Text is everywhere. Emails, chat logs, PDFs, web pages, logs, and scanned documents all carry business-critical information, but most of it is locked inside unstructured text. Databases and automation pipelines, however, need structured fields to extract value.
Named Entity Recognition (NER) sits exactly at this boundary. It converts free-form language into structured data that other systems can use for search, analytics, decision rules, and machine learning.
In practice, NER is rarely used alone. It usually feeds into larger pipelines that include OCR, document layout models, classifiers, and entity linking, all of which fall under Natural Language Processing (NLP).
In this article, I focus on how NER is used in real systems across industries, with examples from finance, healthcare, legal, and analytics.
Let’s get started.
What is Named Entity Recognition?
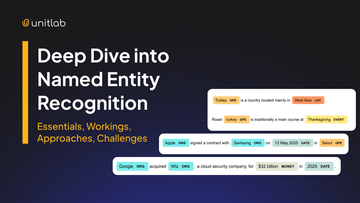
Named Entity Recognition is the task of detecting and classifying spans of text that refer to real-world objects, concepts, or identifiers. These spans are labeled with predefined entity types such as PERSON, ORG, DATE, MONEY, or domain-specific categories like KPI in finance or DRUG in medicine.
Take this example sentence: “Google acquired Wiz, a cloud security company, for $32 billion in 2025.”
A general NER model would extract:
- Google → ORG
- Wiz → ORG
- $32 billion → MONEY
- 12 May 2025 → DATE

Technically, NER is treated as a sequence labeling problem where each token receives a tag indicating whether it starts, continues, or lies outside an entity span. Most modern systems use transformer models fine-tuned for token classification, though rules and classical ML still play a role in narrow, highly structured domains.
NER alone does not provide full understanding. It tells you what entities appear, but not how they relate, whether two mentions refer to the same object, or how values should be normalized. That is why NER is commonly paired with relation extraction, entity linking, and domain-specific post-processing.
NER Patterns Across Industries
Across industries, NER rarely runs as a standalone component. By itself, entity extraction does not drive decisions. Instead, it is part of pipelines that include OCR, document classification, normalization, and linking. NER turns text into fields that downstream systems can actually use.
Even with the right schema, model output is rarely usable as-is. Predictions still go through validation, formatting, deduplication, normalization, and database matching. In many production systems, this glue logic takes more engineering time than model training itself. This is what turns predictions into reliable inputs.
Models also improve through iteration. After deployment, teams review errors, label new examples, and retrain. This loop is known as active learning or dataset iteration. It is how systems adapt to new wording, products, and document formats over time.
Role of Data Annotation in NER Applications
Most real-world NER systems depend on supervised learning with domain-specific data. Even with large pretrained transformers, performance depends on whether training examples match production text and entity types.
Pretraining teaches general language patterns. Fine-tuning teaches what your entities look like, how boundaries are defined, and which categories matter. Without custom labeled data, models usually detect only generic entities and miss business-critical fields like invoice numbers, drug dosages, or vulnerability identifiers. You get a model that is a Jack of all trades, but a master of none.
Text Entity Detection (NER) Annotation at Unitlab AI
Because many domain entities rarely appear in public datasets, they must be introduced through custom data annotation. That is why finance, healthcare, legal, and cybersecurity NER systems almost always rely on datasets created with domain experts.
Quality also matters more than volume. A few thousand consistent samples often outperform much larger noisy datasets, especially when some entities are rare but important, such as fraud indicators or rare diagnoses.
For these reasons, data labeling is not a one-time setup step. It becomes part of an ongoing loop that keeps models aligned with real data.
Industry-Specific NER Applications
Below is a summary table for NER Applications:
| Use Case | Short Info | Model Examples (Open Source) |
|---|---|---|
| Financial Document Processing | Invoices, amounts, vendors, dates | FinBERT, LayoutLMv3 |
| Customer Support Tickets | Products, order IDs, error codes | dslim/bert-base-NER |
| Legal Tech | Parties, clauses, jurisdictions | LegalBERT |
| Clinical NLP | Drugs, symptoms, procedures | BioBERT, ClinicalBERT |
| News Monitoring | People, orgs, locations, events | XLM-RoBERTa NER |
| Search & Recommendation | Brands, products, locations | RoBERTa NER |
| Knowledge Graph Construction | Entity nodes before relation extraction | RoBERTa NER |
| Resume Screening / HR | Skills, titles, companies | BERT fine-tuned on CV data |
| E-commerce Review Mining | Product features and defects | RoBERTa NER, BERT fine-tuned on reviews |
| Cybersecurity & Logs | IPs, CVEs, malware names | spaCy NER + regex, BERT fine-tuned on threat reports |
| Document AI (Multimodal) | OCR + layout + entity extraction | LayoutLMv3 |
Let's cover each one in detail.
1. Financial Document Processing
Financial workflows depend on structured fields inside PDFs or scanned documents. Typical inputs include invoices, receipts, bank statements, and purchase orders.
Common entity types are vendor name, invoice number, amount, currency, tax ID, issue date, and due date. For example, “Invoice No: INV-20391, Total: €4,250.00, Due: 15 March 2026”.
A finance-specific NER model would likely output this:
[Invoice No]_(FIELD): [INV-20391]_(INVOICE_ID),
[Total]_(FIELD): [€4,250.00]_(MONEY),
[Due]_(FIELD): [15 March 2026]_(DUE_DATE)

