clips are paired with text (captions or transcripts) or with sensor readings.
- Sensor or Specialized Data: This includes sensory or specialized data, such as LiDAR point clouds, radar readings, and the ability to integrate genomic data. These types of specialized data are critical for autonomous systems and precision medicine, but require more processing resources due to their complexity.
Why Multimodal Data Matters
Multimodal data addresses the limitations of processing purely visual data in computer vision. Since pixel data is often insufficient for accurate analysis due to factors like lighting, occlusion, and perspective. So by combining visual data with other diverse data sources (modalities), AI systems achieve higher performance, robustness, and context-specific awareness.
- Improved Model Performance and Context: Combining visual data with complementary modalities (like text, audio, or sensor data) greatly improves accuracy. A study on multimodal deep learning for solar radiation forecasting found a 233% improvement in performance when applying a multimodal data approach compared to using unimodal data.
- Redundancy and Robustness: Multimodal data is more robust to noise or missing data. If one modality is degraded, others can compensate. For instance, if a camera’s view is obscured, a drone’s audio or infrared sensor might still detect threats.
- Cross-Domain Insights: Many tasks require understanding across different domains. Multimodal data enables linking visual, textual, auditory, and sensor information. For example, training on both videos and transcribed speech lets models do action recognition and generate descriptions. Models can transfer what they learn in one modality to improve another (learning scene context from images can improve text analysis).
- Human-Centric Interaction: Because humans naturally use multiple senses, multimodal AI supports more natural interactions. Systems that see, listen, and read can interact like a person. For instance, augmented reality applications overlay virtual objects by fusing camera imagery with spatial maps and user voice commands. Virtual assistants become more capable when they combine visual data, audio input, and text understanding to interpret complex user queries.
Top Multimodal Datasets
We will now examine the premier multimodal datasets specifically created to evaluate the cognitive abilities of multimodal models.
But if you are short on time, here is a brief overview of these datasets provided below.
Flickr30K Entities
Flickr30K Entities is multimodal data and an augmented version of the original Flickr30K dataset. It is designed to ground language in vision by linking specific phrases in captions to bounding boxes in images.
While the original dataset provided image-caption pairs, the Entities version adds a layer of dense annotations that map phrase chains (referring to the same entity). This mapping is to specific regions in the image for fine-grained visual reasoning.

- Research Paper: Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models
- Modalities: Images and Text (Captions).
- Typical Tasks and Applications: Phrase Localization, Image-Text Matching, Grounded Image Captioning, Visual Coreference Resolution.
- Size: 31,783 images (everyday scenes), 158,915 captions (5 per image), and about 276,000 manually drawn grounded regions (bounding boxes) plus 244,000 phrasings to single entities (coreference chains).
- Access: Visit Bryan Plummer's website for the original Flickr30k Dataset.
- Significance: Flickr30k Entities is unique because it links noun phrases in captions directly to bounding boxes in the images, providing a precise bridge between visual data and textual data.
Visual Genome
Visual Genome is a large-scale multimodal dataset created to connect structured image concepts to language. It decomposes images into scene graphs (structured representations of objects, attributes, and relationships).
This dense annotation style lets models understand what is in an image and how objects interact, and provides a cognitive bridge between pixel data and symbolic reasoning.

- Research Paper: Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
- Modalities: Visual (Images) and Textual (Annotations).
- Typical Tasks: Visual Question Answering (VQA), Scene Graph Generation, Relationship Detection, Image Retrieval.
- Size: Over 108,077 images with 5.4 million region descriptions and 1.7 million QA pairs.
- Access: Hugging Face.
- Significance: The Visual Genome dataset offers a dense semantic representation of images, linking objects (Subject) -> Predicate -> Object (Man -> Riding -> Horse).
MuSe-CaR (Multimodal Sentiment Analysis in Car Reviews)
MuSe-CaR is a large, in-the-wild dataset for multimodal sentiment analysis and emotion recognition. It is collected from YouTube car reviews, and it captures professional and semi-professional reviewers discussing vehicles.
MuSe-CaR multimodal data focuses on topic-specific sentiment (sentiment towards steering vs. price) in a dynamic, real-world setting, with high-quality audio and video.

- Research Paper: The Multimodal Sentiment Analysis in Car Reviews (MuSe-CaR) Dataset: Collection, Insights and Improvements.
- Modalities: Video, Audio, Text (Transcripts).
- Typical Tasks: Multimodal Sentiment Analysis, Emotion Recognition, Topic-Based Sentiment Classification
- Size: The dataset includes 40 hours of video from 350+ reviews, featuring 70 host speakers and 20 overdubbed narrators.
- Access: Available upon request/registration (often used in MuSe challenges).
