
![The Ultimate Guide to Multimodal AI [Technical Explanation & Use Cases]](https://storage.ghost.io/c/48/f4/48f4b614-5c29-430d-9cb3-e0b3f34395f3/content/images/size/w2000/2025/12/Robotics--6-.png)
Artificial intelligence (AI) systems are learning to see, hear, and understand the world the way people do.
Their inception began with single-channel information systems and has evolved into multimodal AI systems that process, integrate, and reason across multiple data types.
Multi-modal AI yields a more accurate understanding than single-modality AI models, since it can handle voice commands, written text, and visual cues.
In this guide, we'll walk you through everything you need to know about multimodal AI.
Here’s what we cover:
- What is multimodal AI (vs. unimodal AI)
- Benefits of multimodal AI
- How multimodal AI works
- How multimodal AI is trained
- How to evaluate multimodal AI
- Popular multimodal AI models and architectures
- Use cases and applications of multimodal AI
- Limitations and risks
- The future of multimodal AI
Training powerful AI models requires high-quality and perfectly annotated datasets across text, images, audio, video, and other modalities.
And most teams struggle to annotate and prepare this data at scale.
We at Unitlab make data management, preparation, and labeling faster, more accurate, and more efficient with AI-assisted labeling workflows.
We support annotations for tasks such as segmentation, OCR, object detection, and more. We will soon support multimodal data annotation.
Interested in preparing high-quality data for your AI project? Try Unitlab for free!
What Is Multimodal AI (vs. Unimodal AI)
Multimodal AI refers to artificial intelligence systems that are capable of processing and generating two or more different kinds of data (known as modalities).
These modalities include text descriptions, visual data, audio data, video, and structured sensor data such as LiDAR, thermal imaging, or GPS information.
Multimodal AI is like human perception of the world. For instance, when a doctor figures out what disease someone has, they don't just use one piece of information. They consider many things at the same time:
- A medical report (text)
- X-rays (images)
- Tone of voice (audio)
- Physical symptoms (visual cues)
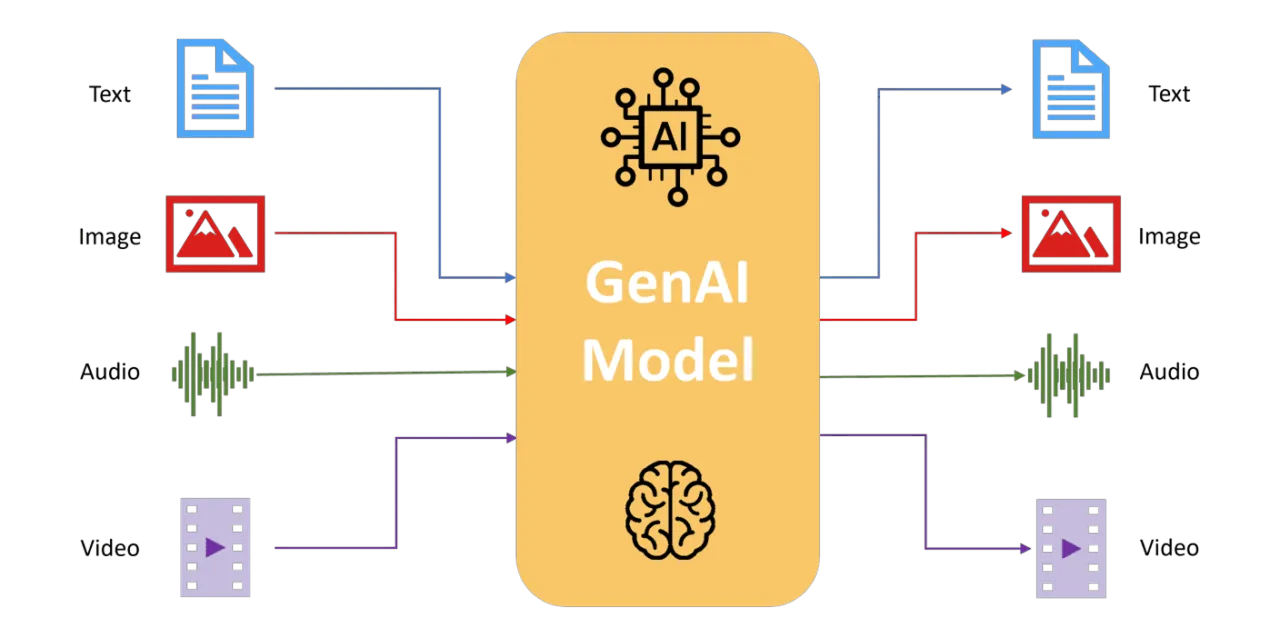
The primary difference between multimodal AI and unimodal AI is the number of data inputs that they can process.