NER output feeds accounting systems, expense platforms, analytics dashboards, and ERP ingestion pipelines. These systems often combine OCR with layout-aware models so that text position helps identify fields. Mistakes directly affect financial records, so validation and rule-based checks are just as important as the model itself.
FinBERT and layout-aware transformers like LayoutLMv3 are commonly used starting points.
2. Customer Support Ticket Application
Support systems process large volumes of emails, chats, and web forms. Entity types vary widely: product names, order IDs, device models, error codes, and locations.
For instance, “My iPhone 18 overheats and shows error E204 after update.” A model fine-tuned for customer support ticketing systems would probably show this:
My [iPhone]_(PRODUCT) [18]_(MODEL) [overheats]_(ISSUE)
and shows [error E204]_(ERROR_CODE) after [update]_(EVENT).

NER extracts technical context before classification and routing. Combined with intent detection, it enables faster triage and automated replies. Analytics teams also use entity statistics to identify frequent failures by product or region.
Because language is informal and inconsistent, transformer models fine-tuned on real tickets usually outperform rule-based pipelines. The scope of this usage means there is no single model for customer support ticketing.
3. Legal Tech
Legal documents are long and highly structured. Common entity types include party names, contract clauses, jurisdictions, dates, and legal references.
For example, this statement, “This Agreement is entered into by Alpha Ltd. and Beta Corp under the laws of Singapore.”, would likely be annotated this way by an NER model:
This [Agreement]_(CONTRACT_TYPE) is entered into by
[Alpha Ltd.]_(PARTY) and [Beta Corp]_(PARTY)
under the laws of [Singapore]_(JURISDICTION).

By comparison, a general-purpose NER model, such as spaCy, would result in this general-purpose annotation:
This Agreement is entered into by [Alpha Ltd.]_(ORG) and
[Beta Corp]_(ORG) under the laws of [Singapore]_(GPE).

Legal technology research uses NER to extract clause boundaries, litigant names, case citations, and verdict details from legal texts. Researchers even compared different NER approaches (rule-based, deep generative, and deep discriminative models) for legal norm analysis in German.
Because law is (and must be) a precise science, annotation guidelines must be extremely strict, and hybrid pipelines are common to enforce legal formatting rules.
LegalBERT, a fine-tuned BERT on legal corpora, is the most popular open-source deep learning model used for NER tasks in the legal documents.
4. Clinical NLP
Medical text contains narrative descriptions mixed with technical terminology. Entity types include symptoms, diagnoses, drugs, dosages, procedures, and lab values. An example clinical text might look like this: “Patient reports chest pain, started on aspirin 81 mg daily.”
A medical-domain specific NER model would output this labeled text:
Patient reports [chest pain]_(SYMPTOM), started on
[aspirin]_(MEDICATION) [81 mg]_(DOSAGE) [daily]_(FREQUENCY).

NER supports clinical decision systems, research cohort selection, and billing automation. Vocabulary is specialized, and privacy limits data sharing, which makes annotation slow and expensive. AWS offers a real cloud service, Amazon Comprehend Medical - healthcare NLP, to annotate medical data for NER.
General NER models usually perform poorly without domain fine-tuning, obviously. Fortunately, BioBERT and ClinicalBERT are available for use for medical NER.
5. News Monitoring and Media Intelligence
Media analysis depends on tracking entities across large article streams. Media covers almost everything, but notable entity types are people, organizations, locations, and events. A major news headline might look like this: “On 23 November 2025, representatives of the United States and Ukraine met in Geneva for discussions on the U.S. peace proposal.”
A NER model fine-tuned for media intelligence might provide this annotated result:
On [23 November 2025]_(DATE), representatives of
the [United States]_(COUNTRY) and [Ukraine]_(COUNTRY)
met in [Geneva]_(LOCATION) for discussions on the
[U.S. peace proposal]_(POLICY).