- Significance: It captures authentic human expressions and sentiments linked to specific topics (automotive reviews) and makes MuSe-CaR multimodal data ideal for training virtual assistants in retail contexts.
CLEVR
CLEVR stands for “Compositional Language and Elementary Visual Reasoning”. It is a synthetic dataset generated to diagnose the visual reasoning abilities of AI models.
CLEVR consists of rendered 3D scenes with simple geometric shapes and complex questions that require multi-step logic to answer ("Are there the same number of large cylinders as blue spheres?"). It isolates reasoning skills from the noise of natural images.

- Research Paper: CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning.
- Modalities: Synthetic Images (3D rendered), Text (Questions and Answers), Structured Scene Graphs.
- Typical Tasks: Visual Question Answering (VQA), Visual Reasoning, Neuro-Symbolic AI Evaluation.
- Size: 70,000 training images and approximately 700,000 questions.
- Access: Available via Stanford University's project page.
- Significance: CLEVR is designed to test a model's ability to perform logical reasoning about objects' shapes, sizes, and materials in a controlled environment.
InternVid
InternVid is a large-scale video-centric multimodal data for transferable video-text representations. It emphasizes high-quality alignment between video clips and textual descriptions.
InternVid offers superior text-video correlation compared to older datasets derived solely from noisy alt-text or subtitles by using large language models (LLMs) to refine and generate captions.
- Research Paper: InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation.
- Modalities: Video, Text (Captions).
- Typical Tasks: Video-Text Retrieval, Video Captioning, Text-to-Video Generation, Pre-training Video Foundation Models.
- Size: Over 7 million videos totaling nearly 760,000 hours, with 230 million text descriptions.
- Access: Publicly available via Hugging Face.
- Significance: A relatively new and massive dataset designed for generative models to understand everyday scenes and activities.
MovieQA
MovieQA is a challenging dataset to evaluate machine comprehension of long-form stories. Unlike short clip datasets, MovieQA requires models to reason over entire movies using multiple information sources.
It aligns video clips with plot summaries, subtitles, scripts, and described video service (DVS) data, presenting questions that often require understanding the narrative arc.
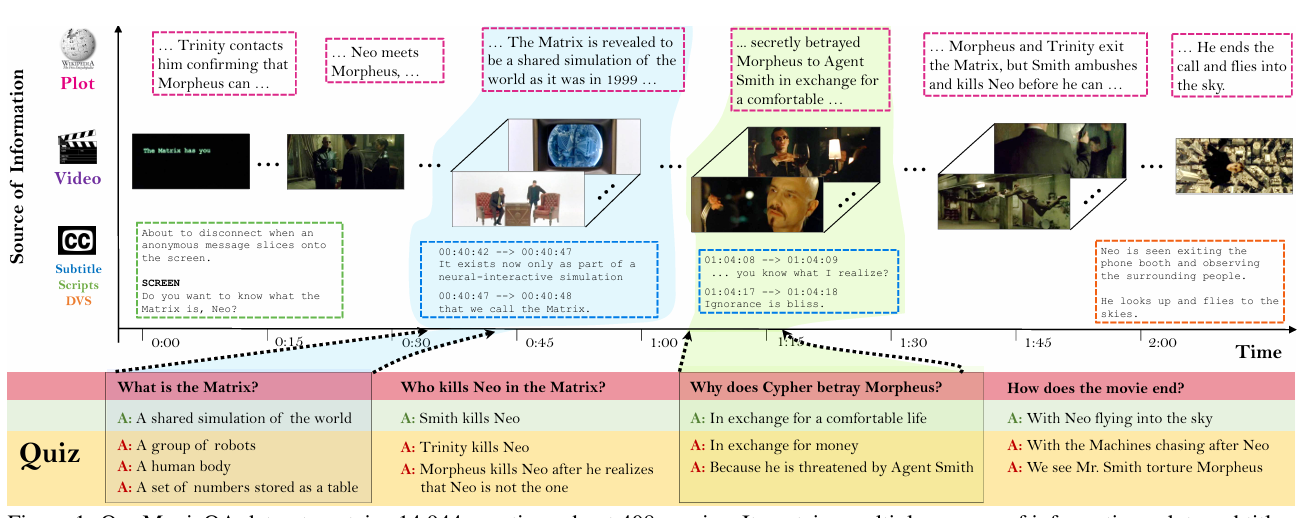
- Research Paper: MovieQA: Understanding Stories in Movies through Question-Answering
- Modalities: Video, Text (Plots, Subtitles, Scripts).
- Typical Tasks: Visual Question Answering, Story Comprehension, Video Retrieval from Text.
- Size: 14,944 multiple-choice questions from 408 diverse movies.
