
![Text Annotation with Unitlab AI [2025]](/content/images/size/w2000/2025/12/text.png)
The first fact of life: a lot of textual data is generated every day through emails, social media, and other channels.
The second: around 80% of generated data is unstructured, meaning it is not in the form that computers generally understand.

To work with such big data effectively, we first need to train AI/ML models to understand, analyze, interpret, and act on it. This is where text annotation comes in. Text annotation involves assigning content to predefined categories to create high quality labelled data for machine learning.
This post explores the fundamentals of text labeling, why it matters, its types, and how you can get started with Unitlab AI.
By the end of this article, you’ll learn:
- text annotation essentials
- its importance and use cases
- types of text labeling
- how to annotate text
Let’s get started!
What is Text Labeling, Essentially?
Text labeling is the process of adding tags, categories, or notes to unstructured textual information. The goal is to make raw words understandable for machines and to train AI/ML to extract patterns from text. Text labeling tasks can involve assigning multiple labels to a single text item or performing document classification to organize documents by topic or domain.
Without this essential feature, natural language processing (NLP) models such as ChatGPT, chatbots, or document readers wouldn’t function effectively.
Examples of text annotation:
- Marking names, places, or organizations in a sentence (named entity recognition).
- Categorizing customer reviews as positive, neutral, or negative (text sentiment classification).
- Classifying news reports as finance, sports, or entertainment (text classification).
- Assigning multiple labels to a news article, such as both 'Politics' and 'Economy', to reflect its content more accurately (multiple labels).
- Grouping legal or medical documents into categories for compliance and analysis (document classification).
Essentially, text labeling transforms free-form emails, tweets, and news into structured training data for NLP models, and document classification and other text labeling tasks help organize large volumes of text.
Why Annotate Text?
You may wonder: why label textual information? Isn’t it self-evident? After all, we humans can read and analyze text almost unconsciously.
First, AI/ML systems (chatbots, voice assistants, and self-driving vehicles) are increasingly used in both business and non-business settings. The world is complex, and they require different types of data for training and development.
Second, textual information is not necessarily self-describing. The vast majority is unstructured, meaning that for computers it is no different than raw bits in memory, unless categorized and defined.
For these reasons, we annotate text. Accurate annotations and robust quality control processes are essential to ensure the reliability of labeled data for AI/ML systems. Here are two concrete examples:
NLP
Almost all texts must be considered with context and in relation to other texts. For example, “I am serious. And don’t call me Shirley” makes little sense on its own without background information. NLP is the field of computer science that teaches computers to understand and work with this complexity in human language.
Examples include virtual assistants (Siri, Alexa), search engines (Google, Bing), translation services (Google Translate), and website chatbots. We interact with them daily. The LLMs we use every day, ChatGPT, Gemini, or DeepSeek, are fundamentally based on NLP as well. Their training data is huge, with parameters in the billions.
With large, well-labeled datasets, NLP models can recognize intent, provide meaningful information, and perform accurate translations. Parsing sentences and training language models are fundamental steps in training machine learning models for NLP applications, as they enable systems to analyze linguistic structures, understand context, and improve performance.
Text labeling powers the creation of ML datasets for these NLP models and applications.
OCR
Optical character recognition (OCR) extracts text from scanned or handwritten images or documents (PDF, JPG, TIFF). It is often used alongside text annotation. While OCR turns images into plain text, text labeling makes that text meaningful for AI/ML models. Automatic data extraction and parsing from digital documents are the key application of combining OCR and text annotation.
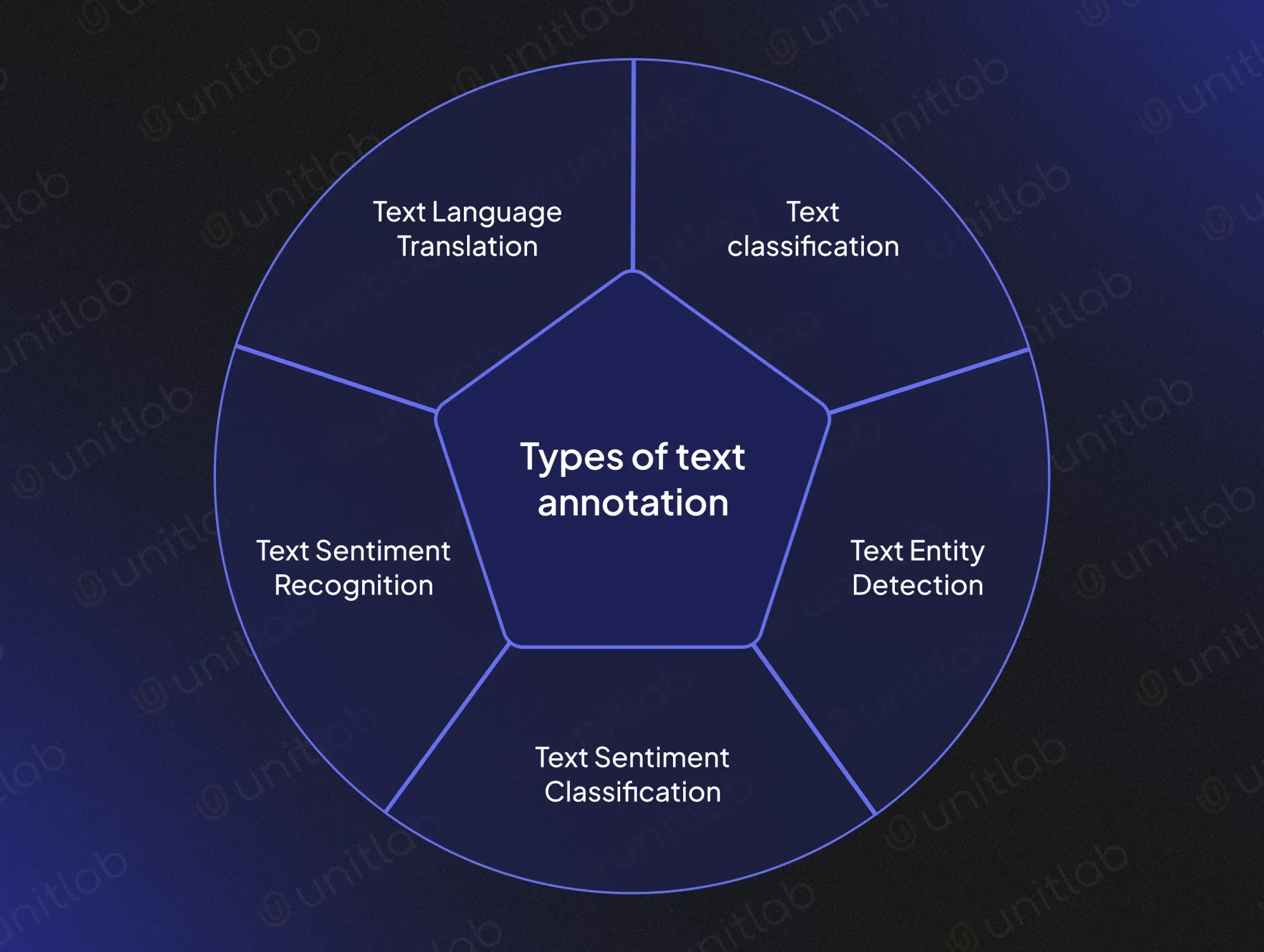
Types of Text Annotation
Naturally, we have different intents for our raw textual data. Therefore, different modes of text labeling have emerged to suit needs of AI/ML models. In the context of NLP annotation, specific annotation tasks often focus on extracting key concepts from text to support various applications such as content categorization, entity recognition, and summarization.