NER enables entity-centric indexing, trend detection, and narrative analysis. It is usually followed by entity linking so that multiple mentions of the same entity are merged. Multilingual transformers are often required in global news pipelines.
6. Search and Recommendation Systems
Search quality improves when systems understand what users are actually referring to and what particular search results actually mean. These systems encompass a very wide range of entities as search queries can be about anything. Most common types include: brands, products, locations, categories.
An example search query can be “cheap hotels near Istanbul airport”. A search algorithm likely first uses NER to understand the query and work towards detecting its intent:
[cheap]_(PRICE_TIER) [hotels]_(LODGING_TYPE)
[near]_(PROXIMITY) [Istanbul airport]_(LOCATION)

NER helps identify location, service type, and price intent. This supports entity-based retrieval rather than keyword matching, which improves ranking and personalization. In travel and e-commerce, this directly affects conversions.
No specific open-source model is used for this task, because this domain has sub-domains. In practice, RoBERTa NER is usually fine-tuned for different domains.
7. Knowledge Graph Construction
Knowledge graphs store entities and relationships in structured form. NER creates nodes. Relation extraction connects them. These graphs are then used for smarter search, personalized recommendations, and supply-chain improvements.
Entity types can be of any nature, but common ones include companies, people, technologies, locations, products. For instance, “OpenAI partnered with Microsoft to deploy cloud infrastructure.”
Assuming NER and entity linking are done, we can quite easily create a knowledge graph with Python.
First, install networkx and matplotlib in your virtual environment and import them at top:
import matplotlib.pyplot as plt
import networkx as nx
Now, put entities and relations inside a Python list in a format networkx expects:
entities = [
{"id": "org:openai", "text": "OpenAI", "type": "ORG"},
{"id": "org:microsoft", "text": "Microsoft", "type": "ORG"},
{"id": "asset:cloud_infra", "text": "cloud infrastructure", "type": "TECH_ASSET"},
]
relations = [
{
"source": "org:openai",
"target": "org:microsoft",
"type": "PARTNERED_WITH",
"evidence": "OpenAI partnered with Microsoft",
},
{
"source": "org:openai",
"target": "asset:cloud_infra",
"type": "DEPLOYED_FOR",