- Access: Available via the MovieQA project website.
- Significance: It requires models to understand long-form narrative arcs and social interactions, making it a difficult benchmark for multimodal AI.
MSR-VTT (Microsoft Research Video to Text)
MSR-VTT is a video captioning and retrieval multimodal dataset. It provides a diverse collection of video clips covering categories like music, sports, and news, paired with sentence descriptions collected from human annotators. It is widely used to evaluate how well models can translate dynamic visual content into natural language.
- Research Paper: MSR-VTT: A Large Video Description Dataset for Bridging Video and Language.
- Modalities: Video, Text (Captions), Audio.
- Typical Tasks: Automatic video captioning and retrieval.
- Size: 10,000 video clips, 200,000 sentence descriptions (20 per clip).
- Access: Available via Hugging Face and Kaggle.
- Significance: A popular benchmark that covers diverse categories like sports, music, and animals, and helps models generalize to unseen content.
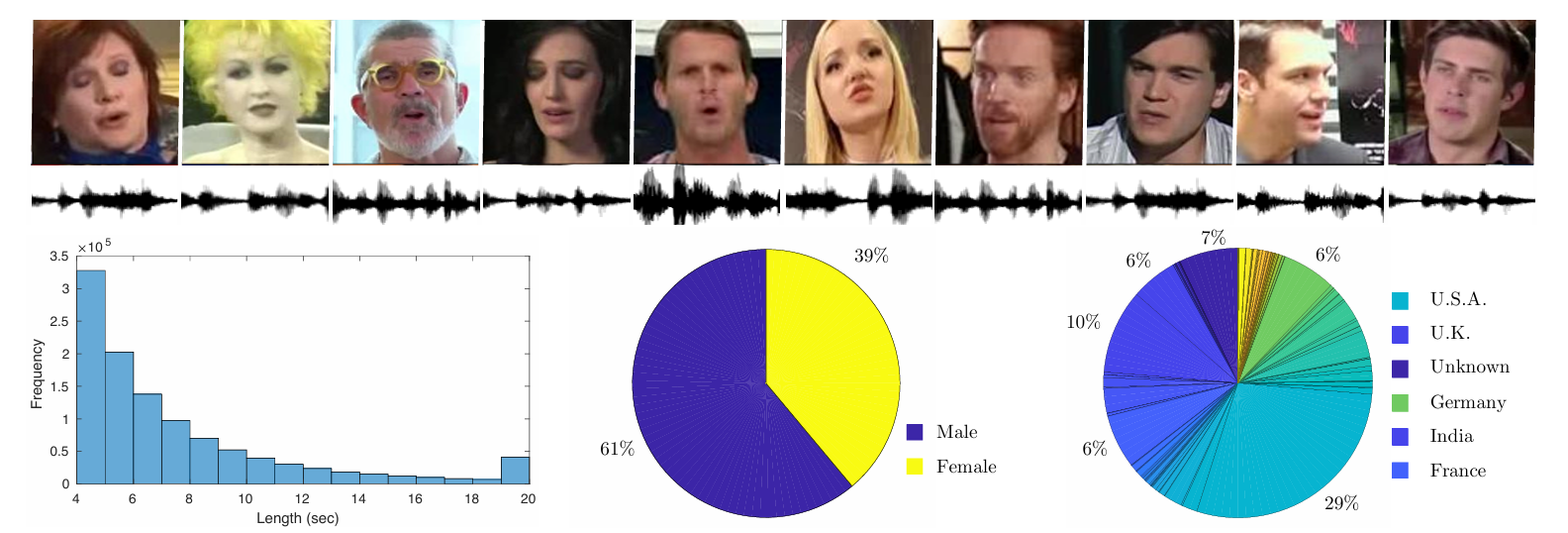
VoxCeleb2
VoxCeleb2 is a large-scale speaker recognition dataset containing audio and video recordings of celebrities speaking in real-world environments (interviews, talk shows). It helps train speaker identification models that function well in noisy, unconstrained conditions.
- Research Paper: VoxCeleb2: Deep Speaker Recognition
- Modalities: Audio and Video.
- Typical Tasks: Speaker identification, verification, and diarization, plus audio-visual speech recognition and talking head generation.
- Size: Over 1 million utterances from 6,112 celebrities covering a diverse range of accents and languages.
- Access: Available through the VoxCeleb website.
- Significance: Curated via a fully automated pipeline. It is among the largest publicly available datasets for speaker recognition in unconstrained environments.
