

For years, machine learning engineers worked with pixel arrays (computer vision), text tokens (NLP), and audio waveforms. These different modalities existed in parallel but rarely intersected in meaningful ways.
But with the release of large multimodal models (LMMs), the focus shifted from unimodal to multimodal artificial intelligence. These models read text, see images and videos, hear audio, and process sensor data in real-time within a single neural architecture.
In this guide, we'll explore how LMMs power various multimodal applications across industries.
Here’s what we cover:
- What is Multimodal AI?
- Top Applications of Multimodal AI
- Strategic Outlook 2026
Training AI models requires massive, high-quality labeled data. We at Unitlab help you to scale your data quality and speed up model development.
We provide customized data annotation solutions for image, video, audio, and text, so you can fast-track your AI model training with confidence.
Interested in preparing high-quality data for your AI project? Try Unitlab for free!
What is Multimodal AI?
Before discussing the multimodal application, let's first define what multimodal AI is.
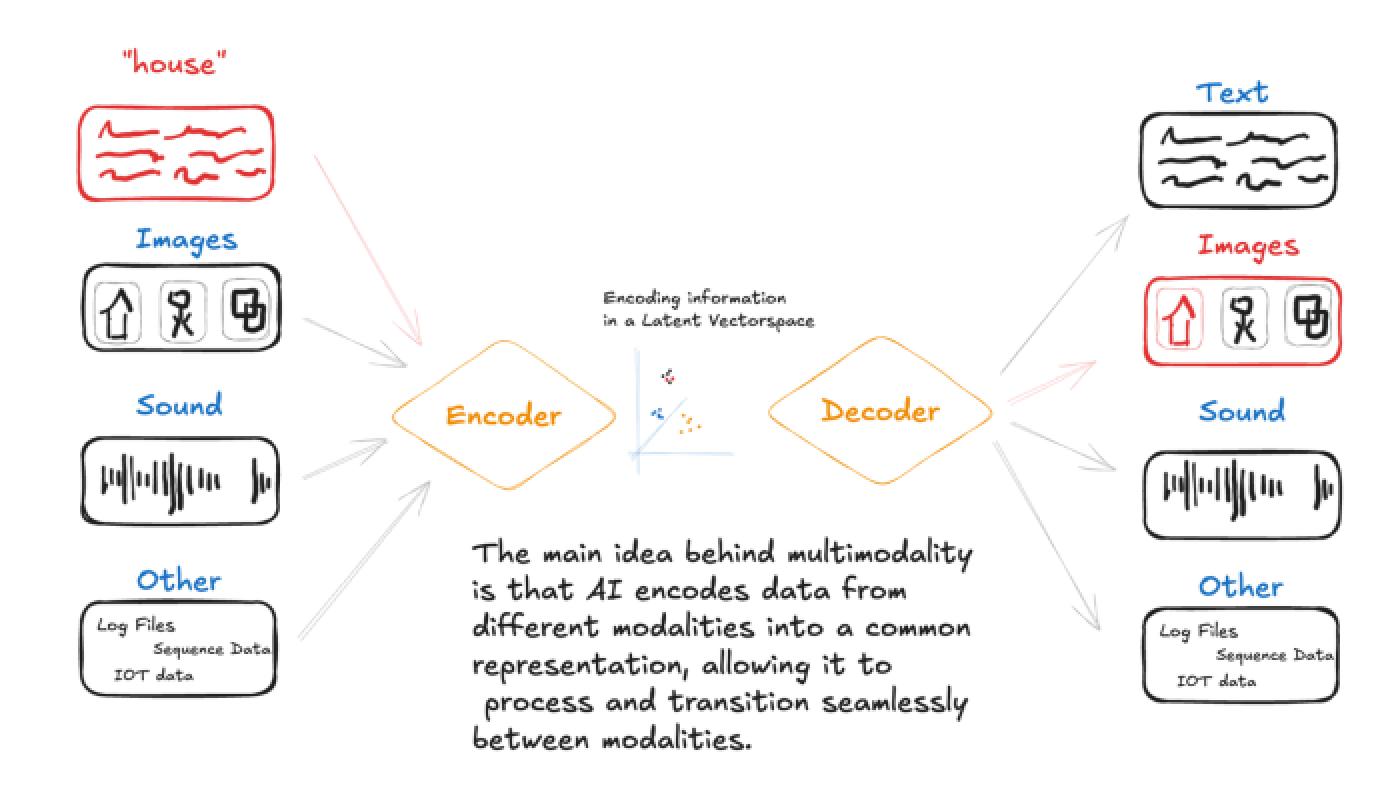
Multimodal AI refers to an AI system that processes and combines diverse inputs, such as text, images, audio, and video, in a single model.
Unlike traditional AI systems (which are unimodal systems) that handle only one modality (text-only or image-only), multimodal models fuse information across modalities.
For example, a model might analyze a photograph and its textual caption together, or process a video with accompanying audio narration.
Furthermore, modern multimodal models can generate images from text, produce textual summaries of images or videos, and even handle spoken instructions with visual cues.
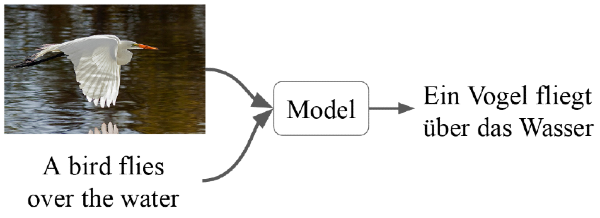
Combining multiple data types enhances the system's ability to understand and interpret complex, real-world situations.
Here are some key reasons why integrating multiple data modalities is important:
- Improved Accuracy and Reliability: Multiple modalities can cross-validate each other and reduce ambiguities and errors that single-modality systems often encounter (text without visual context). For example, if the camera feed is blurry, sensor data or audio inputs may still offer sufficient information for precise analysis and lead to more reliable outcomes.
- Mimics Human-Like Understanding: Humans naturally integrate sights, sounds, and language to interpret the environment. Multimodal AI replicates this by handling different types of inputs simultaneously, making interactions like virtual assistants and customer support feel more natural.
- Increased Robustness: Multimodal systems are more resilient to noise, incomplete data, or failures in one modality, as they can rely on other modalities for compensation, critical in real-world environments such as robotics or surveillance.
- Greater Efficiency: A single multimodal model can handle diverse tasks and reduce the need for multiple specialized unimodal models, making workflows easier in enterprise settings.
Key components of a multimodal system:
- Data Collection: Gather raw data from diverse sources (images, sensor readings, documents, audio). For instance, an autonomous vehicle may collect camera images, LiDAR scans, and GPS logs simultaneously.
- Feature Extraction: Process each type of data with appropriate methods (computer vision techniques extract objects from images; NLP processes text). Each modality is turned into a vector of features.