Multimodal AI models fuse diverse data types into a single reasoning process (unified representation) when training and inferring ,so they can learn relationships between them.
In contrast, a unimodal AI model handles only one type of input data and limits its context to a single modality.
For example, a text-only chatbot trained or a vision model trained on images would not generalize well to other types of input.
Here is a summary of multimodal AI vs. unimodal AI key differences:
Benefits of Multimodal AI
Multimodal AI offers several key advantages over unimodal approaches:
- Richer Context and Higher Accuracy: Multimodal models gather more information by combining different types of inputs. For example, combining images and text can help clear up confusion that might arise when only one is used. In fact, research shows that multimodal AI systems outperform roughly 6% to 33% over single-source models in diagnostic performance.
- More Natural Interactions: Multimodal AI allows for more human-like interaction. For example, a virtual assistant could understand spoken questions and look at a shared image, or a robot could interpret gestures along with spoken words. It leads to artificial intelligence that works more like a human (who uses voice and sight together).
- Robustness to Missing or Noisy Data: If one type of input is missing or not clear, the system can rely on the other types. For example, if an image feed is poor, audio or text can help fill in the gaps. This redundancy makes multimodal systems more reliable than unimodal models.
- Cross-domain Generalization: Knowledge can transfer between modalities. For instance, if a model learns about visual concepts, it can also understand related text descriptions of unseen scenes. Cross-modal learning improves generalization and helps in data-scarce situations (when data is limited).
How Does Multimodal AI Work?
Understanding how multimodal AI works requires examining the three-part pipeline. As multimodal models are built using domain-specific transformers to encode input modality data into a single representation, with efficient cross-attention mechanisms.
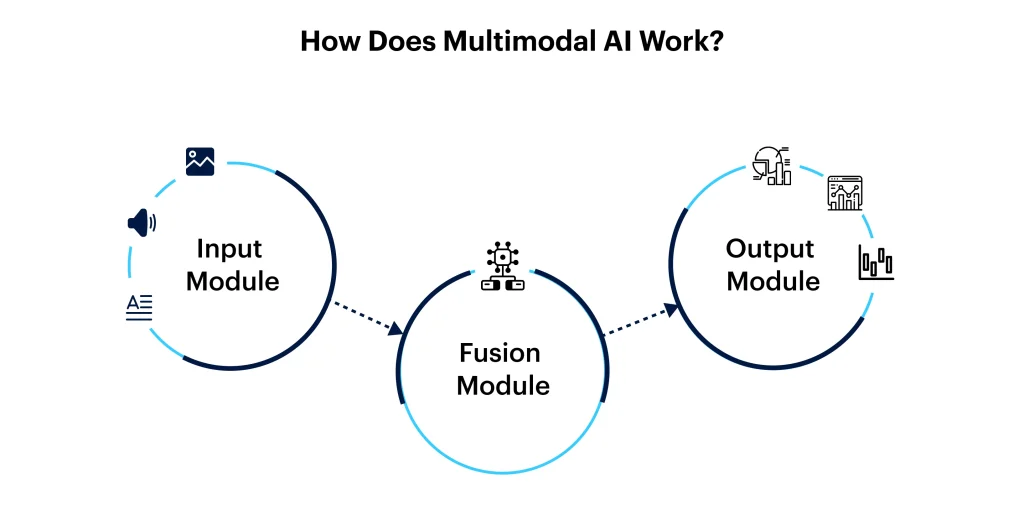
Input Module (Encoders)
Each modality is first processed by its respective encoder (unimodal neural networks), which converts it into machine-readable feature vectors (lives in an embedding or mathematical space).
- Text encoders: Transformer-based language models like BERT or GPT process textual data and convert words into embedding vectors that capture semantic meaning.
- Image encoders: Vision Transformers (ViT) or Convolutional Neural Networks (CNNs) process visual data and extract features from pixels to identify objects, textures, and spatial relationships.
- Audio encoders: Speech models convert audio data (speech, music, or environmental sounds) into representations the model can work with.
- Video encoders: Process temporal sequences, combining both spatial (what's in each frame) and temporal (how things change over time) information.
Fusion Module
The encoded features from different modalities are then merged to create a unified representation.
But the timing and method of data integration (known as fusion) are critical to how multimodal AI works and its overall performance.
