

Applying SAM 3 to video annotation and object tracking looks powerful on paper, but when used inside real data annotation tools and scalable annotation workflows, critical limitations begin to surface—impacting quality, cost, and delivery timelines.
Introduction
Segment Anything Model 3 (SAM 3) is increasingly being explored as part of modern computer vision annotation workflows. Its promise of prompt-based segmentation makes it attractive for video annotation, instance segmentation labeling, and automated image labeling across industries such as autonomous systems, robotics, industrial automation, and large-scale computer vision dataset creation. For data annotation startups, annotation service providers, and enterprises managing high-volume video data, SAM 3 appears to offer faster dataset labeling with reduced manual effort. The diagram below shows how SAM 3 combines prompt-based inputs, tracking, and memory to propagate segmentation masks across video frames.
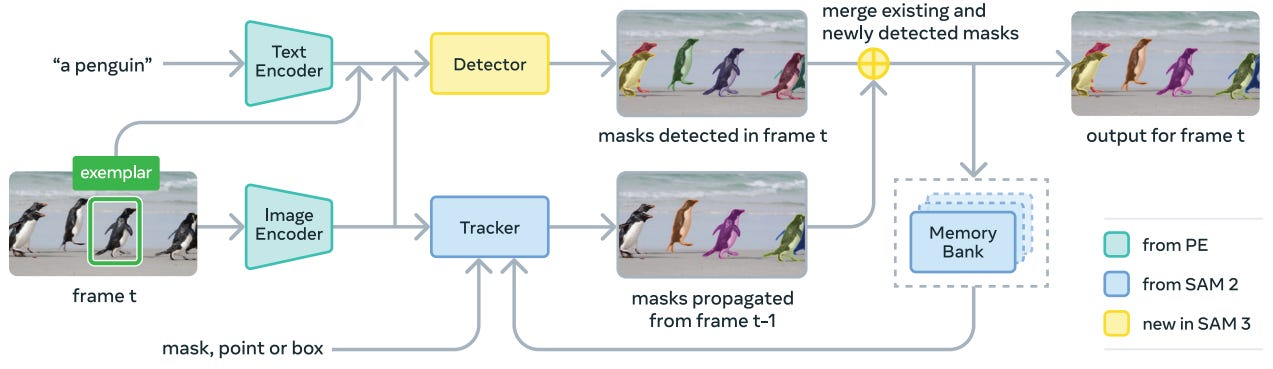
However, real-world video data introduces complexities that go far beyond static image annotation. Long video sequences, object occlusion, fast motion, scene changes, and overlapping instances challenge the reliability of automated segmentation. When SAM 3 is deployed within data labeling platforms or AI-powered labeling software, these challenges often lead to tracking drift, temporal inconsistency, and re-identification failures. As a result, annotation quality drops, manual correction effort increases, and compute costs rise, especially when scaling to tens of thousands of frames.
For organizations relying on machine learning data labeling to train production-grade models, these limitations directly affect operational efficiency. Teams are often forced to introduce human-in-the-loop annotation platforms, annotation QA automation, or additional annotation pipeline automation to maintain dataset quality. What initially appears as a cost-saving automation layer can quickly become a bottleneck without the right dataset management platform and workflow controls in place.
Understanding these limitations is essential for businesses evaluating SAM 3 as part of a broader computer vision annotation toolchain. Whether you are outsourcing video annotation services, building an enterprise data annotation platform, or managing in-house dataset creation, knowing where SAM 3 struggles helps you design more resilient, scalable annotation workflows and avoid costly rework.