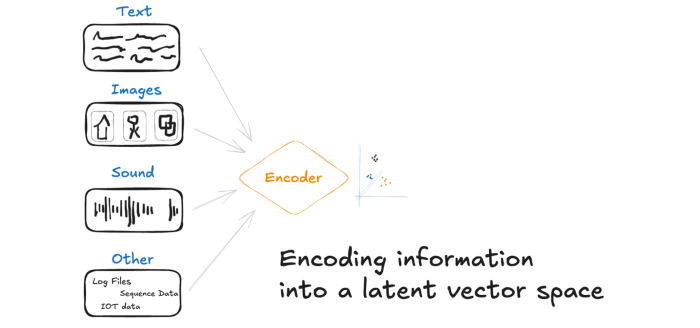
- Data Fusion: Combine the extracted features into a joint representation. You can do with early fusion (concatenating raw inputs) or late fusion (merging processed features). Fusion aligns and processes the data so the model sees the whole picture.
- Model Training: Train a machine learning model on the combined dataset. The AI learns to associate inputs across modalities (linking specific phrases to parts of images). The result is an AI that captures nuanced, cross-modal patterns.
- Inference (Output): Use the trained model to make predictions or generate outputs that may span modalities. For example, a multimodal chatbot can interpret a photo and respond with text, or an AI system might create an image based on a verbal description.
Industry-Specific Multimodal AI Applications
Now, let's explore the top multimodal use cases in different domains. Tentative applications are:
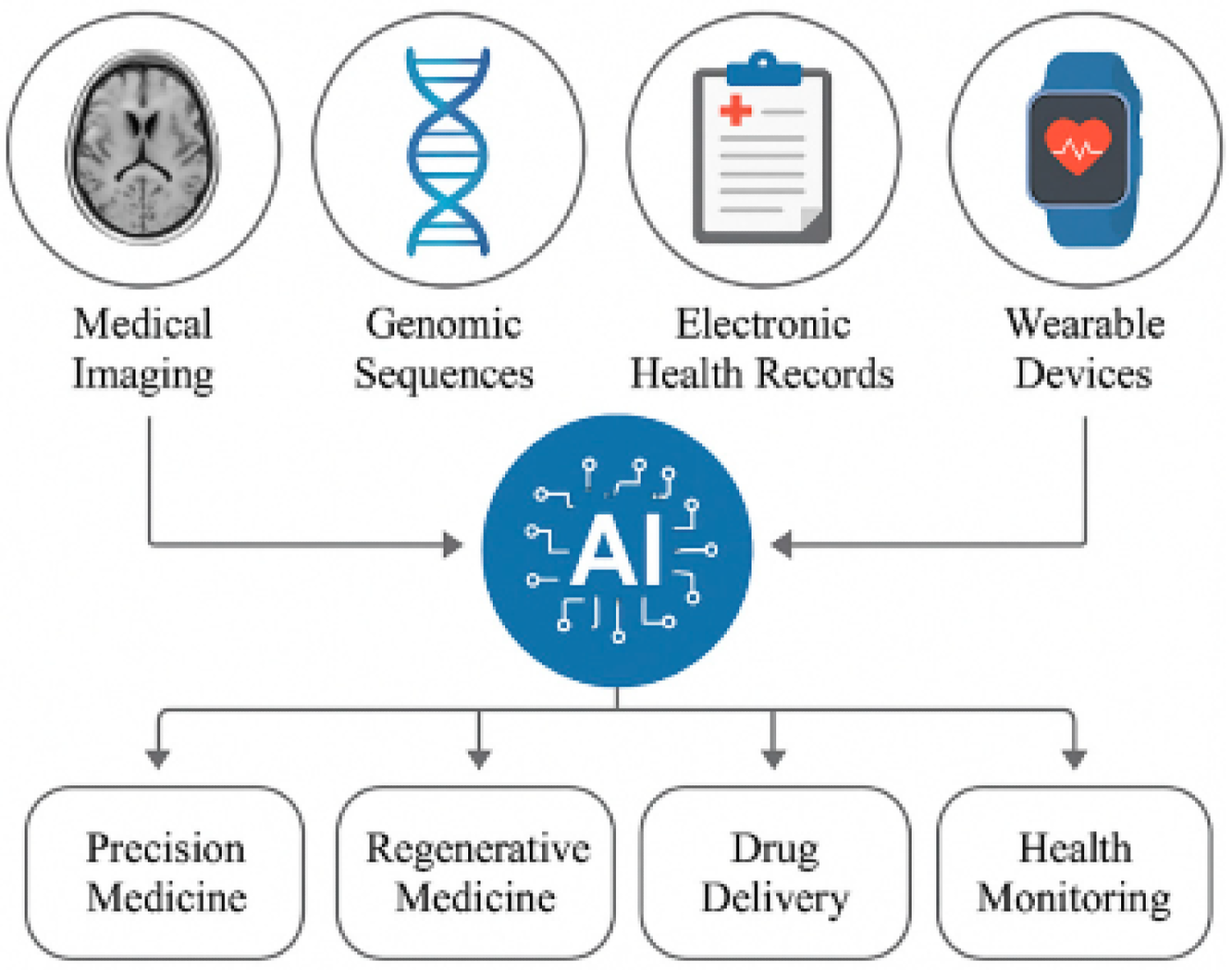
Multimodal AI in Healthcare
Single-modality systems fail in clinical settings because medical diagnoses are rarely based on a single piece of evidence.
The value of combining imaging data with electronic health records (EHR) and real-time physiological signals is critical for achieving a more holistic view of patient health.
In healthcare, multimodal AI improves diagnostic accuracy by explaining the hidden correlations.
It explains the connections between visual indicators in scans and textual descriptions in clinical notes that might be overlooked when analyzed separately.