There are different fusion strategies:
- Early fusion
- Late fusion
- Hybrid and Intermediate fusion
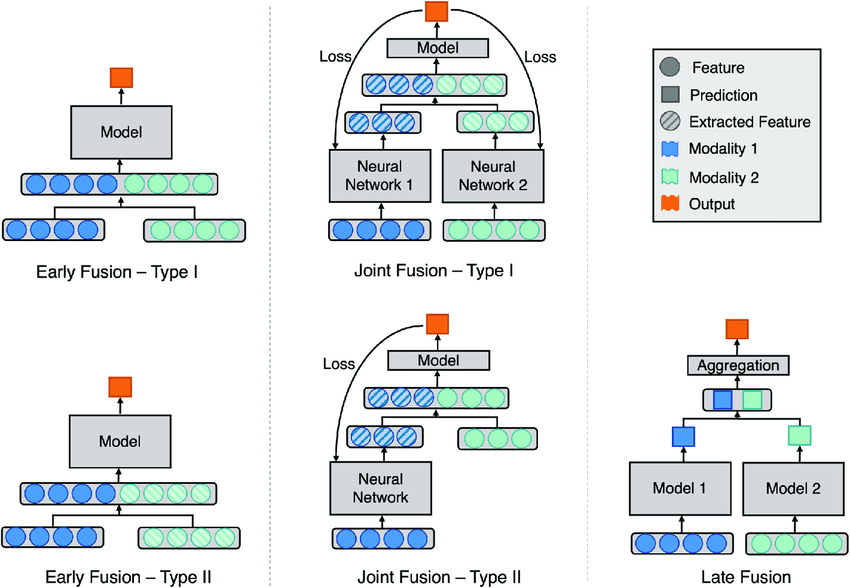
Early Fusion (Feature-Level Fusion)
Early fusion combines initial features (embeddings) from different modalities early in processing.
For example, concatenating text embeddings and image embeddings into a single vector before feeding them to a joint model.
It works well when modalities are tightly synchronized, and you want the model to learn low-level interactions between different types of data.
But it requires precise data alignment (aligned timestamps for video and audio data) and can struggle when modalities have very different structures.
Late Fusion (Decision-Level Fusion)
Late fusion process each modality independently through its own encoder and model layers.
The outputs (decisions) from these separate models are combined only at the end (averaging scores, voting, or another model).
Late fusion is more effective for missing modalities and enables the use of strong pre-trained unimodal models, but it often fails to capture fine-grained interactions among data types.
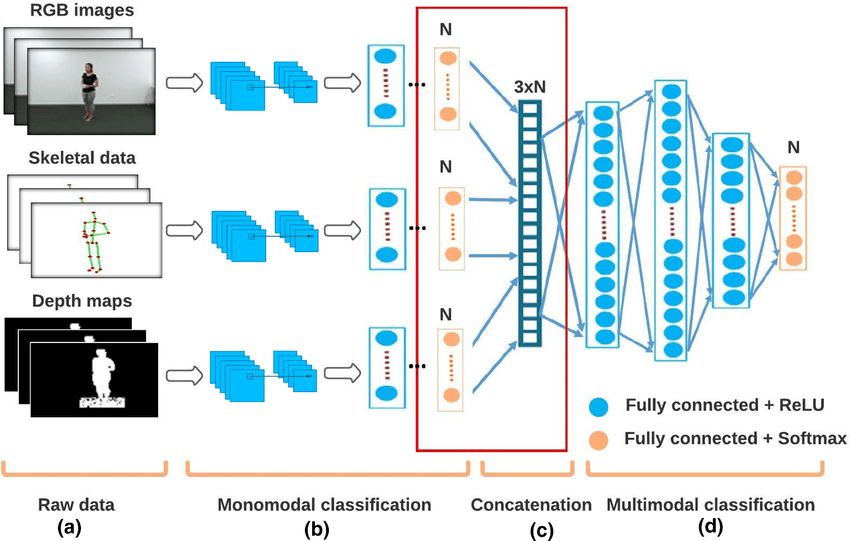
Hybrid and Intermediate Fusion (Mid-Level Fusion)
Hybrid fusion mixes both approaches (or uses attention mechanisms) to let the model weigh and align information across modalities. And many modern large multimodal models use hybrid strategies.
Output Module (Decoders)
Once the information is fused and processed by a universal backbone, it goes to the output decoders for the final result.
For generative tasks (image captioning, translation), this is a decoder that generates the desired output (creating corresponding images from text descriptions).
For example, in image captioning, a text decoder produces the caption text. In a multimodal QA system, it might output the answer text.
