

For the past few months, we've been crafting an educational series on the best resources for learning and using AI, ML, and Computer Vision. This series includes articles on top open-source computer vision models, computer vision courses, computer vision blogs, AI podcasts, and more. Continuing this effort, we're now offering an overview of the top ten open-source datasets for machine learning, with a primary focus on computer vision.

Computer Vision Posts | Unitlab Annotate
Open source has been a game-changer in technology, evolving from Linux to programming languages, deep learning algorithms, and now, accessible open-source datasets available on platforms like Kaggle, Papers with Code, and Hugging Face. These diverse datasets cater to countless applications, allowing learners, independent engineers, and researchers to make significant strides.
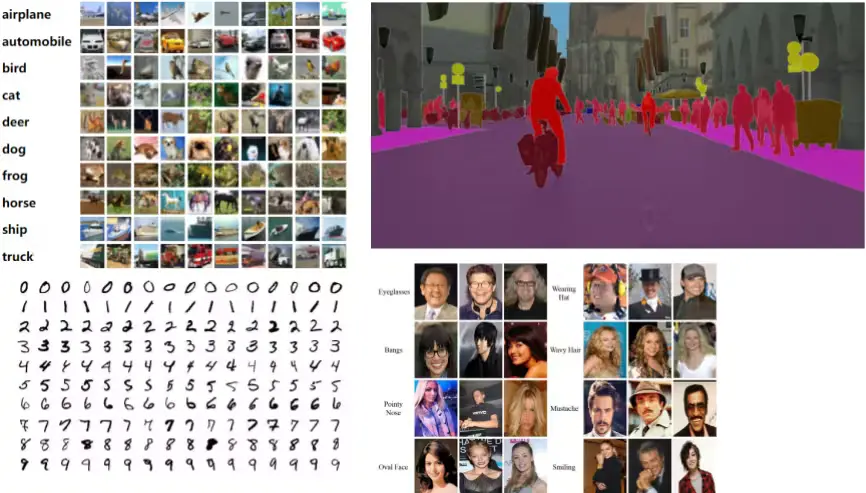
Below, we'll highlight ten prominent open-source datasets for computer vision, each focusing on different aspects of AI and ML!
Datasets
1. SA-1B Dataset
The SA-1B dataset boasts 11 million diverse, high-quality images with 1.1 billion pixel-perfect annotations, making it an ideal resource for training and evaluating advanced computer vision models.

The SA-1B (Segment Anything 1 Billion) dataset, developed by Meta AI, marks a monumental leap in computer vision, particularly for image semantic segmentation. With over 11 million varied images and 1.1 billion segmentation masks, it stands as the largest dataset for this specific task.
This dataset was designed for diversity and inclusivity, featuring examples from all domains, objects, people, and nations, truly a golden standard. Its immense scale and variety enable the training of highly robust and generalizable segmentation models. No doubt why the very popular SAM (Segment Anything Model) was trained on this dataset.
- Focus: Semantic Segmentation
- Research Paper: Segment Anything
- Authors: Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
- Dataset Size: 11 million images, 1.1 billion masks, 1500*2250 image resolution
- License: Limited; Research purpose only
- Access Link: Official Webpage
2. VisualQA
The Visual Question Answering (VQA) dataset includes over 260,000 images depicting abstract scenes from COCO, each with multiple questions and answers, alongside an automatic evaluation metric. This dataset challenges ML models to combine vision, language, and common knowledge to comprehend images and respond to open-ended questions.

Visual Question Answering (VQA) is a complex task that merges computer vision and natural language processing. The VisualQA dataset provides a rich collection of images paired with natural language questions and their corresponding answers. It encourages models to grasp both visual content and linguistic subtleties to provide accurate responses.
This dataset is perfect for training NLP models that need to interact with visual data.
- Focus: Image Understanding, Multi-modal Reasoning
- Research Paper: VQA: Visual Question Answering
- Authors: Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Dhruv Batra, Devi Parikh
- Dataset Size: 265,016 images
- License: CC By 4.0
- Access Links: Official Webpage, Pytorch Dataset Loader
3. ADE20K
The ADE20K dataset features over 25,000 diverse and densely annotated images, serving as a key benchmark for developing computer vision models focused on semantic segmentation.