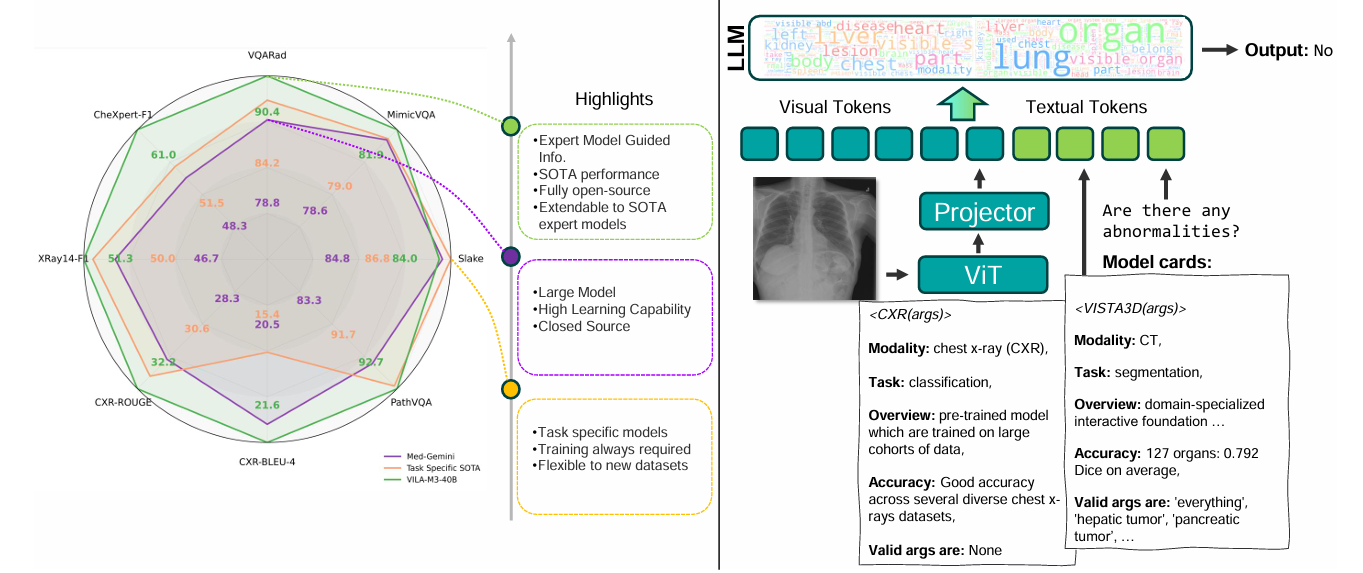
For example, models such as VILA-M3 (NVIDIA's multimodal radiology agent) are trained on pairs of medical images and text reports. They can take an MRI scan as input, along with the patient's textual symptom history.
The model can highlight a suspicious tumor in the image (Vision) and explain why it is suspicious based on the patient's history of smoking or family genetics (Text).
Here's how multimodal AI is being applied across the medical space:
- Automated Radiology Assistance: AI integrates imaging with report text to flag potential issues. This fuses computer vision (imaging data) and NLP (textual data) for more thorough analysis.
- Patient Monitoring: Wearables and room sensors (heart rate, motion, microphones) feed AI that correlates live signals with medical charts for early warning of problems.
- Speech and Documentation: AI transcribes doctor-patient conversations and links them to patient records to speed up chart updates.
- Clinical Decision Support: Systems can analyze a patient's photo and symptom description to suggest tests.
Multimodal AI in Biotech and Pharma
In the biotechnology and pharmaceutical industries, multimodal AI is accelerating research and development (R&D) by using lab images, experimental metadata, and scientific literature to find new drug candidates.
Traditionally, drug discovery has been a linear and high-risk process.
But multimodal AI combines diverse data sources such as genomic sequences, chemical structures, and clinical insights to create a more dynamic approach to finding new drug targets.
Here are some ways that multimodal AI is influencing biotech:
- Target Identification: AI systems ingest genomics, proteomics, and imaging data together to score disease-gene links, helping scientists select drug targets.
- Mechanism of Action: AI can reveal how drugs work by analyzing cell images, gene expression, and compound data jointly.
- Patient Stratification: Models link trial results, molecular data, and patient EHRs to predict treatment response.
- Lab Automation: Robotic lab systems use vision and sensor data to autonomously perform experiments and report results.
Multimodal AI in Automotive and Mobility
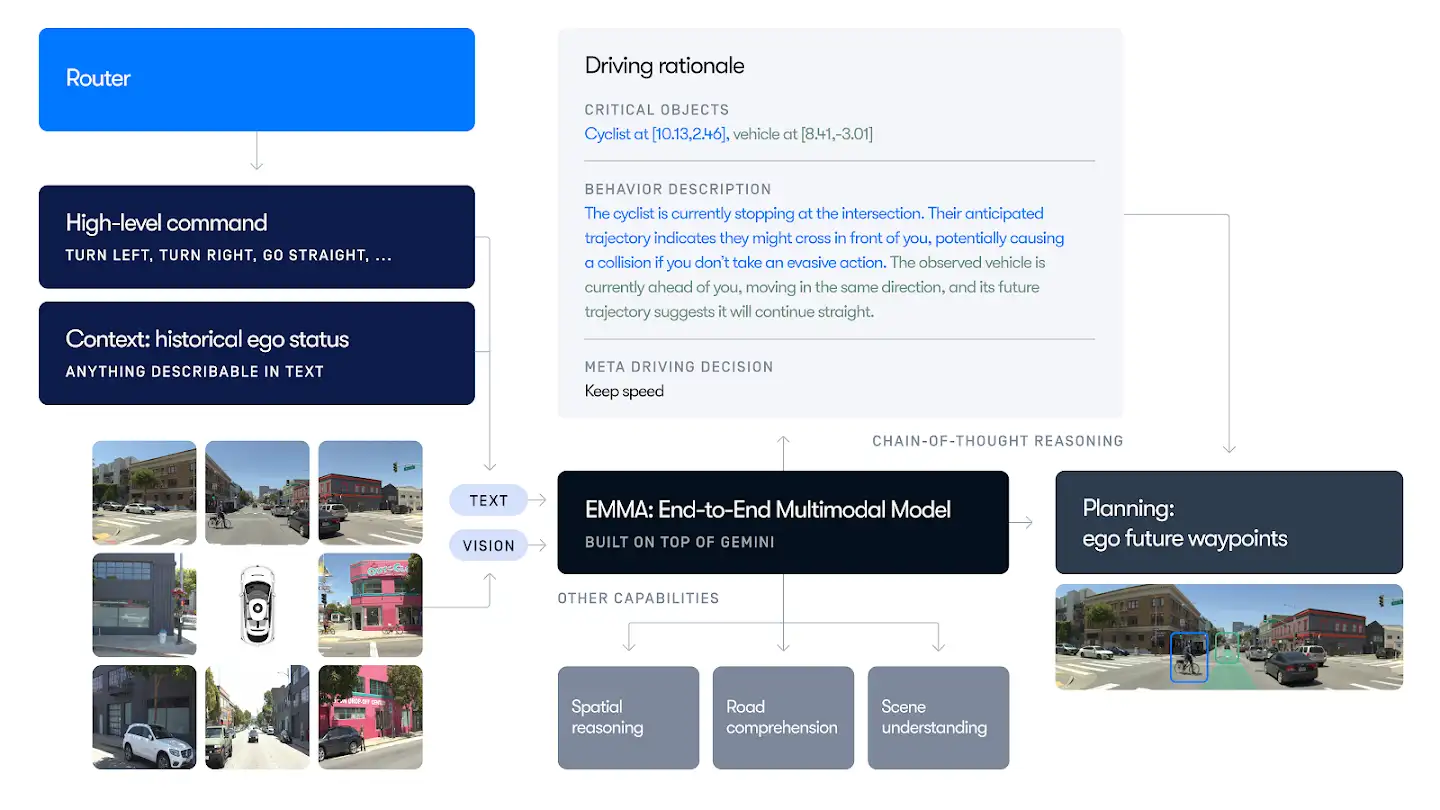
Self-driving cars fuse camera video, LiDAR/radar sensors, and map data to perceive the environment.