"evidence": "to deploy cloud infrastructure",
},
{
"source": "org:microsoft",
"target": "asset:cloud_infra",
"type": "DEPLOYED_FOR",
"evidence": "to deploy cloud infrastructure",
},
]
Now finally, use networkx to draw the knowledge graph:
pos = nx.spring_layout(G, seed=7)
nx.draw(G, pos, with_labels=False, node_size=2200)
nx.draw_networkx_labels(G, pos, labels={n: G.nodes[n]["label"] for n in G.nodes})
nx.draw_networkx_edge_labels(
G, pos, edge_labels={(u, v): G.edges[u, v]["type"] for u, v in G.edges}
)
Now export the graph to PNG and .graphml format:
plt.savefig("kg.png", dpi=200, bbox_inches="tight")
print("Saved: kg.png")
nx.write_graphml(G, "kg.graphml")
print("Saved: kg.graphml")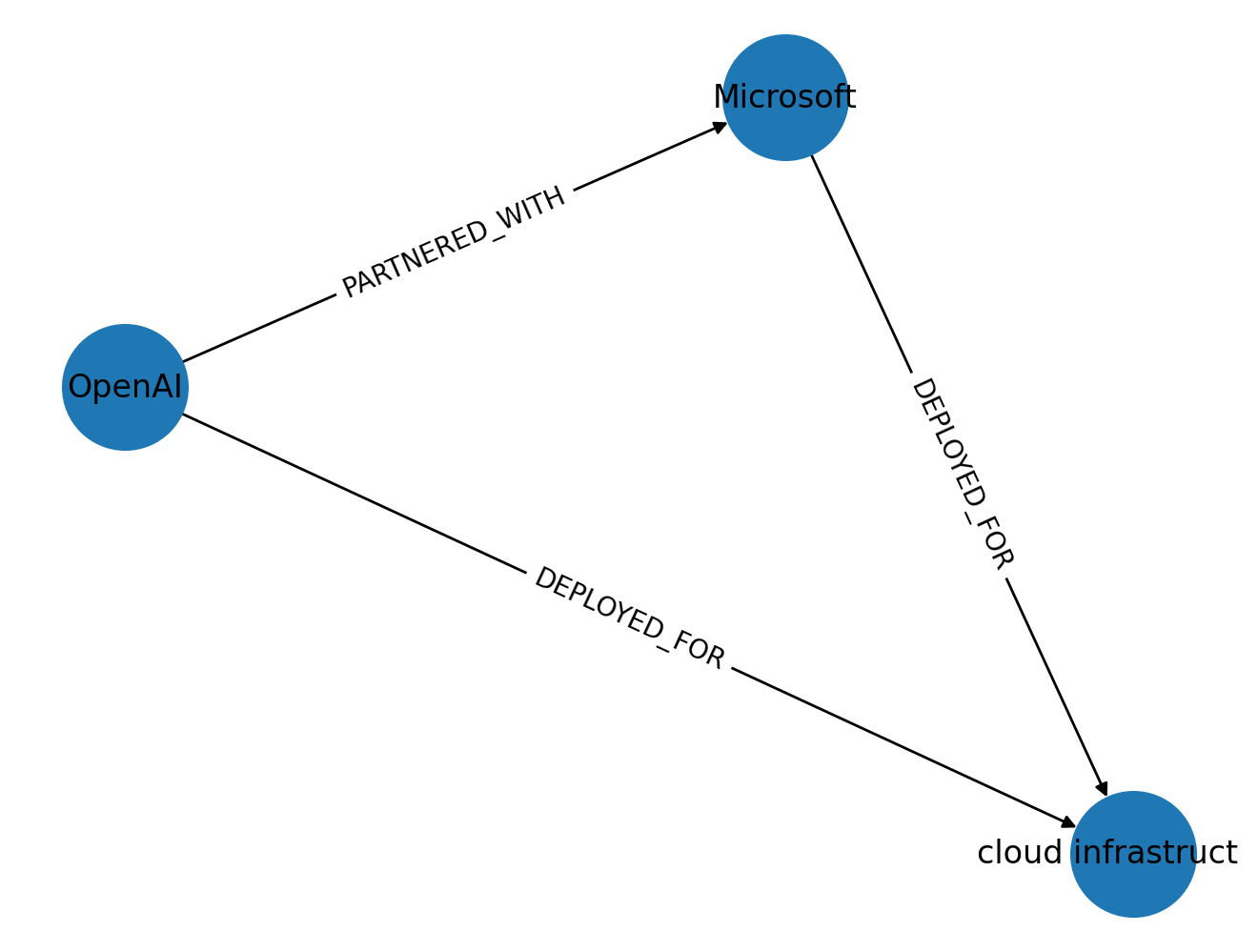
In the end, we get this simple graph relation. With NER and entity linking, you can create very complex relations and graphs. This pipeline supports enterprise analytics, recommendations, and question-answering systems.
8. Resume Screening and HR Analytics
Recruitment platforms process resumes, profiles, and job descriptions automatically. Traditionally, they used rule-based approaches, but now increasingly utilize deep learning methods. Main entity types consist of skills, job titles, companies, degrees, certifications, dates.
For example, my own CV include these lines: “Growth engineer at Unitlab AI, BSc (Hons) in Finance, Python, SQL, Django”. An NER model fine-tuned for HR would possibly annotate it this way:
[Growth engineer]_(JOB_TITLE) at [Unitlab AI]_(COMPANY),
[BSc (Hons)]_(DEGREE) in [Finance]_(FIELD_OF_STUDY),
[Python]_(SKILL), [SQL]_(SKILL), [Django]_(SKILL)

NER enables structured candidate profiles, skill matching, and ranking.
However, skill normalization and synonym handling become major challenges, especially across regions and industries. Bias control also matters here, so entity design must avoid encoding sensitive attributes, such as age, religion, nationality, and gender.
9. E-commerce Catalog and Review Mining
User reviews contain rich product feedback and user sentiment but in informal language with much jargon. Entity types can be product variants, features, defects, accessories. For example, a user might leave a review on a website: “The battery on the Pro Max version of iPhone 18 drains fast after update.”
NER deep-learning models would handle it this way:
The [battery]_(PRODUCT_LINE) on the [Pro Max]_(MODEL_VARIANT)
version of [iPhone 18]_(PRODUCT) [drains fast]_(ISSUE)
after [update]_(EVENT).