The ADE20K dataset, created by the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL), is another comprehensive scene parsing benchmark, offering pixel-level annotations for a wide array of scenes and objects. It contains more than 20,000 images with detailed segmentation masks for objects and their parts, making it invaluable for training models that need to understand the composition of complex visual scenes.
- Focus: Semantic Segmentation
- Research Paper: Scene Parsing Through ADE20K Dataset
- Authors: Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, Antonio Torralba
- Dataset Size: 25,574 training images, 2,000 validation images
- License: CC BSD-3 License Agreement
- Access Links: Official Webpage, Detectron2
4. YouTube-8M
YouTube-8M is a large-scale video dataset comprising 7 million YouTube videos annotated with visual and audio labels for various machine learning tasks.
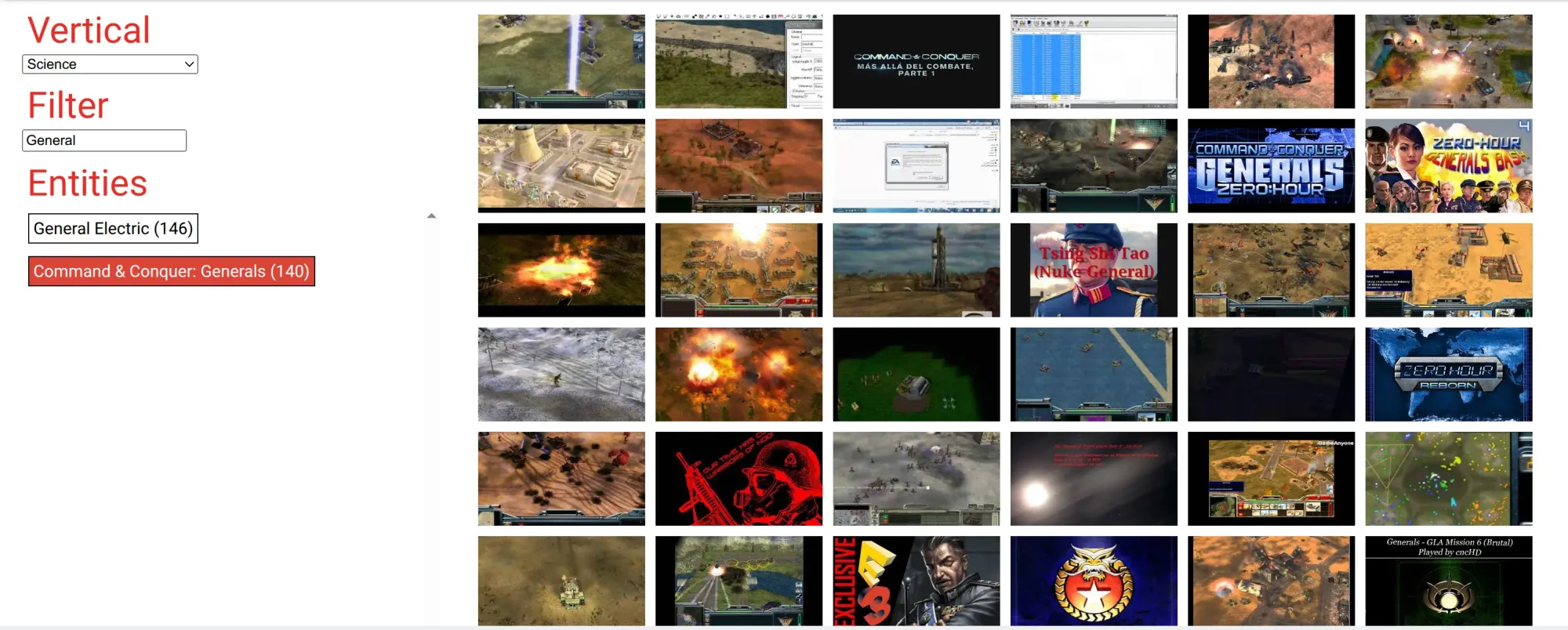
This video dataset was designed specifically for video understanding and classification. It includes millions of YouTube video IDs with segment-level labels drawn from a rich vocabulary of 4,716 classes.
Essentially, you can find videos on almost any topic you need. For instance, we tested it by searching for a popular RTS game from 2003. Its massive size and variety make it well-suited for training powerful video analysis models.
- Focus: Video Understanding, Action Recognition
- Research Paper: YouTube-8M: A Large-Scale Video Classification Benchmark
- Authors: Sami Abu-El-Haija, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, Sudheendra Vijayanarasimhan
- Dataset Size: 7 million videos with 4716 classes
- License: CC By 4.0
- Access Link: Official Webpage
5. Google's Open Images
Google's Open Images is a publicly accessible dataset providing 8 million labeled images, offering a valuable resource for diverse computer vision tasks and research.