A multimodal model can process raw camera feeds plus spatial or textual map inputs to plan trajectories and avoid obstacles.
For example, Waymo’s EMMA research model uses an end-to-end multimodal approach. It processes camera images together with contextual data (as text tokens) to predict vehicle trajectories, road graphs, and detected objects.
Also, this paper shows that combining video, LiDAR, and radar inputs greatly improves object detection and scene understanding under adverse conditions (rain, fog).
Multimodal systems can better handle complex driving scenarios and ensure safety by reasoning across visual and sensor modalities.
Here are some key multimodal AI applications in automotive domains:
- Driver Assistance: AI integrates dashcam video, ultrasonic sensor data, and navigation maps to warn of lane departures and obstacles.
- In-Cabin Monitoring: Combining infrared camera feeds, driver gaze tracking, and car telemetry helps detect drowsiness or distraction.
- Crash Analysis: Post-accident, AI can merge event-camera video, black-box data, and repair photos to understand causes.
Multimodal AI in Robotics
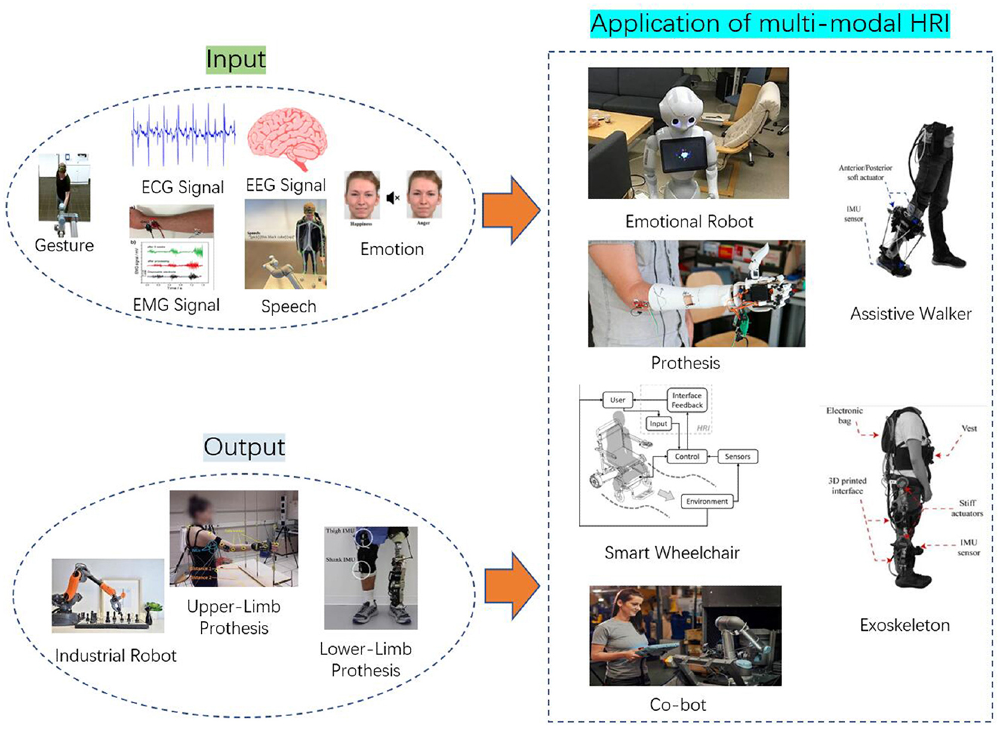
Modern robotics depends on multimodal perception to navigate and interact with the physical world.
In warehouse automation, autonomous mobile robots (AMRs) use computer vision, LiDAR, and real-time data to pick and pack items with high accuracy.
Unlike older, pre-programmed machinery, these multimodal AI-powered robots learn from their environment, adapting their routes on the fly to avoid obstacles and congestion.
Here are some key applications:
- Vision and Touch: A factory robot might use cameras (visual) and force sensors (touch) to grasp objects safely.
- Speech and Vision: Assistive robots combine speech recognition with gesture and face recognition for intuitive control.
- Location and Audio: Delivery drones use GPS (sensor) and visual cues from cameras to navigate while also processing radio signals.
Multimodal AI in Retail and E-commerce
Retailers are increasingly using multimodal AI to blend store video with transaction logs and product knowledge to optimize both physical and digital operations.
The most recognizable example is cashierless checkout.
Systems used in automated stores track customers via cameras as they pick up items, while weight sensors on shelves and POS events provide secondary verification.
This combination of visual data and sensor data creates a frictionless experience where customers can simply "grab and go."
Here is a list of some notable multimodal AI applications in retail and e-commerce:
- Store Checkout: Camera feeds, weight sensors, and shelf RFID tags can replace barcodes at cashier-less checkouts. AI analyzes video of a customer’s actions, item weights, and sensor logs to verify purchases.
- Inventory Management: Retailers can merge shelf-camera images with point-of-sale transactions and RFID readings to track stock in real time. For example, Walmart uses shelf cameras and RFID data to keep inventory up to date and for multi-behavior recommendations.
- Product Recommendations: Online retailers combine browsing behavior (clicks, dwell time) with product images and user reviews (text) to suggest items.
Multimodal AI in Security and Surveillance
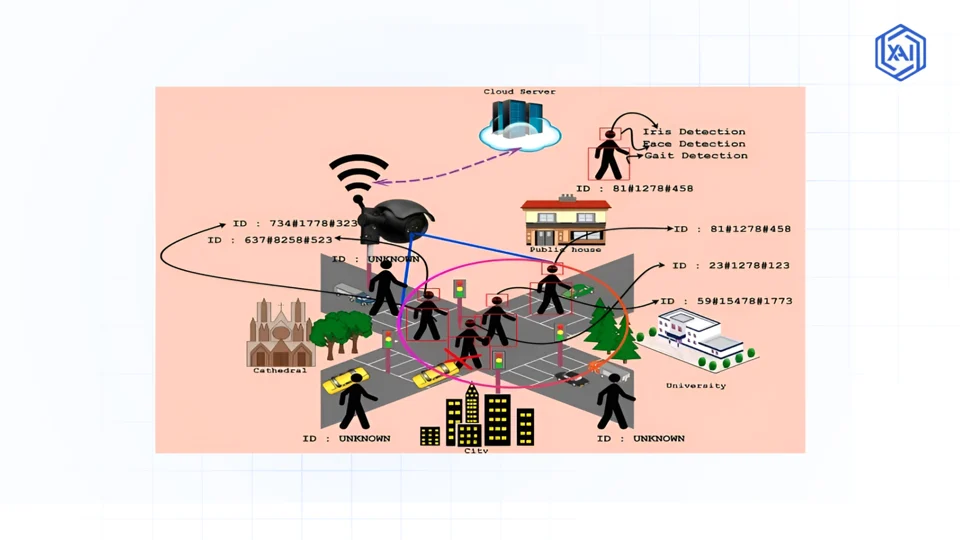
In the security sector, context-aware detection helps reduce false alarms and improve threat response.