How Multimodal AI is Trained
Training multimodal AI requires collecting and annotating large multimodal datasets. You need diverse data sources (images, text, audio) that match the desired tasks (visual Q&A, captioning, classification).
Also, ensuring the modalities are paired correctly (an image with its caption, or a video with its transcript).
Once you have perfectly aligned input data, the next step is to label it as needed.
Annotation may involve multiple tasks at once (drawing bounding boxes and labeling text in an image). Often, a human-in-the-loop (HITL) approach is used, where AI tools suggest labels that humans correct or refine.
Specialized annotation platforms such as Unitlab (with multimodal data annotation forthcoming) provide tools designed explicitly for multimodal data labeling.
It lets users chain multiple auto-labeling models, such as an object detector, a segmenter, and an OCR (text-recognition) model, to annotate a single dataset in parallel.
Annotators can then review and fix these AI-generated labels, creating a high-quality multimodal training set. AI-assisted plus human review workflow speeds up labeling and improves consistency.
Next, you need to preprocess the data and convert each input type into a model-friendly format (tokenizing text, normalizing images, and extracting audio features).
Once all set, you can start feeding the data through the multimodal model pipeline (encoders + fusion + decoder) and optimizing the model end-to-end.
Large-scale models often use transfer learning, like initializing image/text encoders with pretrained networks and fine-tuning the fusion layers on multimodal data.
Evaluating Multimodal AI
There are multiple benchmarks and metrics that ML engineers use to evaluate AI models' abilities in reasoning, perception, and the integration of different types of data.
Key Benchmarks and Datasets
- MMMU (Massive Multi-discipline Multimodal Understanding): It evaluates models on massive, multi-disciplinary tasks that require college-level subject knowledge and deliberate reasoning.

- It includes 11.5K questions across subjects such as Health and Medicine, Tech and Engineering, and Business, using 30 heterogeneous image types, including chemical structures and music sheets.

- VQA (Visual Question Answering) and VQAv2: Datasets where a model answers text questions about images. VQAv2 is specifically balanced to mitigate language priors and ensure the model actually looks at the image rather than just guessing based on common text patterns.

- DocVQA and ChartQA: These focus on understanding complex documents and charts. DocVQA requires the model to understand text embedded in forms and diagrams.

- While ChartQA tests the ability to extract data from various types of graphs (bar, line, pie) and perform trend analysis.
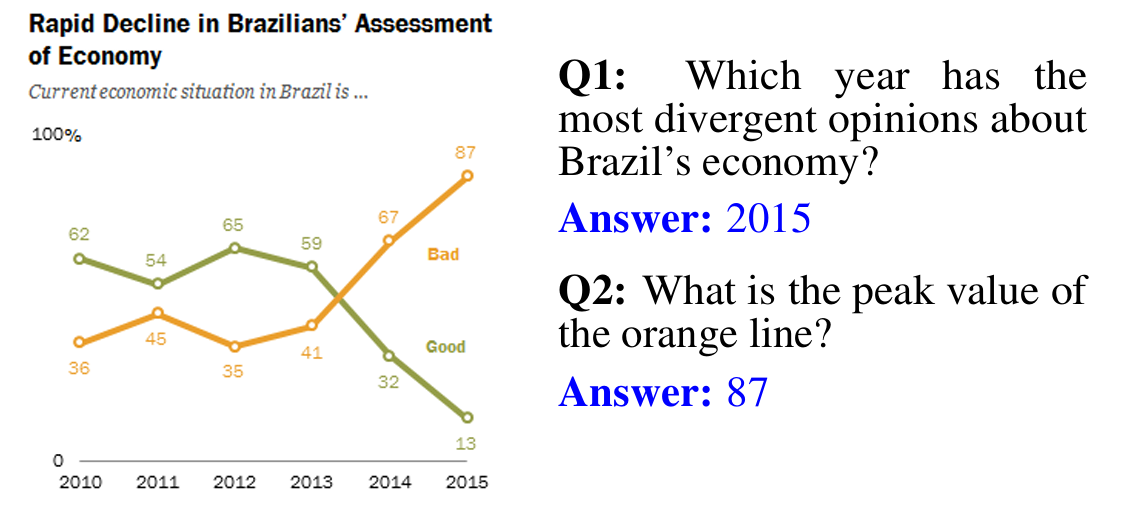
- MMMU-Pro: It is a stronger version of the MMMU benchmark that filters text-only answerable questions and augments candidate options to test true multimodal reasoning better.

- Humanity's Last Exam: A high-level benchmark designed to be Google-proof, consisting of 2,500 questions across dozens of subjects to evaluate PhD-level expert knowledge in multimodal settings.