Google's Open Images dataset is an expansive collection of images featuring rich annotations, including image-level labels, object bounding boxes, object segmentation masks, and visual relationships.
- Focus: Object Detection, Image Classification
- Research Paper: The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
- Authors: Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, Vittorio Ferrari
- Dataset Size: 8 million images
- License: CC By 4.0
- Access Link: Official Webpage
6. MS Coco
MS COCO (Common Objects in Context) is a widely used large-scale dataset featuring 330,000 diverse images with extensive annotations for object detection, segmentation, and captioning.

This popular dataset contains a large number of images with annotations for common objects found in their natural environments, including bounding boxes, segmentation masks, and five descriptive captions per image. Many foundational computer vision models have been developed using the MS COCO dataset.
- Focus: Object Detection, Image Captioning, Segmentation
- Research Paper: Microsoft COCO: Common Objects in Context
- Authors: Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan C., Lawrence Zitnick, Piotr Dollar
- Dataset Size: 330,000 images, 1.5 million object instances, 80 object categories, and 91 stuff categories
- License: CC By 4.0
- Access Links: Official Webpage, PyTorch, TensorFlow
7. CT Medical Images
The CT Medical Image dataset is a small sample drawn from the Cancer Imaging Archive, specifically selected for meeting certain criteria regarding age, modality, and contrast tags.
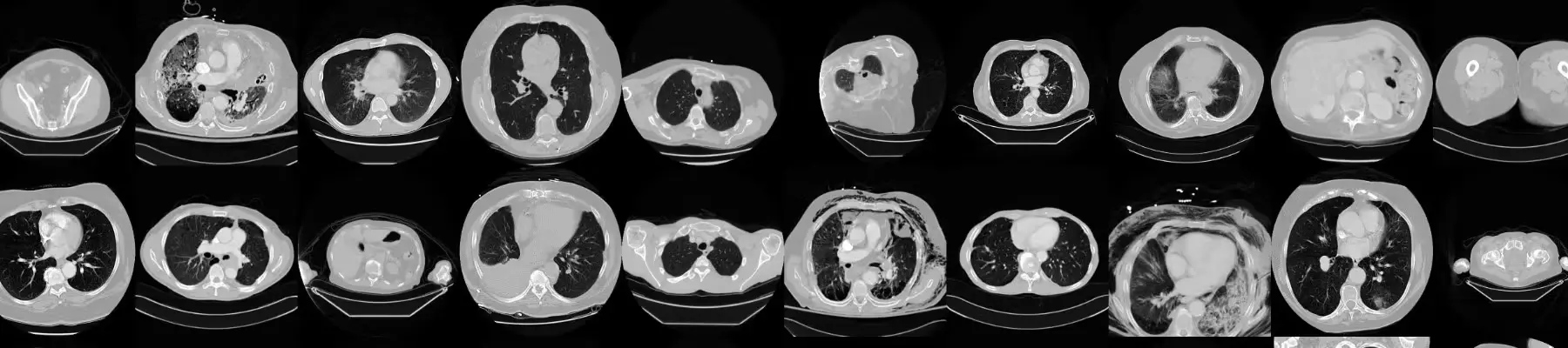
This dataset is designed to train models that can recognize image textures, statistical patterns, and highly correlated features. This capability allows for the development of straightforward tools to automatically classify misclassified images and identify outliers. Such outliers might indicate suspicious cases, inaccurate measurements, or inadequately calibrated machines in cancer treatment.
- Focus: Medical Image Analysis
- Research Paper: The Cancer Genome Atlas Lung Adenocarcinoma Collection
- Author: Justin Kirby
- Dataset Size: 475 series of images collected from 69 unique patients.
- License: CC By 3.0
- Access Link: Kaggle
8. Aff-Wild2
The Aff-Wild2 dataset comprises 564 videos, totaling approximately 2.8 million frames from 554 subjects, designed for the task of emotion recognition using facial images.