Shadows might fool a system that relies solely on video. But a multimodal system that detects a sound and a visual anomaly simultaneously is far more reliable.
Here are some key applications:
- Incident Detection: A multimodal system may fuse CCTV video with audio from microphones to spot disturbances. For example, linking video feeds and audio analysis lets the AI detect aggression or glass-breaking more reliably than cameras alone.
- Behavior Recognition: AI combines video of crowds with social-media text mining. For instance, a video might show a group gathering, and linked social media posts about a protest can alert authorities immediately.
- Access Control: License-plate cameras, badge log scanners, and entry logs can be fused. For example, linking license-plate recognition (video) with gate-access logs (text) lets a system flag unauthorized vehicles automatically.
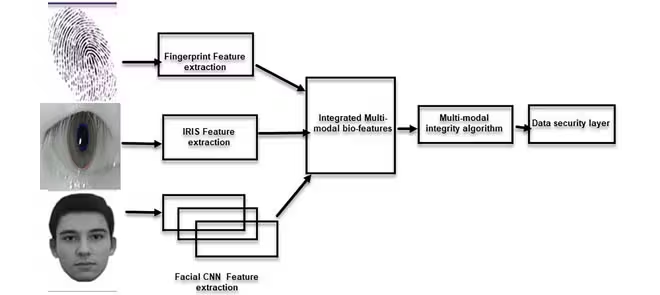
- Biometric ID: Verification can merge face recognition (image), fingerprint scans (sensor), and ID document OCR (text) to improve accuracy.
Multimodal AI in Education and E-Learning
Education platforms are using multimodal AI to personalize learning. Traditional systems often rely on text alone, but multimodal models can combine different modalities to support deeper learning experiences.
For example, Duolingo uses text prompts, audio pronunciation, and images together to teach language.
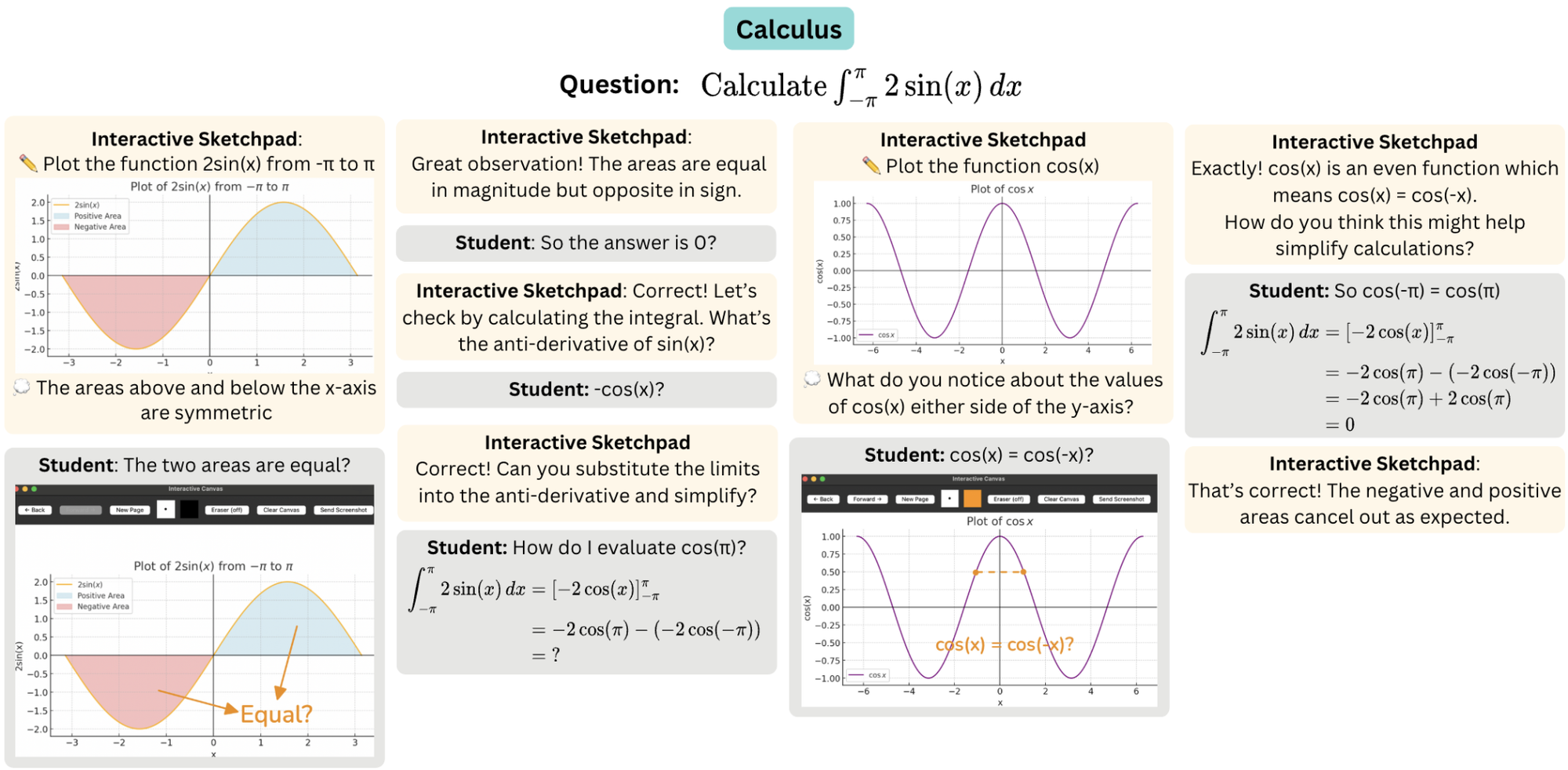
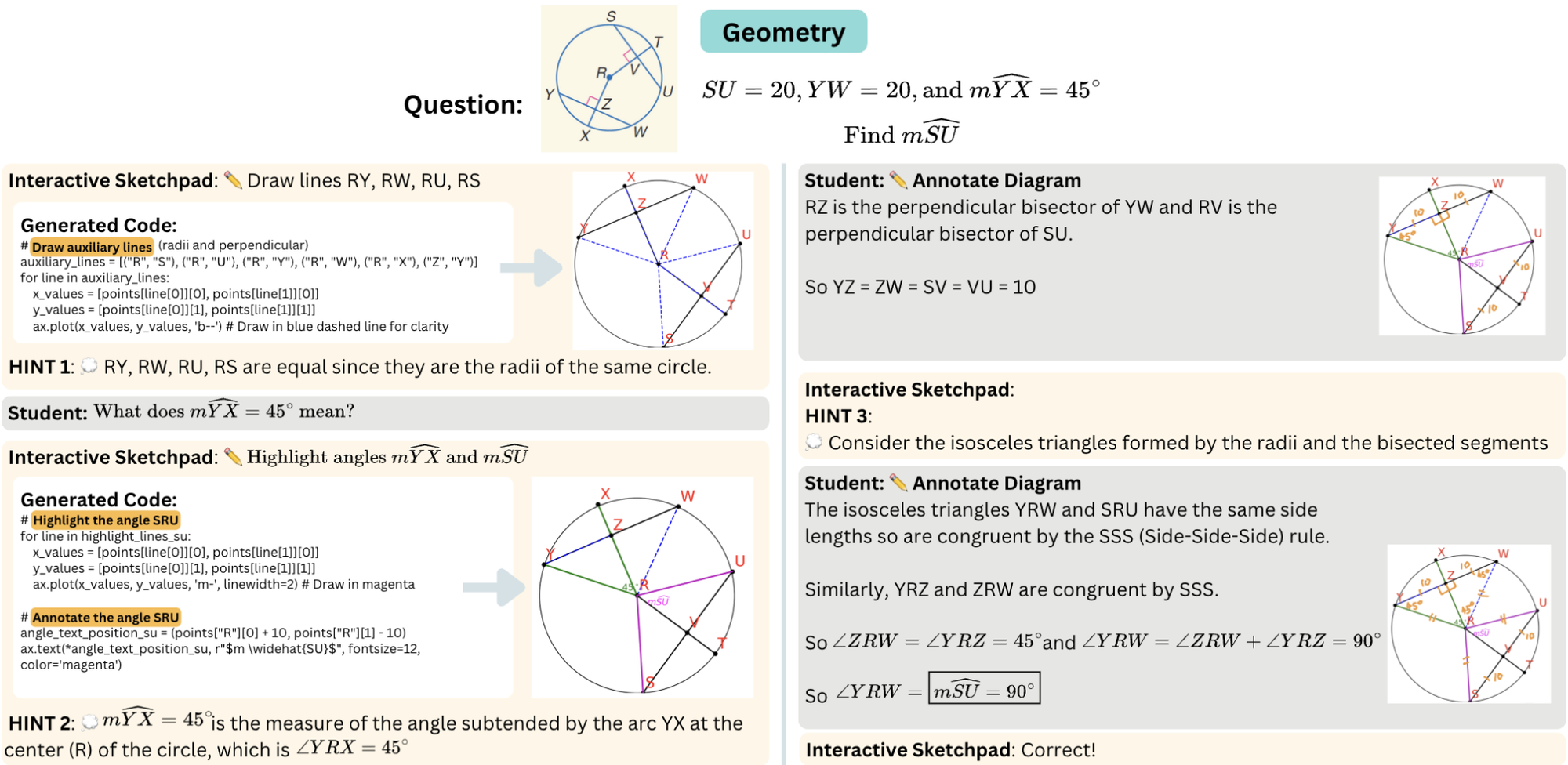
Similarly, recent research introduced interactive, visual problem-solving systems called Interactive Sketchpad.
The system uses a large multimodal model (LMM) to provide step-by-step guidance with both text and visual diagrams and help students engage with challenging subjects such as mathematics.