To illustrate, we'll use this Napoleon Bonaparte quote:
What a novel my life has been! I have fought sixty battles and I have learned nothing which I did not know at the beginning. Look at Alexander, Caesar, Hannibal, and me: we have all founded empires. But on what did these creations depend? On force. But force is transient. Only the ideas that have moved mankind remain.
—Napoleon Bonaparte
Text Entity Detection
This assigns entities in text to predefined labels based on meaning. Entity annotation and tagging entities are core components of linguistic annotation in NLP, as they involve labeling key phrases and named entities to enhance machine comprehension and support tasks like information extraction and model training. This may identify entity names, dates, numbers, places, and other arbitrary names. It includes:
- Named entity recognition (NER): Labels key information such as people, places, or dates.

- Relationship annotation: Maps entities in the text that refer to the same object (e.g., I/me).
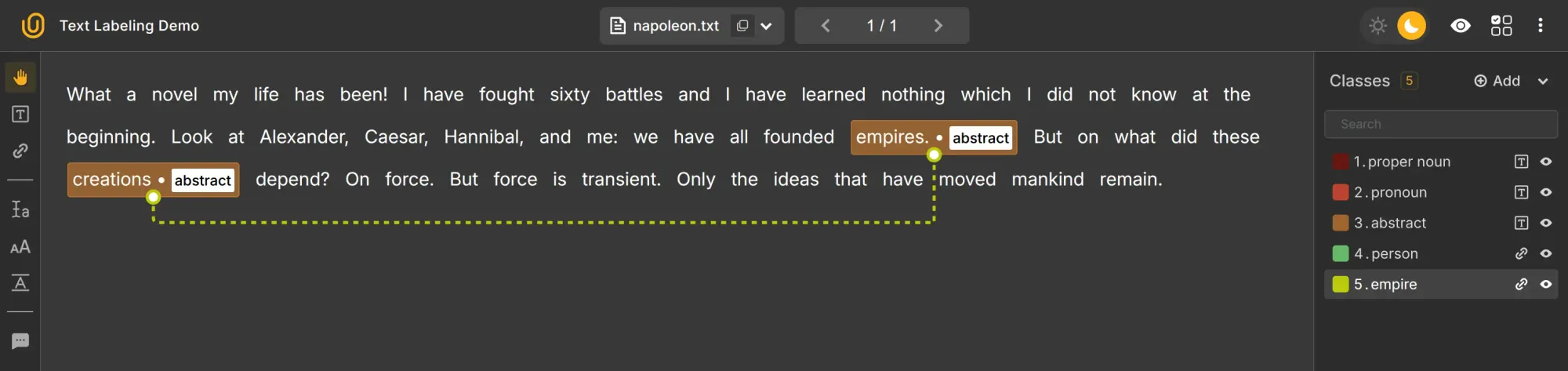
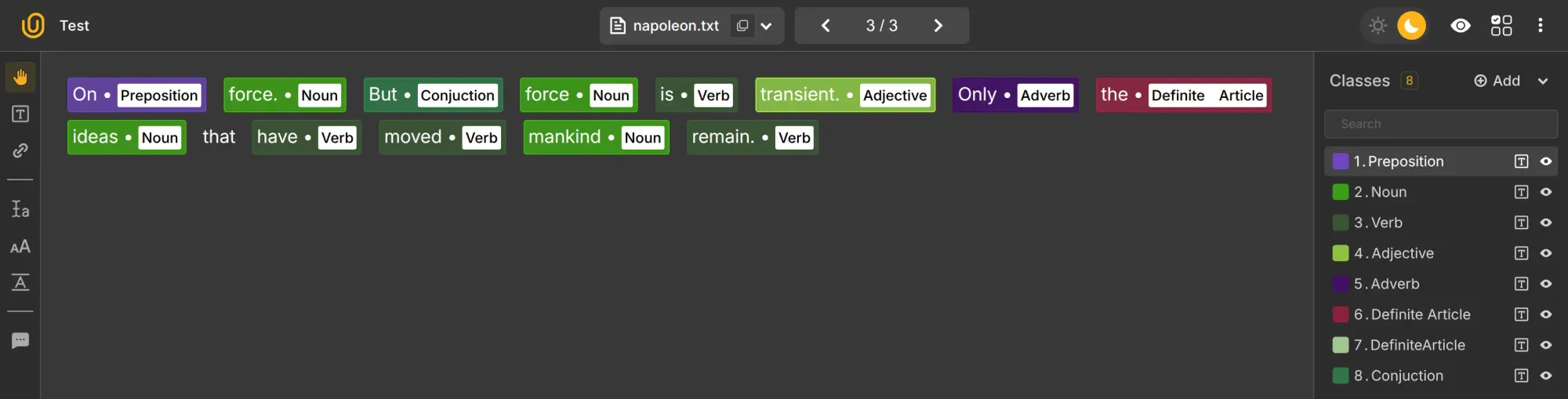
- Part-of-speech tagging: Identifies grammatical roles, needed for accurate translation and intent recognition. This might sound banal, but machines need to know part of speech of the word to accurately make translations and identify the intent.
Text Classification
While entity detection refers to annotating particular words or phrases in the text, text classification refers to assigning a single label to the whole text. Example: email spam detection labels an email “spam” or “not spam.” A news site might classify articles as “Finance,” “Politics,” or “History.”