Aff-Wild2 is a challenging dataset for the automatic analysis of in-the-wild facial expressions and affective states. It contains videos of participants exhibiting a wide range of emotions and expressions (such as sadness, anger, and satisfaction) in unconstrained environments. These videos are richly annotated for valence, arousal, and discrete emotion categories.
- Focus: Emotion Recognition, Gesture Recognition
- Research Paper: Deep Affect Prediction in-the-wild: Aff-Wild Database and Challenge, Deep Architectures, and Beyond
- Authors: Dimitrios Kollias, Panagiotis Tzirakis, Mihalis A. Nicolaou, Athanasios Papaioannouk, Guoying Zhao, Bjorn Schuller, Irene Kotsia, Stefanos Zafeiriou
- Dataset Size: 564 videos of around 2.8 million frames with 554 subjects (326 of which are male and 228 female)
- License: Non-commercial research purposes
- Access Link: Papers with Code
9. DensePose-COCO
DensePose-COCO includes 50,000 images with dense human pose estimation annotations for each person in the COCO dataset, allowing for a detailed understanding of the human body's pose and shape.
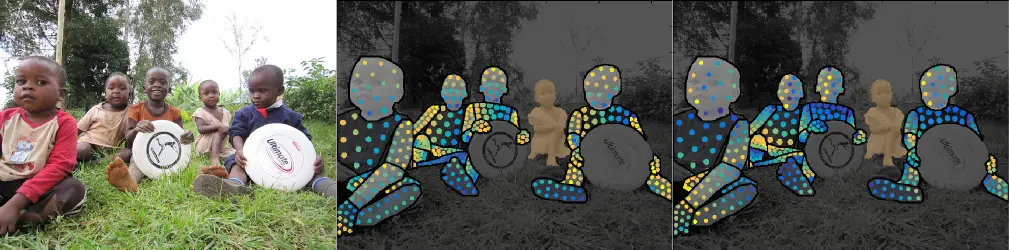
DensePose-COCO extends the MS COCO dataset by offering dense correspondence annotations between 2D images and a 3D surface model of the human body. This enables mapping every pixel of a human body in an image to a specific location on a 3D model, providing a fine-grained understanding of human pose and shape.
- Focus: Human Pose Estimation
- Research Paper: DensePose: Dense Human Pose Estimation In The Wild
- Authors: Riza Alp Guler, Natalia Neverova, Iasonas Kokkinos
- Dataset Size: 50,000 images from the COCO dataset, with annotations for more than 200,000 human instances
- License: CC By 4.0
- Access Link: Official Webpage
10. BDD100K
The BDD100K dataset is a large-scale, diverse driving video dataset containing over 100,000 videos.

BDD100K comprises 100,000 videos of diverse driving scenarios with rich annotations, including object bounding boxes, drivable areas, lane markings, and traffic lights. Its scale and variety make it ideal for training robust perception models for self-driving cars.
- Focus: Scene Understanding for Autonomous Vehicles
- Research Paper: BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning
- Authors: Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, Trevor Darrell
- Dataset Size: Over 100,000 driving videos (40 seconds each) collected from more than 50,000 rides, covering New York, San Francisco Bay Area
- License: Mixed license
- Access Links: Official Webpage, Papers with Code
Conclusion
These open-source datasets listed above are just a fraction of the valuable datasets available to the global machine learning and AI community. If you are a researcher, AI/ML engineer, or just a learner, you can use them to train, run, and test your AI/ML models and even implement on a smaller scale.
Their accessibility and richness have accelerated research and development across numerous industries, from computer vision and natural language processing to medical imaging and autonomous systems. Leveraging these datasets is crucial for building robust, generalizable, and high-performing machine learning models.
Explore More
For additional insights into datasets, check out these resources:
- Dataset Version Control in 2026
- How to Make Ideal Datasets: Best Practices in 2026
- Dataset Management at Unitlab AI [2026]
References
- Akruti Acharya (Jun 27, 2023). Top 10 Open Source Datasets for Machine Learning. Encord Blog: Source
- Michael Abramov (Feb 9, 2024). Best Datasets for Training Semantic Segmentation Models. Keymakr Blog: Source

![Low-Code and No-Code Tools for Data Annotation with Demo Projects [2026]](/content/images/size/w360/2025/12/no-code.png)