The table below shows how these technical limitations translate into real operational impact in production annotation workflows.
| Technical Limitation | What Happens in Practice | Operational Impact |
|---|---|---|
| Temporal inconsistency | Masks flicker across frames | Repeated manual fixes |
| Tracking drift | Masks slowly move off objects | Large segments need rework |
| Occlusion failures | Objects lose identity | Human review required |
| Fast motion sensitivity | Partial or missing masks | Re-prompting and re-init |
| Scene / camera changes | Mask collapse or loss | Full re-annotation |
| Overlapping objects | ID swaps and merges | QA effort increases |
| Long video duration | Errors compound silently | Cost and latency spike |
In this blog, we will cover:
- Where SAM 3 struggles when used for real-world video annotation and object tracking
- How issues like temporal inconsistency, tracking drift, fast motion, and occlusions appear in different video scenarios
- Why long videos, overlapping objects, and large datasets create scalability challenges
- The practical impact on annotation quality, manual correction effort, and operational cost
- Why production teams often need more than SAM 3 to build scalable annotation workflows
Temporal Inconsistency Across Long Video Sequences
Long-duration video example where small segmentation errors compound across frames.
While SAM 3 introduces video-aware capabilities on top of the Segment Anything paradigm, it remains fundamentally optimized for strong frame-level segmentation rather than long-term temporal consistency. As noted in Meta’s official SAM 3 release, maintaining stable masks across extended video sequences remains challenging without additional tracking or correction mechanisms. This aligns with earlier findings from the original Segment Anything work and related Meta research on video object segmentation, where small per-frame errors tend to accumulate over time in long or complex videos.
In real-world annotation pipelines, this temporal instability quickly translates into inconsistent labels, repeated manual fixes, and higher compute and review costs, especially when working with long, continuous video sequences at scale.
Tracking Drift Caused by Cumulative Segmentation Errors
Once temporal inconsistency begins to appear in long video sequences, its effects rarely remain isolated. In practice, small frame-level inaccuracies often compound over time, leading to a more visible and costly failure mode: tracking drift. Instead of abruptly failing, segmentation masks gradually shift away from the true object boundaries as errors accumulate across frames.
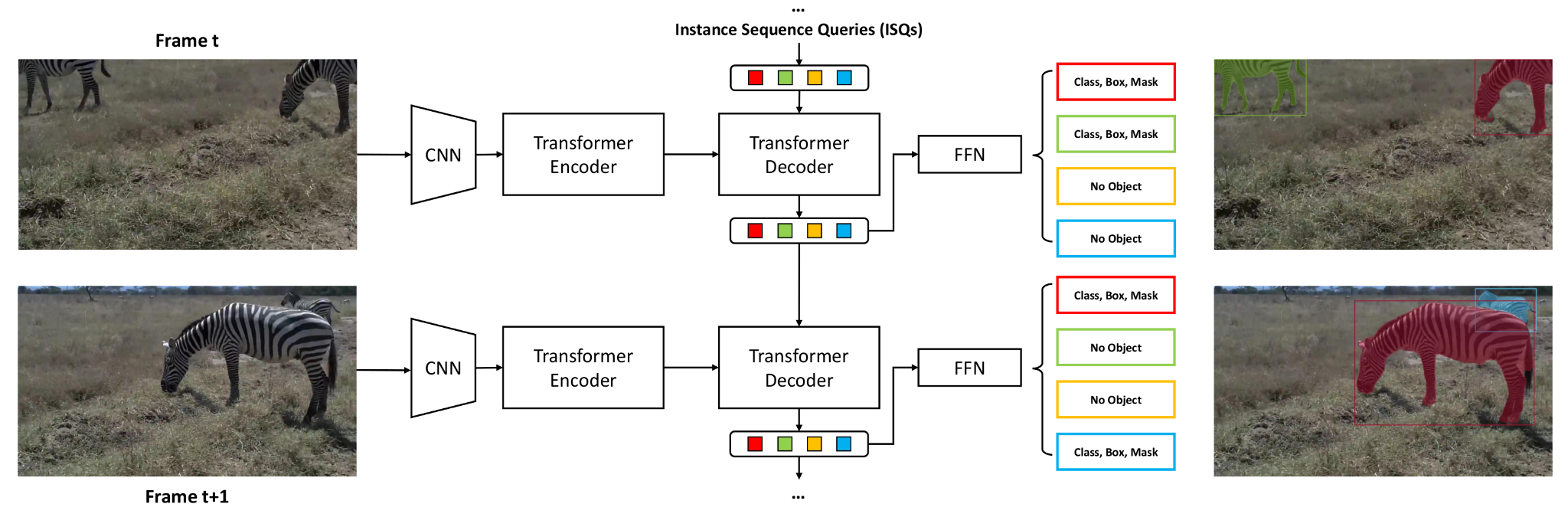
Object representations are propagated across consecutive video frames, where small errors can accumulate and lead to tracking drift. As object information is carried forward frame by frame, even minor inaccuracies can compound over time, increasing correction effort and processing cost.