News article classification involves categorizing news articles based on their topics, such as politics, entertainment, or sports, to improve content organization and discoverability. Additionally, language identification can be used to categorize or annotate texts by language, which is important for organizing and analyzing multilingual content within text classification tasks.
Our example text could be labeled "History" or "Autobiography."
Text Sentiment Classification
This mode is related to text classification, where sentiment annotation is a key process in identifying emotions and opinions in text. Instead of assigning labels from a fixed set of categories, it assigns emotional meaning to the whole text: positive, negative, neutral, or mixed. It specifies tone in addition to topic.
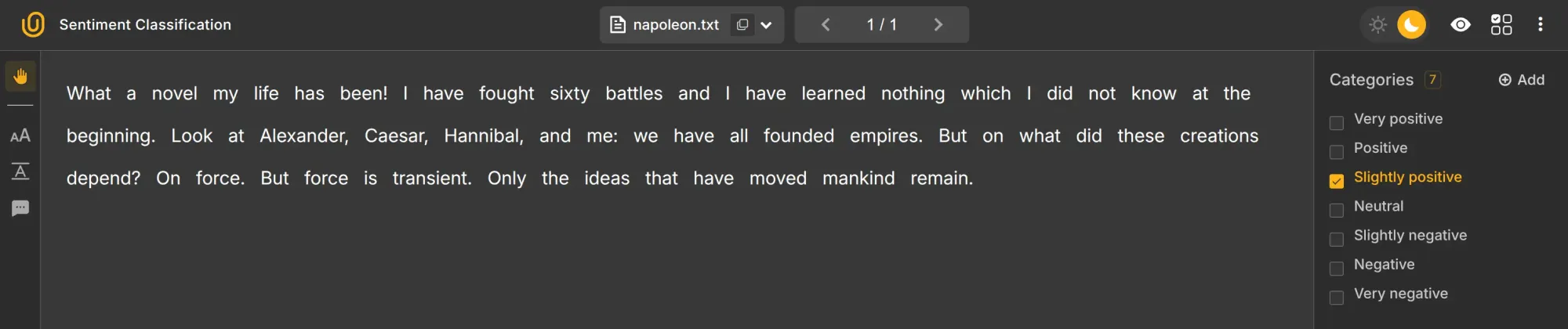
Napoleon's quote could be labeled slightly positive or mixed.
Text Sentiment Recognition
This assigns sentiment at the sentence or phrase level. It captures context and nuance more accurately than whole-text sentiment classification. In our case, it could look like this:
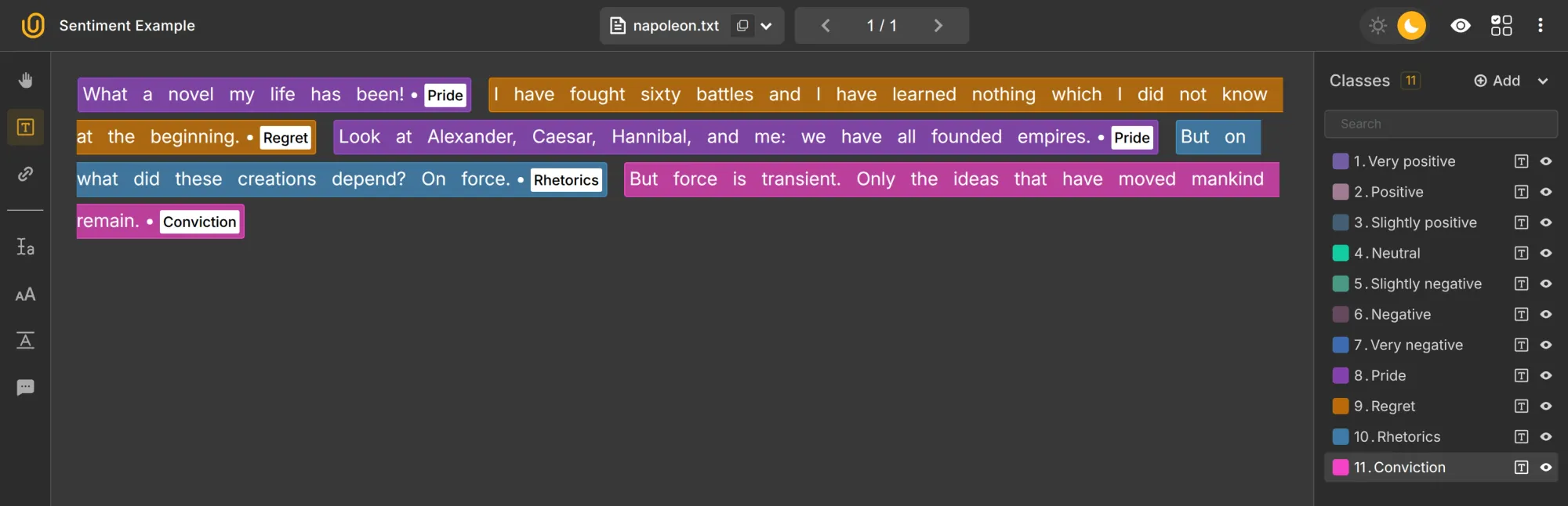
Text Language Translation
This translates text into multiple languages, especially where idioms or context matter. Standard services like Google Translate often fail in such cases.