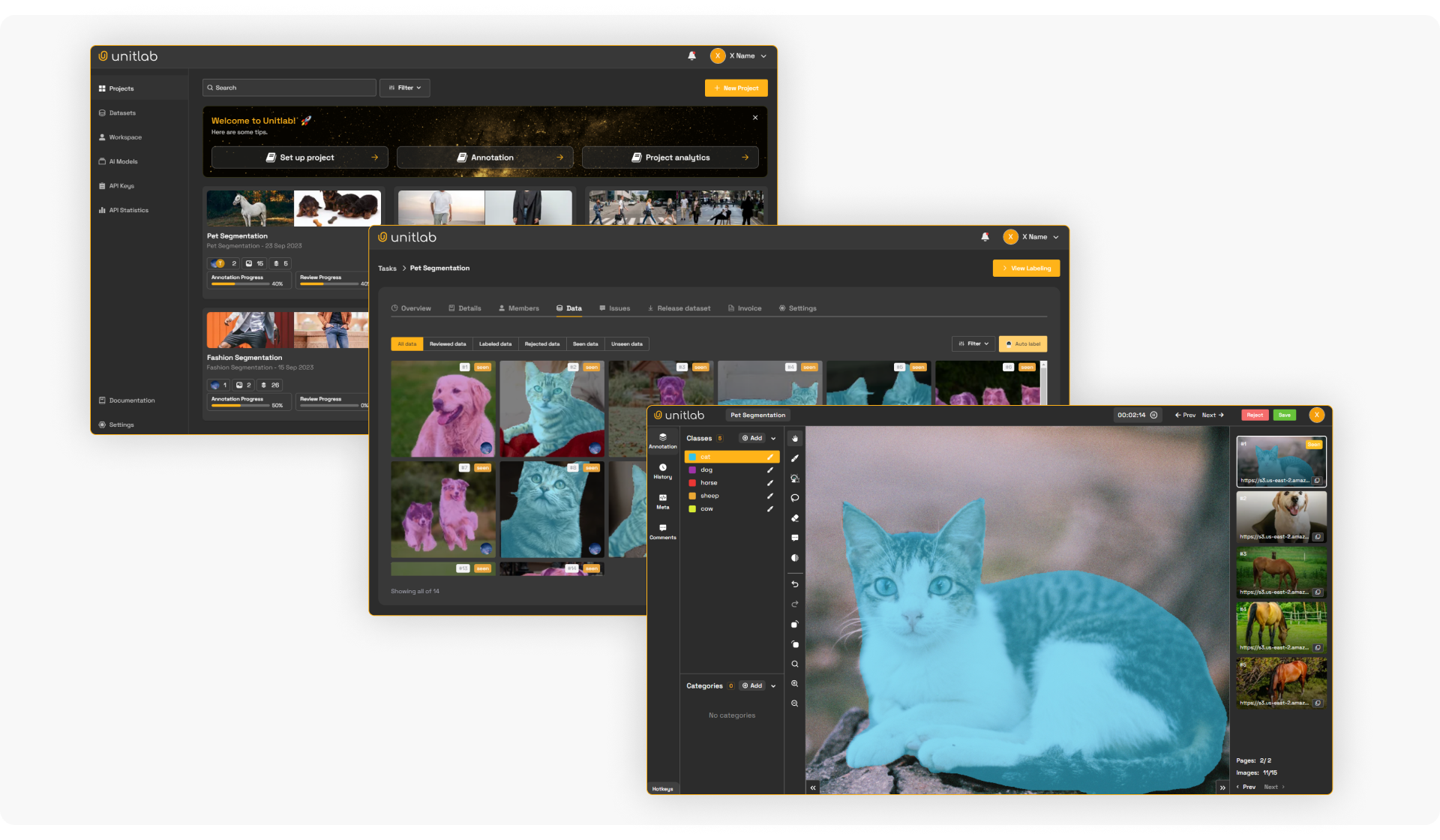
VaTeX (Variational Text and Video)
VaTeX is a large-scale multilingual video captioning dataset. It contains video clips paired with descriptions in both English and Chinese. VaTeX features human-annotated captions in both languages for cross-lingual video understanding and machine translation tasks.

- Research Paper: VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research.
- Modalities: Video and Multilingual Text (English and Chinese).
- Typical Tasks: Multilingual video captioning, video-guided machine translation, cross-modal retrieval.
- Size: 41,250 videos, 825,000 captions (412k English, 412k Chinese).
- Access: Publicly available via the VaTeX website.
- Significance: It contains parallel bilingual captions, making it a unique resource for studying how visual data can assist in complex language translation tasks.