Here are some key applications:
- Adaptive Learning: Systems analyze a student’s video (eye gaze on screen) along with test answers (text) and audio responses to tailor lessons based on multimodal performance cues.
- Interactive Tutors: AI merges text-based chat, voice input, and shared images (like math diagrams) to interact naturally with students. Tools like Interactive Sketchpad add visual drawing and diagram generation and allow the model to produce and edit graphics that directly support problem solving.
Multimodal AI in Agriculture
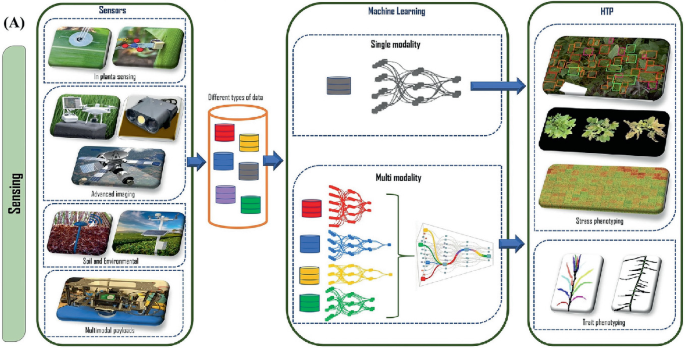
Modern farming uses multimodal AI to optimize yields by combining diverse data types such as aerial imagery, sensor data, and weather information.
Drones or satellites capture multispectral crop images, while ground sensors record soil moisture and nutrient levels.
A multimodal model can also analyze satellite images together with real-time weather forecasts and soil sensor readings to predict irrigation needs or disease risk.
Here’s how multimodal AI is used across agriculture:
- Equipment Automation: Tractors and drones use cameras and IoT sensors to optimize planting. John Deere, for example, combines on-machine camera imagery with sensor feeds to enable precision planting and yield monitoring.
- Livestock Management: Video cameras, RFID ear tags, and wearable sensors can be fused to track animal health and behavior.
- Yield Forecasting: Historical yield (text data), live field images, and climate models are merged to predict output.
Multimodal AI in Manufacturing
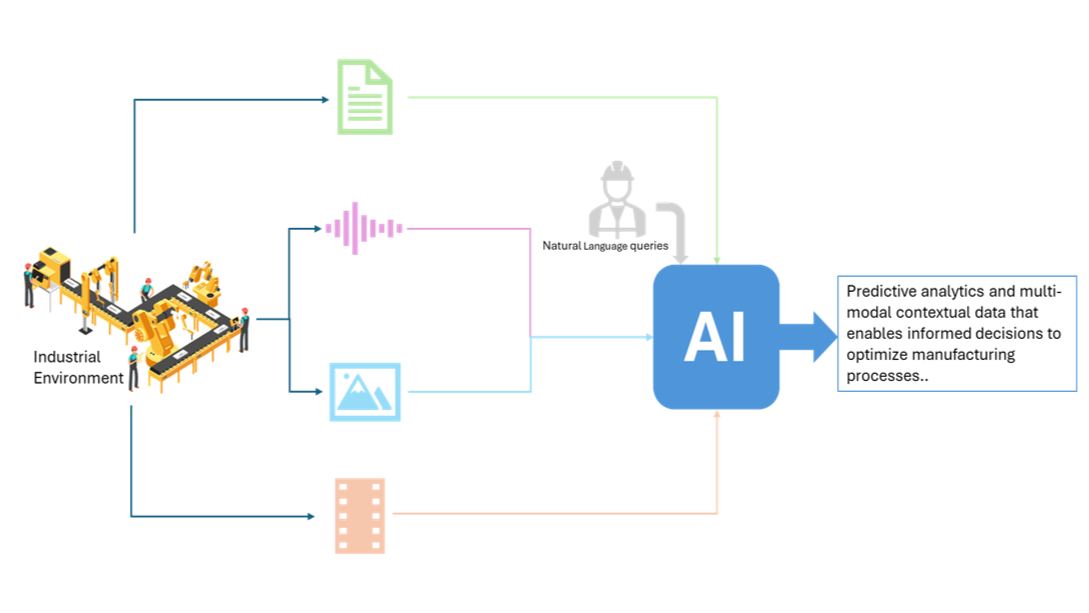
Industrial plants generate diverse data streams that AI can fuse to enable smarter automation.