For example, translating Napoleon’s quote to French and Russian shows the need for accurate, context-aware annotation:
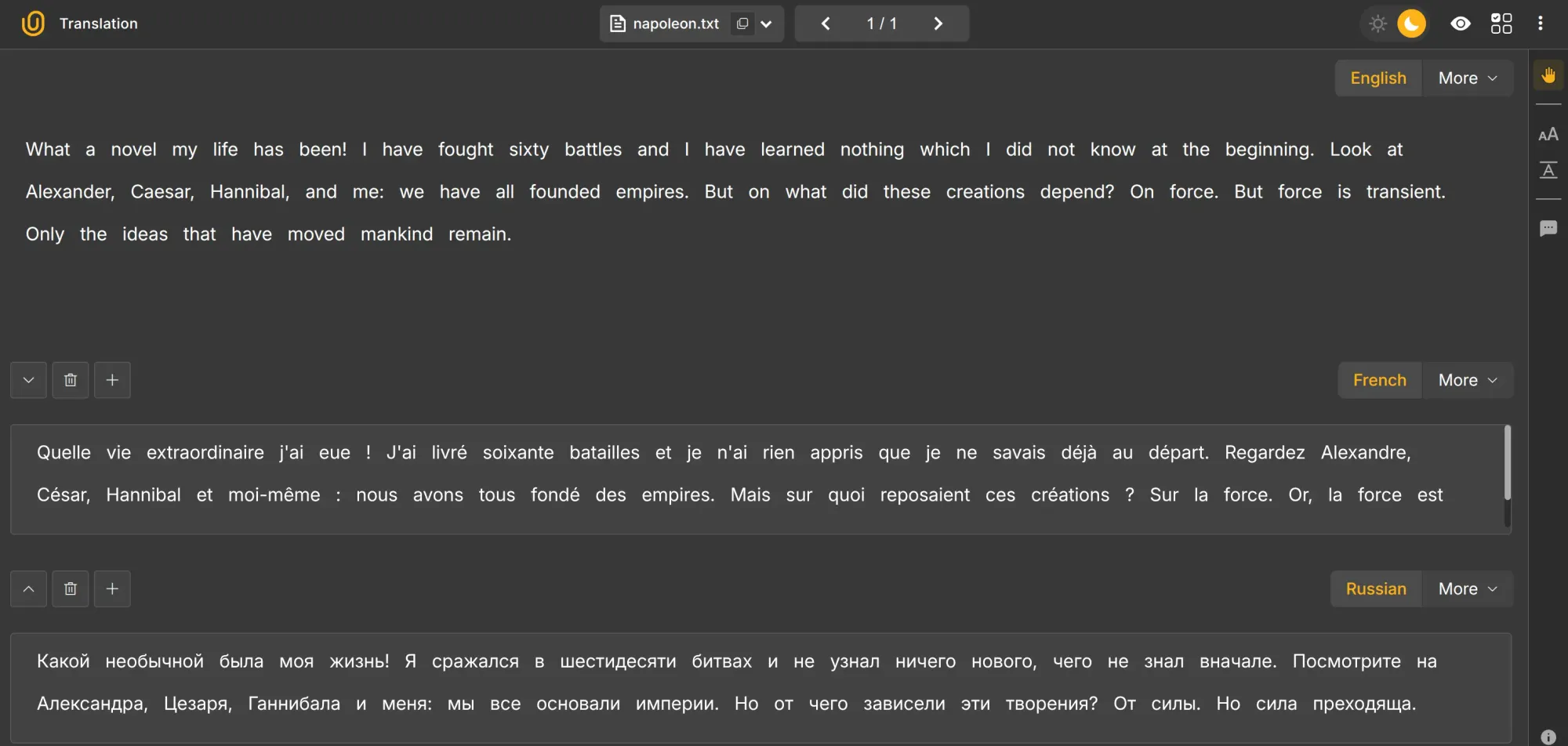
We can also combine modes, such as text translation, classification (History), and sentiment classification (Slightly Positive). Elegant, innit?
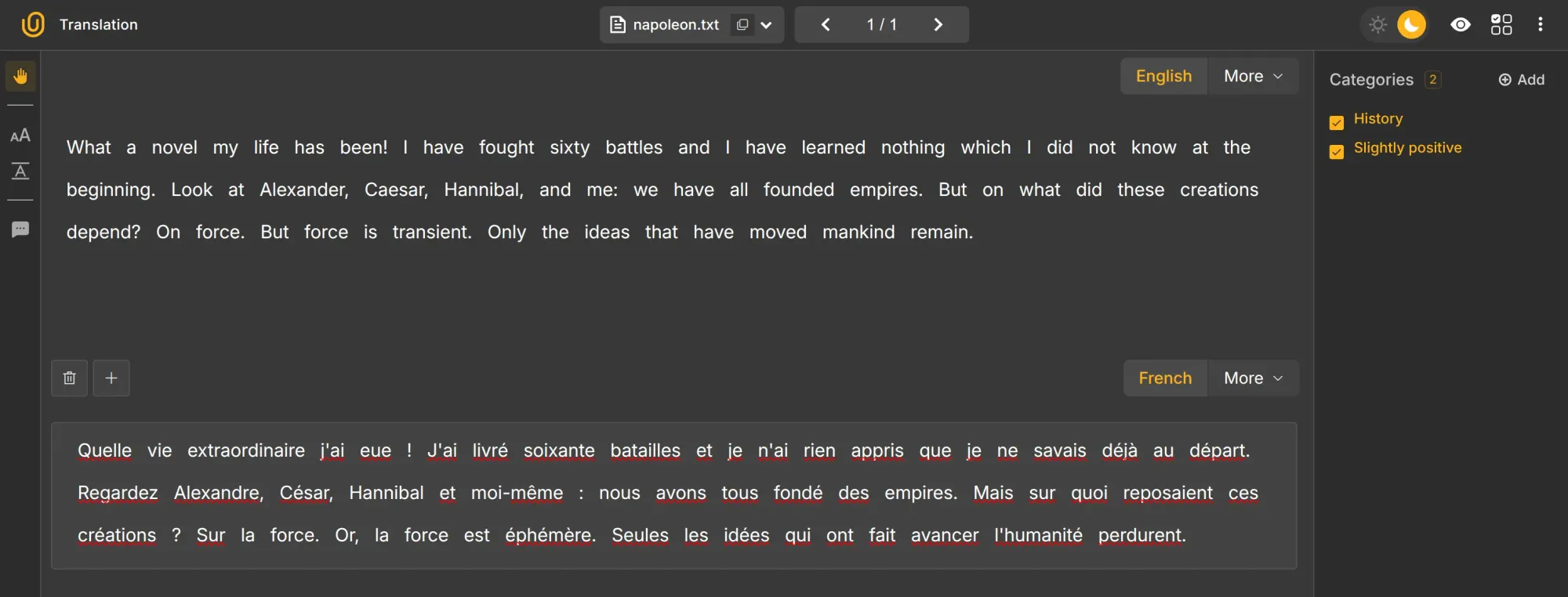
Use cases of text labeling
Text annotation powers many real-world applications:
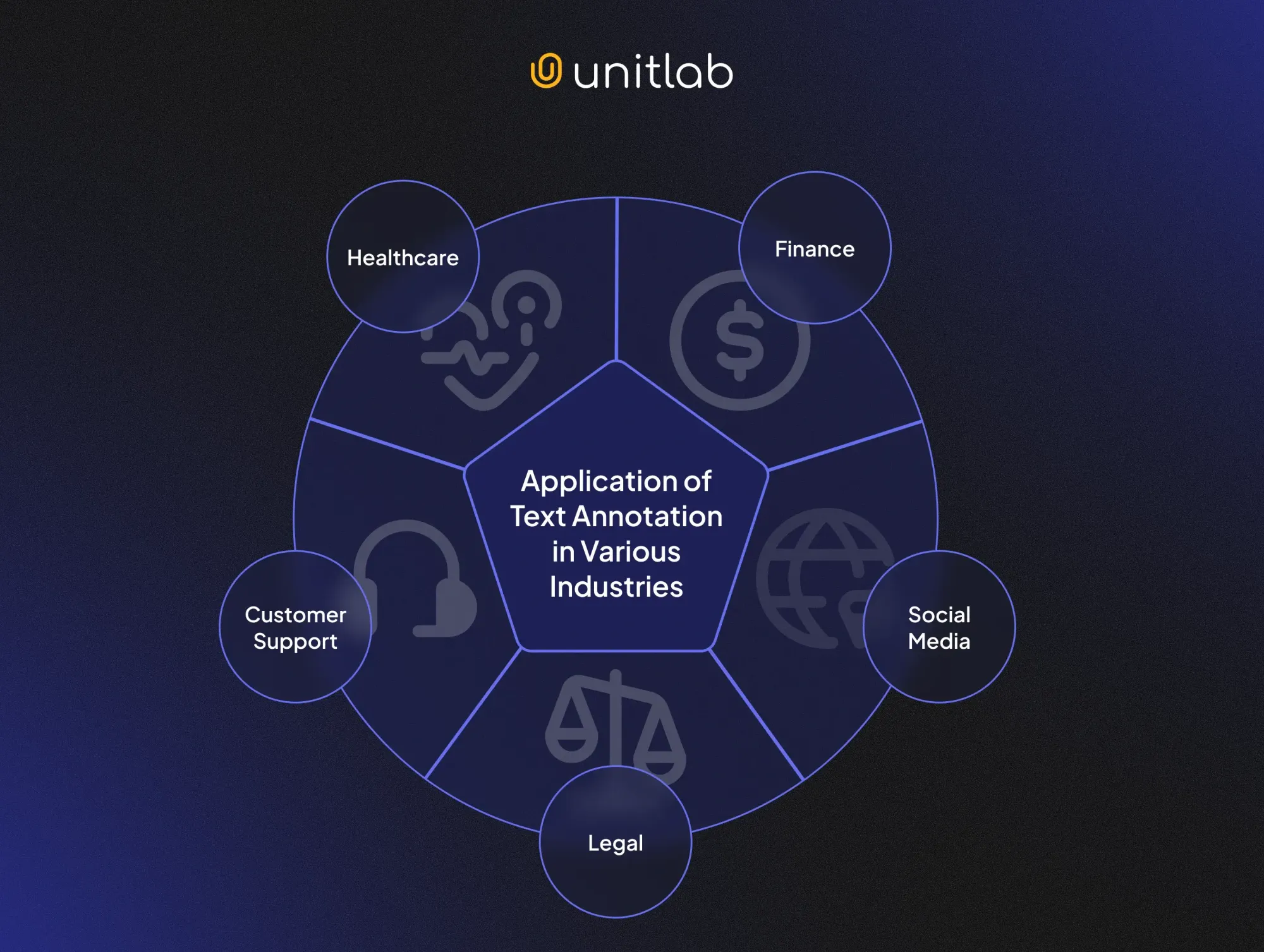
- Customer Support: Training chatbots to understand and respond in context of the website, and performing customer feedback analysis to improve service quality and customer satisfaction.
- Healthcare: Extracting data from medical records or clinical notes, automatically classifying documents for better access and faster search, applying healthcare text annotation to automate data extraction, and analyzing clinical trial records for research and patient care improvements.
- Finance: Flagging fraudulent transactions, identifying money laundering patterns, parsing financial contracts, and extracting contextual data for improved risk assessment and fraud detection.