NER enables feature-level sentiment analysis and product issue tracking. It also helps identify counterfeit listings and misleading descriptions. This domain is noisy, multilingual, and full of abbreviations, which makes transformer-based models preferable to rigid rule-based or statistical ML methods.
10. Cybersecurity and Log Analysis
Security systems process logs and threat reports. Logging refers to the automatic recording of all activities within a system. These logs contain a few number of specific entity types: IP addresses, file hashes, CVE IDs, malware names, usernames
Imagine that your NER model comes across this log: “Suspicious connection from 192.168.1.45 associated with CVE-2024-3094” It would recognize entities in this way:
[Suspicious]_(THREAT_INDICATOR) [connection]_(EVENT_TYPE) from
[192.168.1.45]_(IP_ADDRESS) associated with
[CVE-2024-3094]_(VULNERABILITY_ID).

Rule-based extraction handles strict formats, while ML models detect named malware families and campaigns. Hybrid pipelines are common because precision is critical.
11. Multimodal and Document AI Pipelines
Many business documents are not only plain text, but also visual as well. Inputs can range from scanned forms, IDs to shipping documents and contracts. In this environment, companies tend to use Multimodal AI applications that can handle images and textual information at the same time.

Guide to Multimodal AI
Common entities in the business world include names, addresses, ID numbers, signatures, dates inside images. NER here operates on OCR outputs and is combined with layout and vision models. Entities are often tied to specific regions on the page, not just text spans.
This setting requires alignment across text, layout, and visual features. After NER processing, its output becomes input for other NLP tasks, such as entity linking.
For your convenience, we made the example NER annotations a public dataset available on Unitlab AI. Create a free account under 5 minutes to access and use it.
You need a data annotation tool to handle domain-specific NER annotation but do not want to deal with all the overhead of project management? Then Unitlab AI is for you: a 100% automated data platform that provides collaborative annotation, model integration, and dataset management. Try it today.
Challenges When Deploying NER in Industry
Aside from technical problems that accompany model training, validation, deployment, debugging, and maintenance, Named Entity Recognition datasets and models have their own set of challenges.
First, language, terms, and meanings change over time. New words are added, replaced, or entirely removed. In the business, product names, regulations, and slang (headhunter? AI evangelist?, Chief Happiness Officer?) evolve. This causes domain drift and silent accuracy degradation that requires periodic updates, which is costly for large annotated corpora.
Additionally, schemas and taxonomy also change. New business requirements introduce new entity types or redefine boundaries. Shorter, catchy variations arise out of formal terms. Old datasets become partially obsolete.
Second, to use NER effectively across different languages, you need high-quality, consistent annotated corpora, which many languages still lack. Only a number of major languages, such as English, Arabic, Russian, have large labeled corpora. Cross-language NER is still limited.
Furthermore, ambiguity never disappears. General-purpose NER cannot distinguish between Apple (company name) and apple (fruit) accurately. Turkey (country) or turkey (bird)? Context and normalization logic remain necessary even with strong models.

Finally, annotation cost is high. Domain expertise is often required, especially in legal, medical, and financial settings.
Conclusion
NER turns free-form text into structured signals that systems can use. Its success depends not only on model architecture, but on how well schemas, annotation workflows, and post-processing match real operational needs.
Across industries, NER supports automation, analytics, compliance, and decision systems. While transformer models dominate extraction, production systems still rely on hybrid pipelines and continuous dataset updates.
Teams that treat NER as an evolving component, rather than a one-time model, build systems that stay reliable as data and language change.
Explore More
- Text Annotation with Unitlab AI with a Demo Project [2026]
- Top 5 Text Annotation Tools in 2026
- Named Entity Recognition: Essentials, Workings, Approaches, Challenges
References
- Alexandre Bonnet (Dec 19, 2024). What Is Named Entity Recognition? Selecting the Best Tool to Transform Your Model Training Data. Encord: Source
- Hojiakbar Barotov (Jan 17, 2026). Named Entity Recognition: Essentials, Workings, Approaches, Challenges. Unitlab: Source
- IBM (no date). What is named entity recognition? IBM Think: Source
- Partner Content (Sep 09, 2025). 10 Real-World Applications of Named Entity Recognition Across Industries. Techloy: Source