Tracking drift is particularly common in continuous video annotation workflows where masks are propagated over hundreds or thousands of frames without re-initialization. Early outputs may appear reliable, but as drift progresses, masks can begin to capture background regions, miss fine object details, or slowly diverge from the intended target. By the time the issue becomes noticeable, large portions of the video may already be affected.
For teams working with production-scale datasets, this creates a significant operational challenge. Drifted annotations reduce overall label consistency and can silently degrade dataset quality, especially when automated checks are limited. Correcting these errors often requires revisiting long video segments, increasing manual correction effort, and extending review cycles across the annotation pipeline.
From a cost perspective, tracking drift also impacts compute usage and inference latency. Reprocessing extended video segments, re-running segmentation passes, or applying corrective workflows across large datasets can quickly offset the efficiency gains of automated video annotation. For annotation service providers and enterprises managing high-volume video data, these hidden costs tend to surface only after systems are deployed at scale.
Because tracking drift is a downstream consequence of earlier temporal instability, many production teams address it through hybrid annotation workflows. By combining SAM-based automation with annotation QA automation, human-in-the-loop review, and dataset management platforms that can detect drift early, teams can limit error propagation and maintain scalable annotation workflows. Solutions like Unitlab are designed to support this approach, helping organizations balance automation speed with long-term dataset reliability.
Fast Motion Sensitivity in High-FPS and Low-Quality Video
Fast-moving objects and rapid scene changes introduce a distinct challenge for video annotation systems built on frame-to-frame segmentation. In high-FPS footage, object appearance can change significantly between adjacent frames, making it difficult for prompt-based segmentation models to maintain stable boundaries. This limitation has been widely observed in video object segmentation research, where sudden motion increases temporal ambiguity and reduces mask stability across frames.
Motion-related issues become even more pronounced in low-quality or heavily compressed video. Motion blur, compression artifacts, and reduced edge clarity weaken the visual cues required for accurate segmentation, leading to partial masks, delayed updates, or missed object regions. Prior studies have shown that these effects are especially damaging when segmentation results are propagated over time, as errors introduced during high-motion frames tend to persist and compound.

From an operational perspective, fast-motion sensitivity directly impacts annotation quality and throughput. Annotation teams often need to intervene more frequently by adding corrective prompts, slowing propagation, or re-initializing segmentation after motion-heavy segments. These interventions increase manual correction effort and introduce variability across the dataset, particularly in large-scale video annotation projects.
Fast motion also affects compute usage and inference latency. High-FPS videos require more frequent inference, and when combined with corrective passes triggered by motion-related errors, processing overhead increases substantially. Research on large-scale machine learning systems has shown that such repeated processing patterns introduce hidden compute costs that often become visible only after deployment at scale.
Occlusions and Re-Identification Issues in Real-World Video Annotation
Occlusion is one of the most common failure modes encountered in real-world video annotation projects. In practical data annotation tools and video annotation outsourcing workflows, objects frequently become partially or fully hidden due to other objects, camera movement, or environmental changes. When this happens, segmentation models must correctly re-identify the object once it reappears to preserve instance continuity.