- Social Media: Identifying the sentiment of social media posts and tweets to flag potential hate speech, misinformation, or other harmful content for human reviewers.
- Legal: Classifying and translating legal documents and extracting essential data from these contracts.
Text annotation can also be used to extract valuable insights from various data sources, including video annotation for multimedia data.
Demo Project with Unitlab AI
Project Setup
We will explore text labeling hands-on with this tutorial in Unitlab Annotate. First of all, create a free account to follow this tutorial:
After registration, in the Projects pane, click Add a Project:
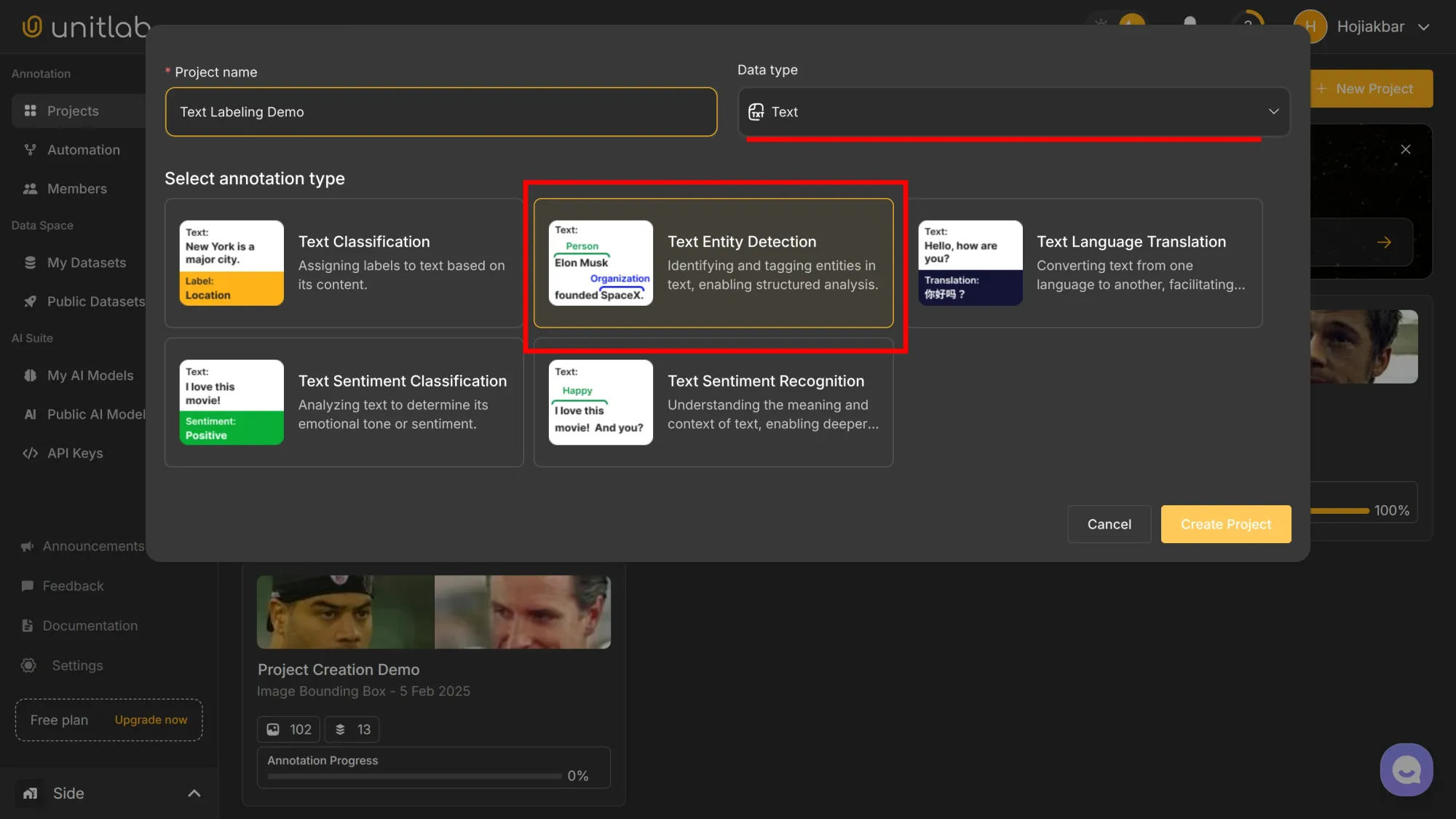
Name your project, choose Text as the data type and Text Entity Detection as the labeling type:
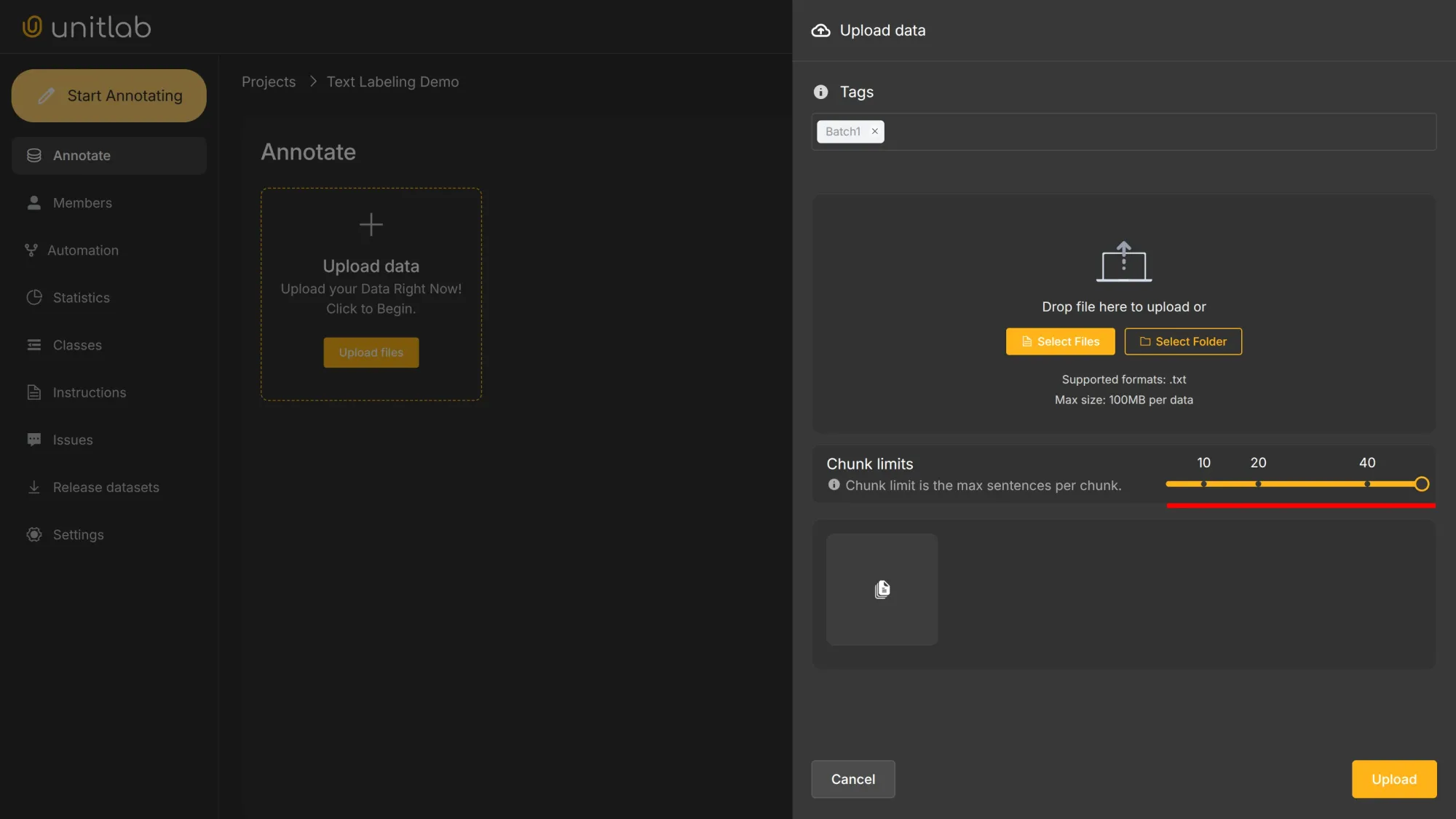
Upload the project data in the .txt format. The chunk limit specifies the maximum number sentences per chunk and creates chunks accordingly. We set it to 50 for this project.
You can download our sample here:
Then, assign the annotators. By default, it is you. Annotators will receive invitation emails in any case.
Congratulations, you configured your first project successfully.
Labeling Texts
Let's look at our sample text one more time:
What a novel my life has been! I have fought sixty battles and I have learned nothing which I did not know at the beginning. Look at Alexander, Caesar, Hannibal, and me: we have all founded empires. But on what did these creations depend? On force. But force is transient. Only the ideas that have moved mankind remain.
—Napoleon Bonaparte
Depending on the requirements, we could label this quote in a million different ways. To illustrate text annotation, we’ll choose the simple way of labeling proper and abstract nouns:
First, we create two classes, namely Proper and Abstract. We then labeled proper and abstract nouns within our text accordingly.
While automated methods can be used to generate initial labels for these classes, human annotation is essential to ensure correct labels generated, especially when high-quality datasets are required.