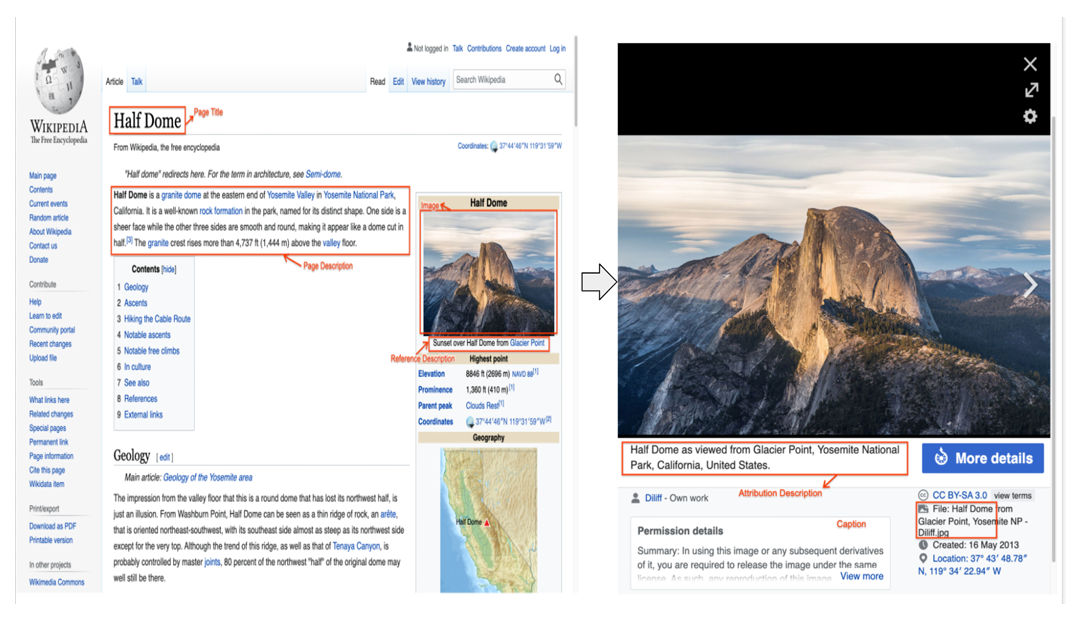
WIT (Wikipedia-based Image Text)
Google AI introduced WIT to facilitate research in multimodal learning, especially in multilingual contexts where data have traditionally been scarce. It is a first-of-its-kind large-scale multilingual multimodal dataset extracted from Wikipedia.
WIT consists of images paired with varied text contexts, including reference descriptions, attribute descriptions, and alt-text, across 108 languages. Its scale and multilingual nature make it a good choice for training large-scale vision-language models like CLIP or PaLI.
- Research Paper: WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning.
- Modalities: Image and Multilingual Text.
- Typical Tasks: Multilingual multimedia learning and image-text retrieval.
- Size: 37.6 million image-text sets, 11.5 million unique images, 108 languages.
- Access: Access WIT via the official GitHub repository or through the TensorFlow Datasets catalog.
- Significance: WIT allows researchers to train vision-language models that work natively in underrepresented languages, reducing the English-centric bias often found in AI research.
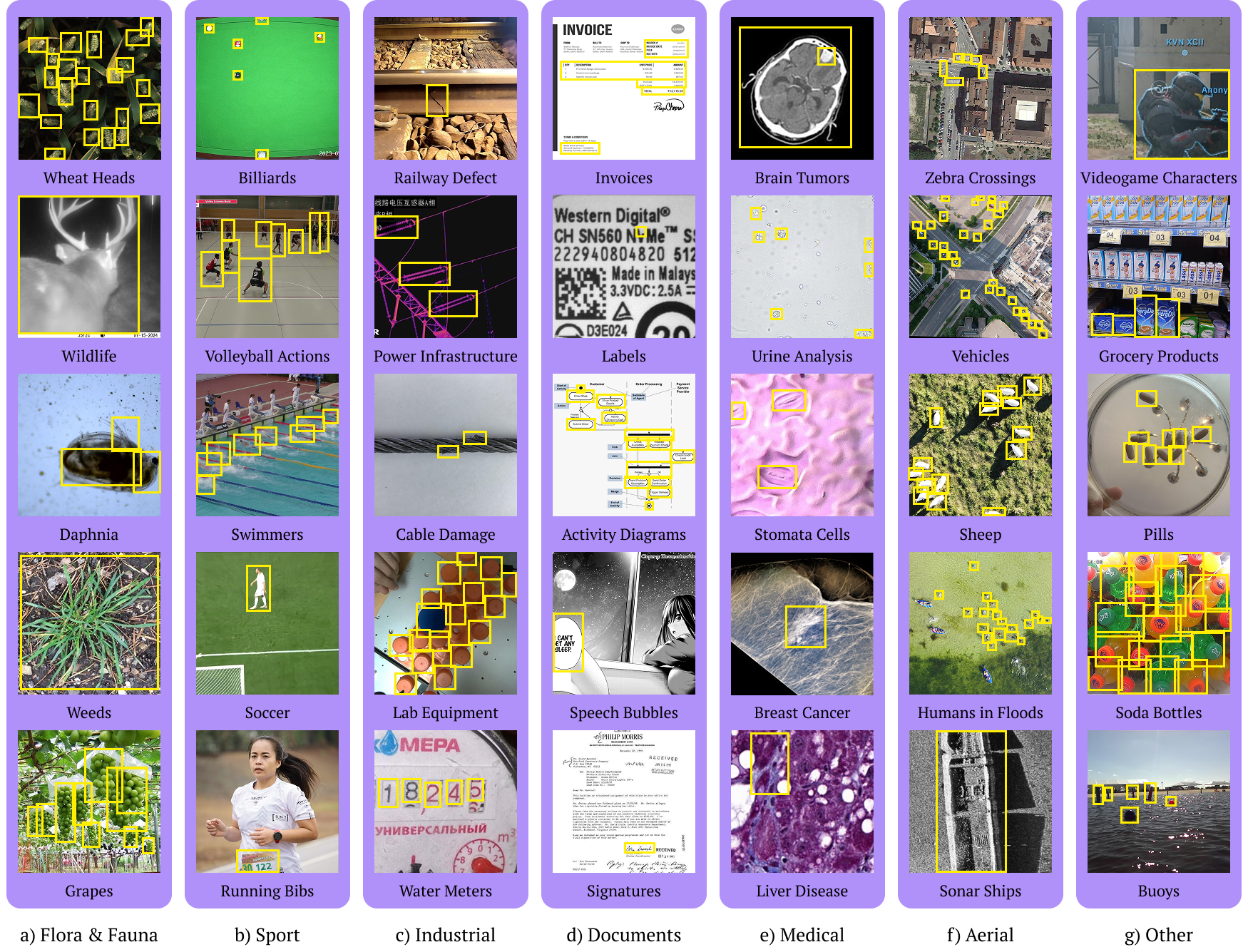
RF100-VL (Roboflow 100 Vision-Language)
RF100-VL is a benchmark derived from the Roboflow 100 object detection dataset, specifically adapted for evaluating Vision-Language Models (VLMs). It consists of 100 distinct datasets covering diverse domains (medical imagery, aerial views, games) that are generally absent from large pre-training corpora like COCO. It tests a VLM's ability to adapt to new, specific concepts, zero-shot, few-shot, and supervised detection tasks.
- Research Paper: Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models.
- Modalities: Images, Textual Instructions, and Bounding Boxes.
- Typical Tasks: Zero-shot object detection, few-shot transfer learning, open-vocabulary detection.
- Size: 164,149 images across seven domains, including aerial and medical imagery.
- Access: Available via Roboflow GitHub.