Applications include:
- Predictive Maintenance: Multimodal AI combines images (thermal camera scans of machinery) with vibration sensors and operational logs to detect equipment faults early.
- Quality Control: Combining high-resolution camera images, laser scans, and sensor readings ensures products meet specs. Multimodal AI can compare a photo of a part against blueprints (text/spec data) to spot defects.
- Process Optimization: Multimodal systems merge IoT sensor streams with video feeds of production lines and machine logs to adjust parameters for efficiency.
Multimodal AI in Sports and Media
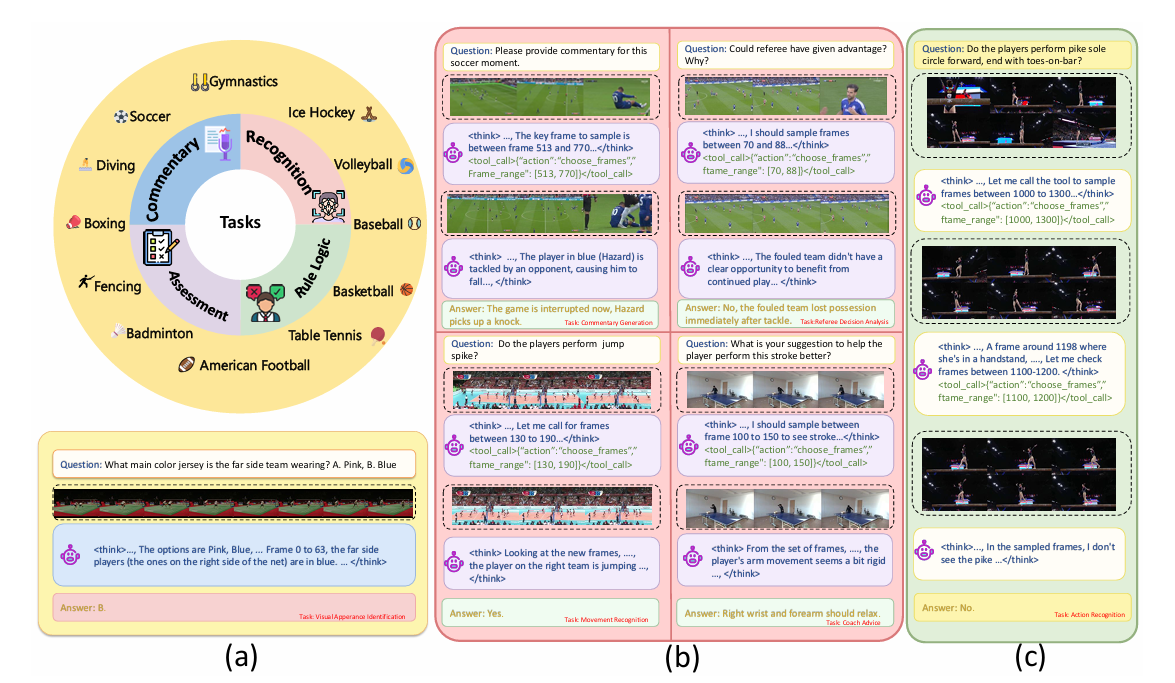
Sports and media industries are using multimodal AI to improve analysis, content creation, and real-time reasoning.
For example, DeepSport, a multimodal large language model, uses a frame extraction tool and an agentic reasoning framework to actively think with videos and examine sequences of frames, audio cues, and contextual metadata. It does this to infer complex events and strategies across different sports.
- Automated Highlights: AI-driven sports editing systems analyze video and audio to find key moments. These tools automatically generate game highlights in minutes by tracking the ball (vision) and detecting crowd cheers (audio).
- Performance Analysis: Wearable sensors on athletes (accelerometers, heart rate) are combined with game video. Multimodal AI correlates body-movement data and on-field footage to improve training and prevent injuries. (analyzing a pitcher’s motion with video and biomechanical sensors).
- Officiating Assistance: Multi-angle camera feeds and sensor data like LIDAR tracking of player positions are fused. Video-assistant-referee (VAR) systems already review plays using synchronized video and audio feedback.
- Content Creation: Virtual and augmented reality experiences merge live game video with stat overlays and commentary transcripts.
Multimodal AI in Finance
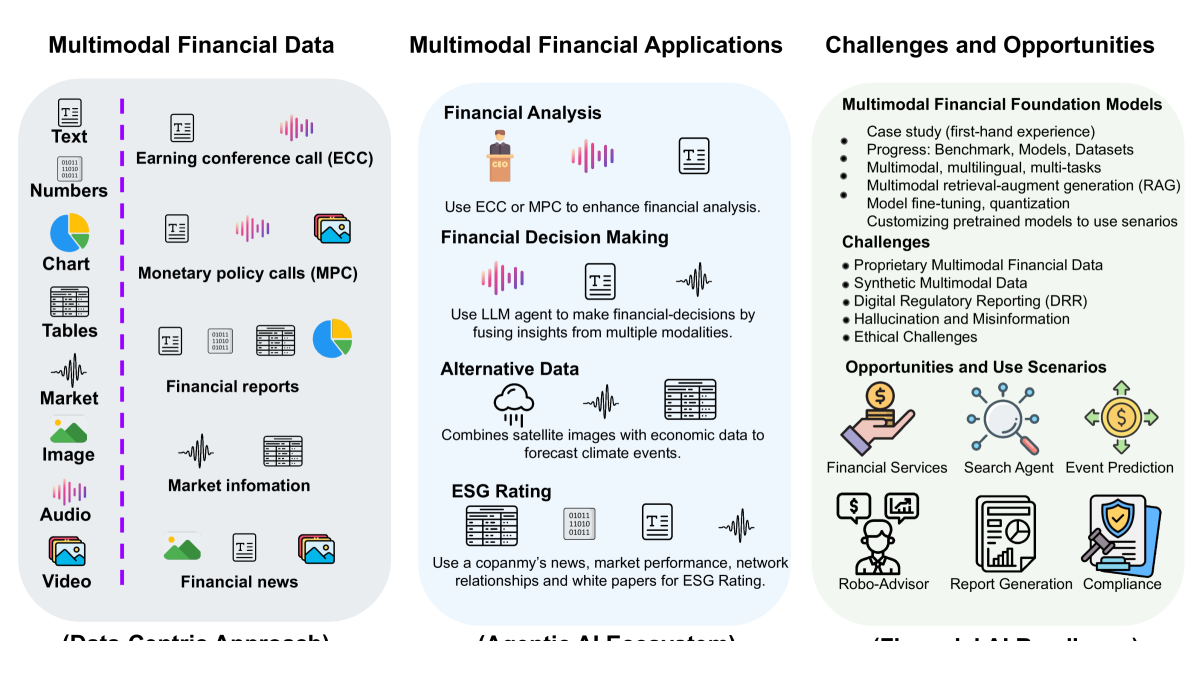
Multimodal AI systems in financial services integrate text, numerical time series, structured tables, chart images, audio, and video for richer reasoning and decision-making.