In SAM 3–based video annotation pipelines, occlusions often disrupt mask propagation and instance tracking. When an object disappears and later re-enters the frame, the model may fail to associate it with the original instance. This can result in duplicated masks, fragmented instance segmentation labeling, or inconsistent object IDs across frames. Within data labeling platforms and automated image labeling tools, these issues directly reduce annotation quality and dataset reliability.
For dataset labeling companies and annotation services companies handling large-scale video data, re-identification failures create a significant manual burden. Human-in-the-loop annotation platforms are frequently required to correct broken instances, merge fragmented masks, or reassign object identities across long sequences. This increases manual correction effort and slows down annotation workflow automation, especially in projects involving dense scenes or frequent object interactions.
Moreover, Occlusion-related errors also affect the compute cost and inference latency. Reprocessing occluded segments, re-running segmentation passes, or applying corrective annotation QA automation across large datasets adds additional overhead. In scalable annotation workflows, these costs accumulate quickly and can offset the expected efficiency gains of AI-powered labeling software.
As a result, many production-grade computer vision annotation workflows rely on more than a single AI labeling tool. Teams often combine SAM-based automation with dataset management platforms, annotation QA automation, and structured human review to ensure consistent instance tracking. This hybrid approach helps data annotation startups, enterprise data annotation platforms, and ML model annotation services maintain high-quality video datasets while scaling annotation operations efficiently.
Scene and Camera Changes That Break Segmentation Continuity
Scene and camera changes represent another major failure mode when applying SAM 3 within real-world video annotation and data annotation tools. Unlike occlusion, where the object disappears temporarily, scene and camera changes alter the visual context itself. Camera panning, zooming, viewpoint shifts, lighting changes, or scene cuts can significantly change how an object appears from one frame to the next.

In SAM 3–based annotation pipelines, segmentation masks are often propagated using visual similarity and short-term memory. When the camera perspective changes abruptly, these assumptions break down. Objects that remain present in the video may no longer match their previous visual representation, causing masks to drift, collapse, or disappear entirely. In practical data labeling platforms and automated image labeling tools, this frequently results in broken segmentation continuity and incomplete instance tracking.
These failures directly impact annotation quality. Objects may require re-prompting, re-initialization, or full re-annotation after camera motion or scene transitions. For dataset labeling companies and annotation services companies working with long-form or dynamic video data, this increases manual correction effort and reduces the effectiveness of annotation workflow automation.
From a system perspective, scene and camera changes also affect compute cost and inference latency. Re-running segmentation after every major camera movement or scene transition adds additional processing overhead. In large-scale, scalable annotation workflows, especially those handling thousands of videos or continuous streams, these costs accumulate quickly and limit throughput.
As a result, production-grade computer vision annotation workflows often require additional logic beyond base segmentation models. Temporal validation, scene-change detection, and human-in-the-loop review are commonly introduced to maintain dataset consistency across camera and scene variations. Without these supporting workflows, segmentation continuity becomes fragile in real-world video annotation scenarios.
Multi-Object Tracking and Overlapping Objects
Multi-object tracking introduces additional complexity for video annotation systems, especially in crowded or interactive scenes. In real-world video data, objects frequently overlap, intersect, or move in close proximity, such as pedestrians in public spaces, vehicles in traffic, or workers on a factory floor. In these scenarios, segmentation models must not only detect objects accurately but also maintain clear instance separation over time.
In video annotation pipelines built on SAM 3, scenes with overlapping or interacting objects often trigger instance-level errors. When objects intersect or move closely together, segmentation masks can merge unintentionally, fragment during interaction, or switch identities as objects cross paths. These issues are especially disruptive, for instance, segmentation labeling, where consistent object identities across frames are essential for reliable downstream model training.
For data labeling platforms and dataset labeling companies, multi-object failures significantly increase annotation complexity. Automated image labeling tools may produce outputs that appear correct at a glance but contain subtle identity errors that only surface during review or model training. Correcting these issues typically requires manual merging, splitting, or reassigning instance IDs, increasing manual correction effort and slowing annotation workflow automation.