- Significance: Designed to test vision-language models on out-of-distribution concepts not commonly found in web-scale pre-training data.
LLaVA-Instruct-150K
LLaVA-Instruct-150K is a dataset generated to train the LLaVA (Large Language and Vision Assistant) model. It consists of complex, multimodal data (instruction-following) generated by GPT-4 from COCO images and captions. It comprises three sections: conversations, detailed descriptions, and complex reasoning.

- Research Paper: Visual Instruction Tuning
- Modalities: Text and Images.
- Typical Tasks: Visual instruction tuning, multimodal chatbot training, and visual reasoning.
- Size: 158,000 instruction-following samples.
- Access: Available via Hugging Face.
- Significance: Foundational for building large multimodal models that can respond to natural language instructions regarding visual scenes.
OpenVid-1M
OpenVid-1M is a large-scale, high-quality text-to-video dataset designed to democratize video generation research. OpenVid-1M uses advanced VLM captioning to provide dense, descriptive textual prompts for high-resolution video clips, unlike web-scraped datasets with noisy captions.
- Research Paper: OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-Video Generation.
- Modalities: Video and Text (Detailed Captions).
- Typical Tasks: Text-to-video generation and high-definition video understanding.
- Size: 1 million text-video pairs with high aesthetic and high-resolution quality.
- Access: NJU-PCALab GitHub.
- Significance: It addresses the lack of high-quality video datasets by offering meticulously filtered, watermark-free clips for research in video generation.
Vript
Vript stands for Video Script, which is a fine-grained video captioning dataset that focuses on long-form, script-like descriptions. It is constructed to provide "dense" annotations where every event in a video is described in detail, including voice-overs and subtitles. It targets the problem of "short caption bias" in existing datasets, where complex videos are reduced to simple sentences.