- Fraud Detection: Multimodal AI models fuse transactional time-series data (numeric), text logs (email threads), and behavioral biometrics (voice, face recognition) to flag anomalies that suggest fraud.
- Document Analysis: Multimodal AI ingests loan documents (text), spreadsheets (tabular), and email context (text) together to extract structured insights, automate onboarding, and enforce compliance reporting at scale.
- Sentiment and Market Trend Analysis: Financial forecasting and sentiment analysis combine natural language (news, analyst reports), chart imagery (candlestick, technical indicators), and structured price feeds to predict trends. Models infer investor mood from textual feeds while correlating that sentiment with price movement patterns evident in technical visuals.
Multimodal AI for Geospatial and Climate
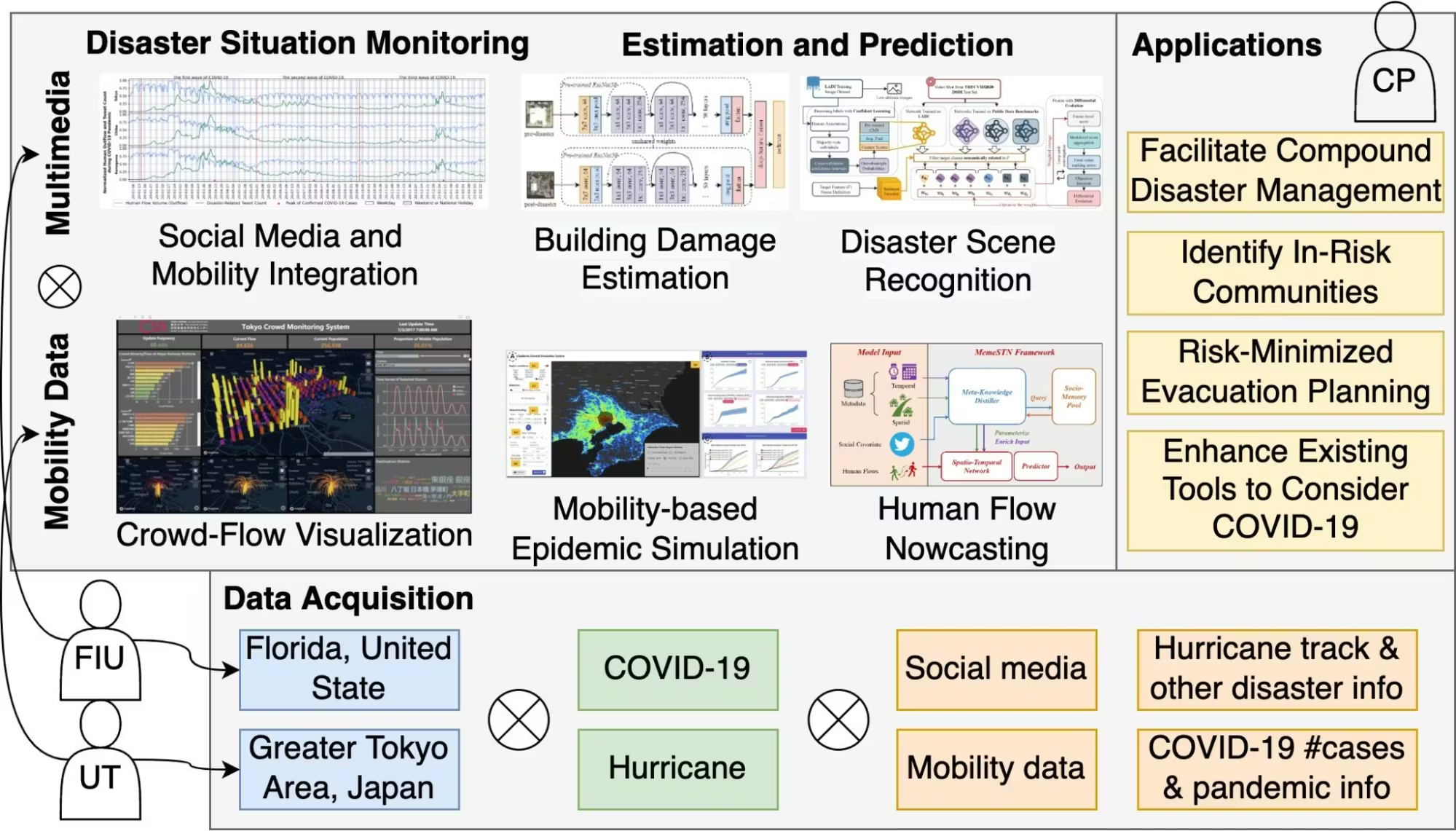
Multimodal AI systems in geospatial help in disaster response and management. They combine diverse data types from satellites, social media, and ground sensors to improve preparedness and recovery.
Combining modalities provides a complete view, predicts impacts, and supports faster, informed crisis decision-making.
Here are some key applications:
- Disaster Mapping: Multimodal AI combines real-time satellite and drone images with social media text and seismic sensor readings to identify affected areas after an earthquake.
- Environmental Monitoring: Fusing satellite images, weather sensor data, and ecological reports helps track climate change effects.
- Urban Planning: City planners use aerial photos, traffic sensor logs, and infrastructure maps together in an AI model to optimize growth.
Strategic Outlook
Looking ahead, multimodal AI will be widespread across many other fields. Large multimodal models will handle ever more diverse inputs, from genetic data to social media, enabling new scientific research.
Companies will invest in developing these systems because combining data streams yields insights no single modality can provide.
Furthermore, on the technical side, multimodal systems demand significant computational resources for training on diverse datasets. Advances in hardware and data-fusion techniques will be needed to meet this.
There will also be a focus on making multimodal AI understandable and protecting user privacy.
Conclusion
Multimodal AI is helping in building the foundation of next-generation intelligent systems across domains such as healthcare, manufacturing, education, finance, sports, and autonomous systems.
But multimodal models used in these applications depend far less on model architecture alone and far more on the quality, alignment, and consistency of the underlying training data.
Also, Organizations must navigate complex ethical and regulatory landscapes, ensuring that their systems are transparent and grounded in the specific knowledge of their domains.