Labeling Texts | Unitlab Annotate
Dataset Creation
In Unitlab Annotate, you can release datasets once you label your data. The platform will fully take care of dataset versioning, management, and sharing, allowing you to focus on the labeling, not dataset overheads.
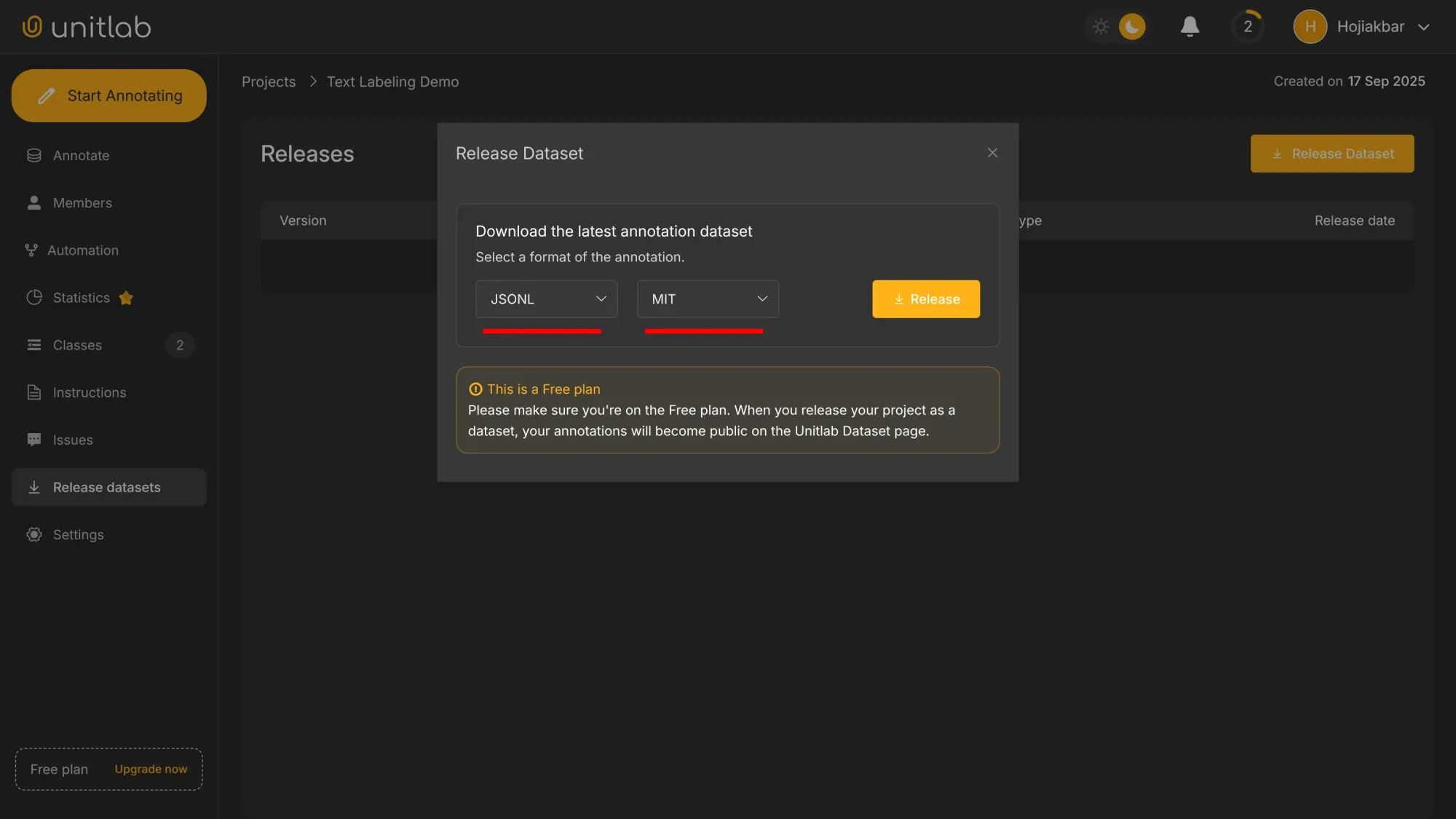
Go to the Release Datasets panel and click the Release Dataset button:
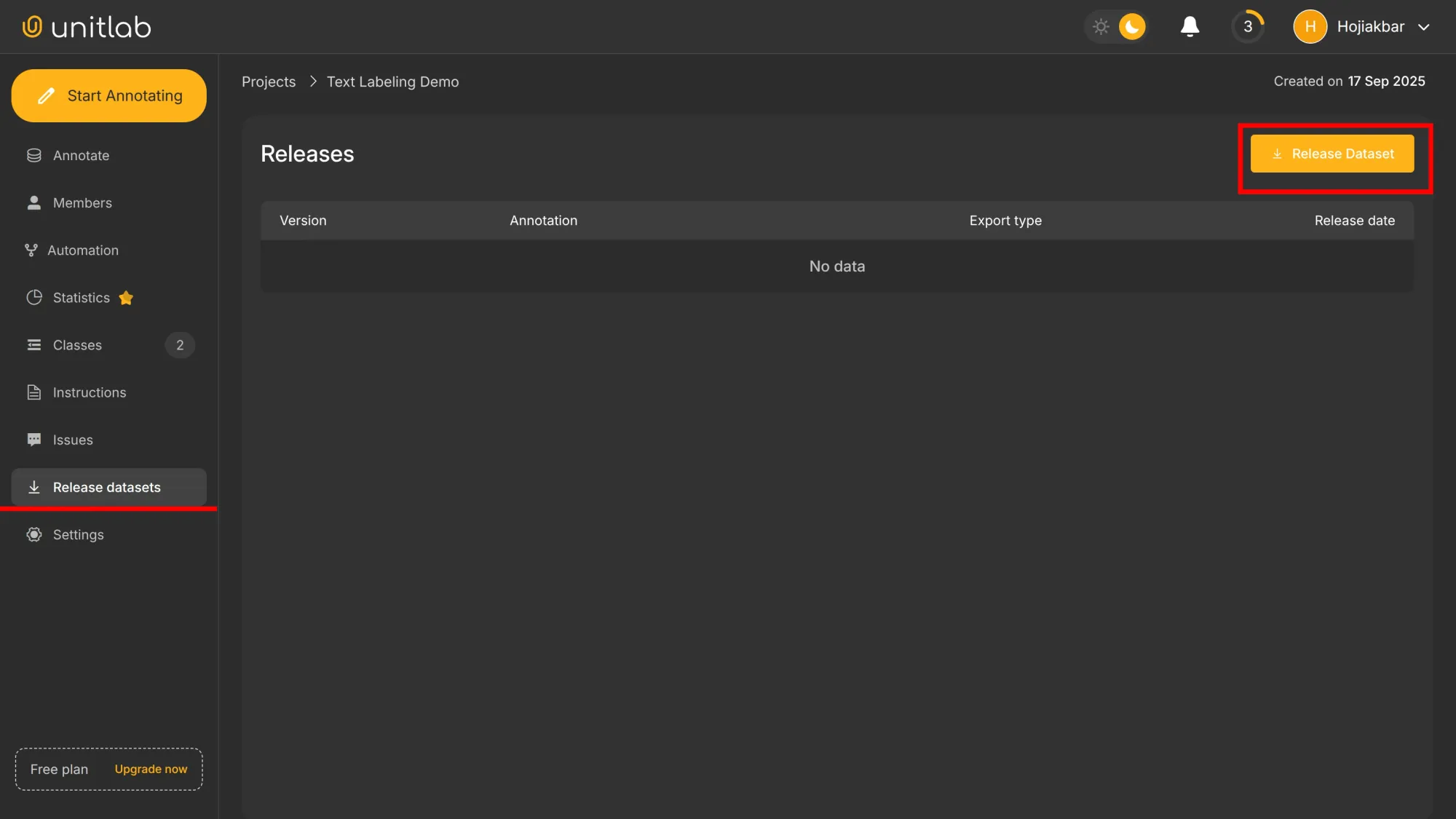
By default, the annotation format for texts is JSONL. Because we are under the free plan, our datasets become public inside Unitlab Annotate. You can upgrade to a paid plan for private datasets, along with other features. We choose MIT as the license for our dataset:
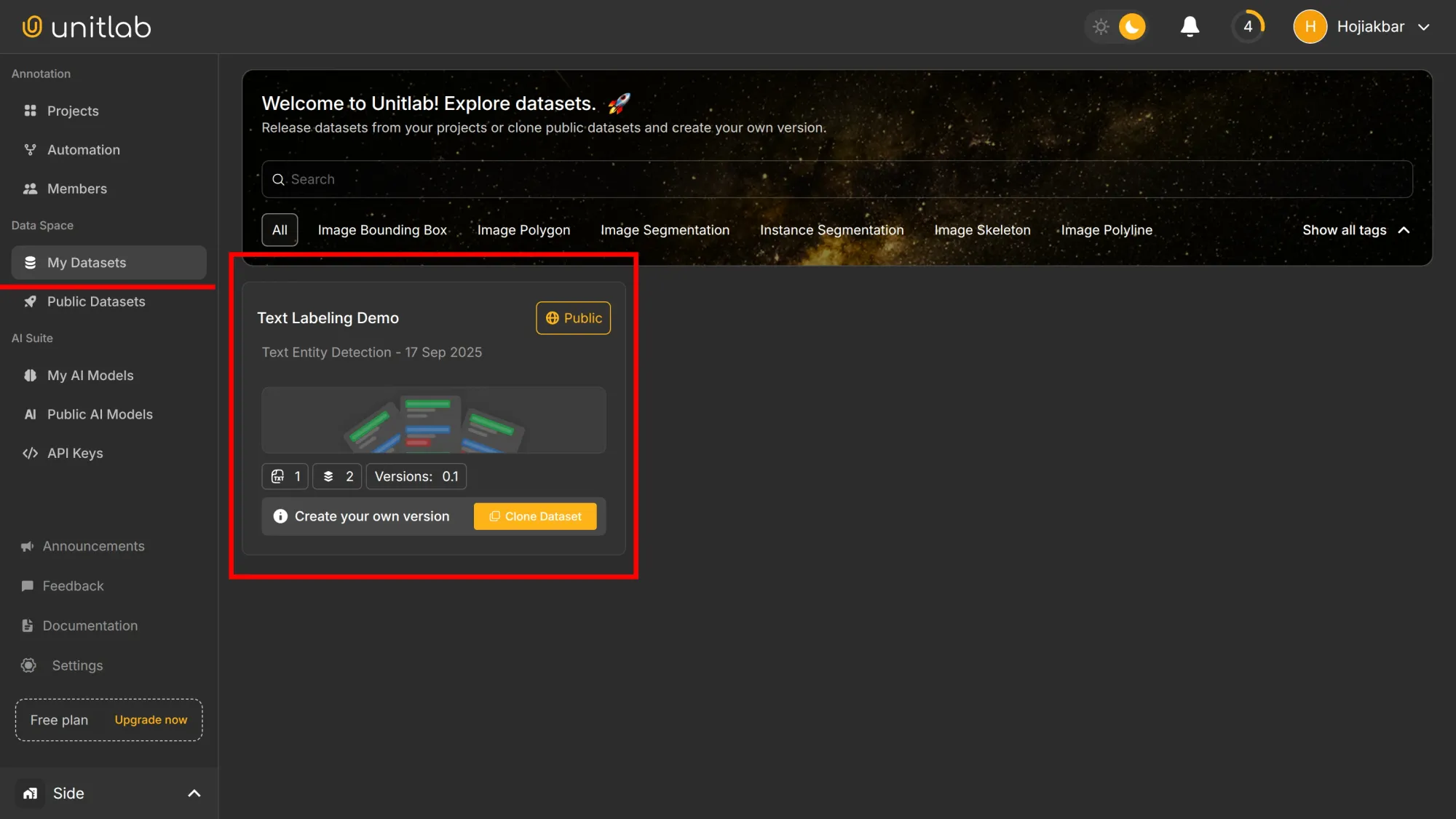
After the dataset release, we are redirected to its description page. We can clone, download, and manage it here. You can also manage your datasets in the My Datasets pane:
Conclusion
Text labeling makes raw text usable for AI/ML models. Accurate text annotations are essential for producing high quality labelled data, which is critical for training robust machine learning models.
Text annotations enable applications from healthcare to finance to law, supporting tasks like sentiment analysis and named-entity recognition. Different annotation types suit different needs.
You can try text labeling today by creating a free account in Unitlab Annotate. The platform provides everything you need so you can focus on labeling, not overhead.
Explore More
Follow these articles for more on data annotation:
- Audio Data Annotation with Unitlab AI [2025]
- A Comprehensive Guide to Image Annotation Types and Their Applications
- Who is a Data Annotator?
![Audio Data Annotation with Unitlab AI [2025]](/content/images/size/w360/2025/12/audio-unitlab.png)
![Agentic AI: Data Annotation with Unitlab AI [2025]](/content/images/size/w360/2025/12/agentic.png)