Multi-object scenarios also amplify compute cost and inference latency. Dense scenes often require higher-resolution processing, additional segmentation passes, or stricter quality checks to avoid instance leakage. In large-scale video annotation projects, these added costs accumulate quickly and reduce the overall efficiency gains expected from AI-powered labeling software.
As a result, production-grade annotation workflows often incorporate additional safeguards for multi-object tracking, such as instance-level validation, overlap detection, and human-in-the-loop review. These workflow-level controls help maintain dataset consistency and reduce silent errors that can undermine model performance.
Long-Duration Video and Scalability Constraints (100K+ Frames)
While SAM 3 can perform effectively on short video clips or controlled datasets, long-duration video introduces a different class of challenges. In real-world applications, annotation pipelines frequently process videos spanning tens or hundreds of thousands of frames, such as surveillance footage, autonomous driving data, industrial monitoring streams, or medical video archives.
In these long-running sequences, even small segmentation errors accumulate over time. Temporal inconsistency, tracking drift, occlusion failures, and instance confusion compound across frames, gradually degrading annotation quality. Without frequent re-initialization or validation, errors may persist undetected for large portions of the dataset, reducing overall dataset reliability.
From an operational perspective, long-duration video places heavy demands on compute resources. Running segmentation inference across 100K+ frames requires sustained processing, and corrective workflows such as re-segmentation, QA checks, or human review significantly increase inference latency and compute cost. For annotation services companies and enterprises managing large video datasets, these costs often become visible only after systems are deployed at scale.
Scalability constraints also affect annotation throughput. As video length increases, annotation workflow automation becomes harder to maintain without introducing bottlenecks. Teams may need to segment videos into smaller chunks, schedule reprocessing jobs, or allocate additional human reviewers to manage quality, all of which reduce the net efficiency of automated annotation.
To address these challenges, scalable annotation workflows typically rely on more than a single segmentation model. Dataset management platforms, annotation QA automation, selective human-in-the-loop review, and intelligent workload orchestration are commonly introduced to control error propagation and manage cost. Without these supporting systems, applying SAM 3 to long-duration video remains difficult to scale reliably.
Conclusion
In practice, the limitations discussed throughout this blog tend to appear together.
When video length, object complexity, and scale increase, the gap between SAM 3 in isolation and production-grade annotation workflows becomes clear.
The table below summarizes this difference.
| Challenge | SAM 3 Alone | Production-Grade Annotation Workflow |
|---|---|---|
| Long video sequences (100K+ frames) | Errors accumulate silently | Errors detected and limited early |
| Temporal consistency | Mask flicker and instability | Validation and correction loops |
| Tracking drift | Gradual boundary drift | Drift detection and re-initialization |
| Occlusions and re-identification | Broken instances and ID swaps | Human-in-the-loop recovery |
| Multi-object and crowded scenes | Merged or fragmented masks | Instance-level QA and validation |
| Compute cost at scale | Cost spikes after deployment | Controlled and predictable cost |
| Annotation throughput | Slows as video length grows | Stable throughput via orchestration |
References
- Alexander Kirillov et al. Segment Anything. Meta AI Research (FAIR): Source
- Sculley D et al, Hidden Technical Debt in Machine Learning Systems: Source
- Sheng Shen, Zhewei Yao, et al. DynaBERT: Dynamic BERT with Adaptive Width and Depth. arXiv: Source
- Alexander Ratner et al. Data Programming: Creating Large Training Sets, Quickly. NeurIPS: Source
- Ho Kei Cheng et al. XMem: Long-Term Video Object Segmentation with an Atkinson–Shiffrin Memory Model. ECCV: Source
- Encord Team (no date). Key Challenges in Video Annotation for Machine Learning. Encord Blog: Source
- Zheng Chen et al. Overload: Latency Attacks on Object Detection for Edge Devices. CVPR 2024: Source