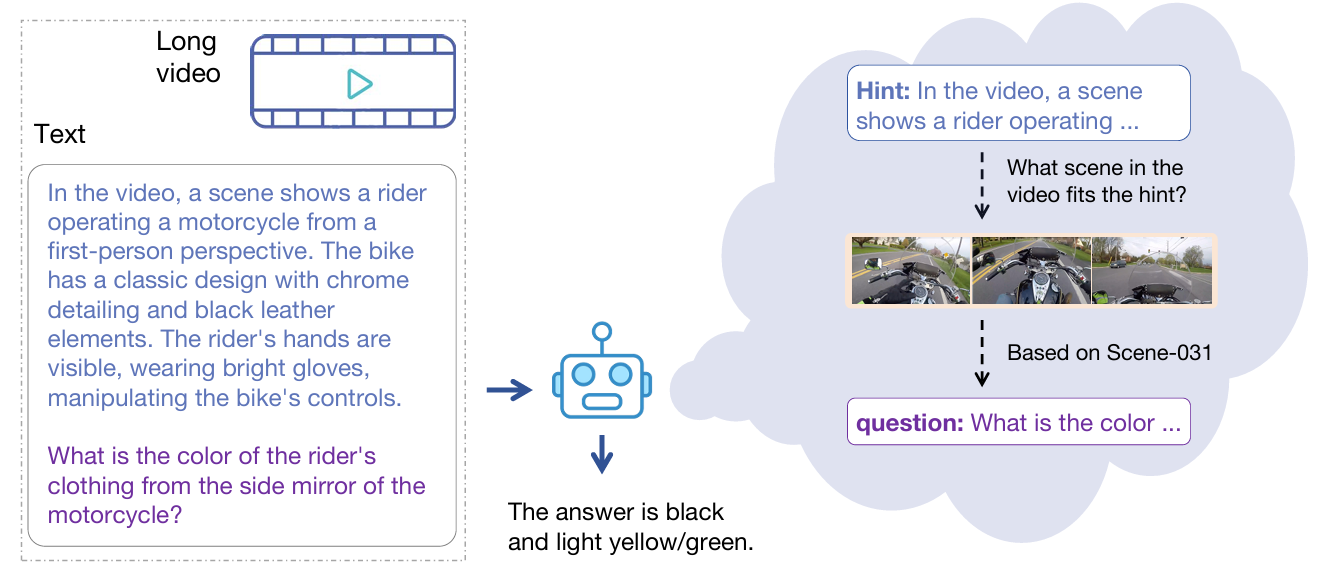
- Research Paper: Vript: A Video Is Worth Thousands of Words
- Modalities: Video, Audio (Voice-over), Text (Script-style dense captions).
- Typical Tasks: Dense video captioning, long-video understanding, video question answering, and temporal event re-ordering.
- Size: 12,000 high-resolution videos divided into 420,000 densely annotated clips.
- Access: Publicly available via Hugging Face.
- Significance: It is critical for training models that can understand temporal progression and nuance. It enables AI to comprehend cause-and-effect relationships and detailed actions, for example, “The chef chops the onion finely before adding it to the pan," rather than just "cooking."
VQA v2
VQA v2 is the second iteration of the Visual Question Answering dataset, released to fix biases in version 1. In VQA v1, models could often guess the answer without looking at the image (answering "2" to any "How many..." question).
VQA v2 balances the dataset so that for every question, there are two similar images with different answers and forces the model to actually rely on visual evidence.

- Research Paper: Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
- Modalities: Images and Textual Questions.
- Typical Tasks: Open-ended visual question answering.
- Size: Over 1.1 million questions about 265,016 images.
- Access: Available via the VisualQA website.
- Significance: An improved version of the original VQA dataset, it features more balanced image-question pairs to prevent models from guessing answers through language bias.
ActivityNet Captions
ActivityNet Captions is a benchmark for dense video captioning. It involves untrimmed videos containing multiple distinct events. Its goal is to localize (timestamp) each event and generate a description for it. It also connects temporal action localization with natural language generation.
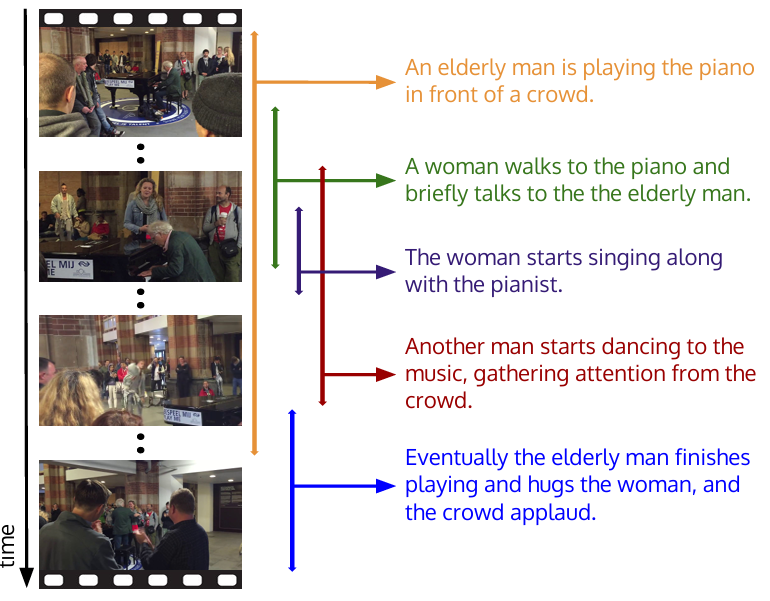
- Research Paper: Dense-Captioning Events in Videos
- Modalities: Video, Text (Temporally localized sentences)
- Typical Tasks: Dense Video Captioning, Temporal Action Localization, Paragraph Generation
- Size: 20,000 videos, 100,000 descriptive sentences
- Access: Publicly available via the ActivityNet website and on Huigging Face.
- Significance: It moved the field beyond "single clip, single label" classification. It drives research into models that can understand long, complex sequences of actions and narrate them coherently.
LAION-5B
LAION-5B is an open-source dataset consisting of 5.85 billion CLIP-filtered image-text pairs. It is one of the largest publicly accessible datasets in existence. Created by parsing Common Crawl data, it is designed to replicate the scale of proprietary datasets (like those used by OpenAI) for the open-research community.

- Research Paper: LAION-5B: An open large-scale dataset for training next generation image-text models.
- Modalities: Image (URLs), Text (Alt-text/Captions)
- Typical Tasks: Large-Scale Pre-training (CLIP, Stable Diffusion), Image-Text Retrieval, Generative Image Synthesis
- Size: 5.85 billion image-text pairs
- Access: Publicly available via Hugging Face.
- Significance: LAION-5B made it possible for everyone to train huge AI models. Before this, only big tech companies had the necessary data for models like DALL-E or CLIP. But LAION enabled the open-source community to create models such as Stable Diffusion and OpenCLIP, which have completely changed how we create generative AI.
VoxBlink2
VoxBlink2 is a massive-scale audio-visual speaker recognition dataset. It expands on the original VoxBlink by using an automated pipeline to mine data from YouTube. It focuses on capturing "blinking" (short, dynamic) moments of speakers.
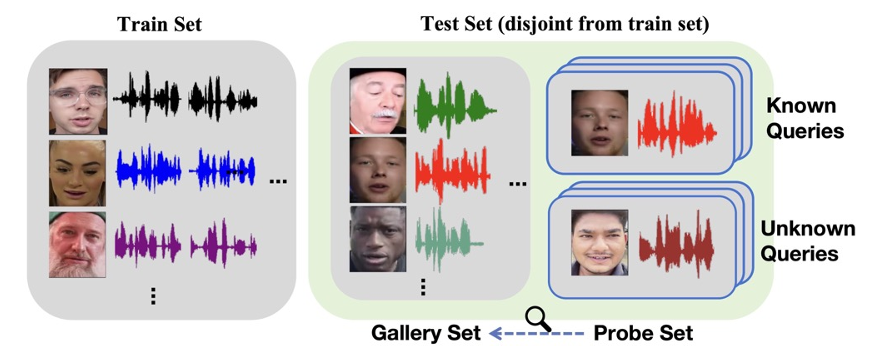
- Research Paper: VoxBlink2: A 100K+ Speaker Recognition Corpus and the Open-Set Speaker-Identification Benchmark.
- Modalities: Audio-Visual (Speech and Video).
- Typical Tasks: Open-set speaker identification and biometric verification.
- Size: Over 10 million utterances from over 111,000 speakers, totaling 16,672 hours.
- Access: Available for research use on GitHub.
- Significance: It sets a new scale for biometric research. It enables training ultra-large-scale verification models and introduces new benchmarks for open-set identification by scaling to over 100,000 identities (an order of magnitude larger than VoxCeleb).
Conclusion
Multimodal data fuses different modalities to give AI a richer set of inputs that better reflect the real world. It leads to more accurate models and a more comprehensive understanding of complex environments.
But, building multimodal AI systems also requires overcoming challenges: aligning data streams in time and space, handling heterogeneous formats, and investing in enough storage and compute to process diverse inputs.
Ensuring data quality is critical, and the payoff is huge. Multimodal AI models consistently outperform unimodal ones and unlock new applications from augmented reality to medical analytics.