There are several specialized metrics ML engineers use to quantify performance in multimodal settings, particularly for tasks involving generation and retrieval.
Human-in-the-loop and Stress-Testing
In addition to automated metrics, human evaluation (human-in-the-loop) is often used for subjective tasks.
Human testers check for errors that metrics miss.
They also perform “stress tests” by probing the model with unusual or adversarial inputs (misleading images or impossible questions) to show failure modes like hallucinations or bias.
These steps help ensure reliability and safety before deployment.
Popular Multimodal AI Models and Architectures
Multimodal AI has rapidly become the default for frontier models, so it helps to look at a few flagship systems and see how each one handles different modalities and context windows.
- GPT-5 (OpenAI): OpenAI's flagship model, GPT-5, is a unified model that handles text, images, video, and audio and has built-in reasoning capabilities. It features an automatic routing system that alternates between fast responses and deep reasoning based on the task complexity.
- GPT-5 supports a context window of up to 400,000 tokens (a small patch of an image or a slice of audio time) and is reported to be 45% less likely to hallucinate than its predecessor, GPT-4o.
- CLIP (Contrastive Language–Image Pre-training): CLIP is a vision–language model trained to align images and text in a shared embedding space, which makes it useful for tasks like cross-modal retrieval and zero-shot image classification.
- Gemini 3 (Google): The Gemini 3 series supports multimodal understanding and processes text, images, audio, and video. It features a 1 million token context window and currently leads the MMMU-Pro and Video-MMMU leaderboards.
- Claude 4 and 4.5 (Anthropic): Anthropic's Claude 4 family models work with text and images. They are good at understanding visual information like charts, diagrams, and photos with impressive accuracy.
- They are also widely considered the Architect for web development and complex logic. Claude 4.5 Sonnet dominates the SWE-bench Verified coding benchmark, scoring 80.9%, and can run autonomously for over 30 hours.
- ImageBind (Meta): ImageBind connects six modalities, such as images, text, audio, depth, thermal, and IMU signals, into a shared representation space. It is ideal for multi-sensor / multi-stream scenarios (robotics, AR/VR) and other settings that combine several non-text modalities.
- Qwen3-VL (Alibaba): Qwen3-VL-235B (MoE architecture) tops CFEval and WritingBench for logic and generation, with 262K-token context and multilingual OCR across 32 languages. Smaller variants like 32B run on mobile devices
- InternVL 3.5: InternVL 3.5 is an open-source model and rank for MMMU and ChartQA on several leaderboards. It is proficient at document understanding and "deep parsing" OCR, such as identifying complex geometric figures in textbooks. It offers 16% reasoning gains and 4x faster inference versus InternVL 3.
Multimodal AI Use Cases and Applications
Multimodal AI is already at work in many domains. Below are several real-world multimodal AI applications:
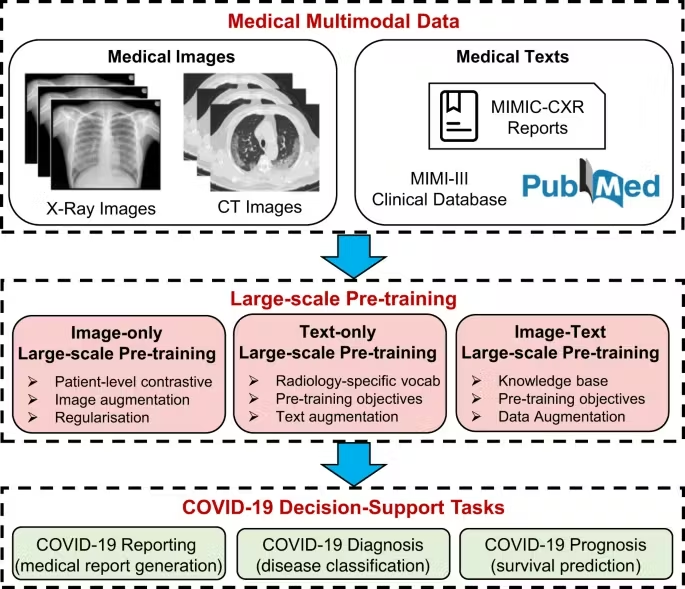
- Healthcare Diagnostics: Multimodal AI can merge patient records (text) with image based data (X-rays, MRIs), and even genomics to improve diagnosis.
- For example, Microsoft’s Project InnerEye and IBM Watson Health explored image-text fusion to assist doctors with disease prediction and treatment plans.
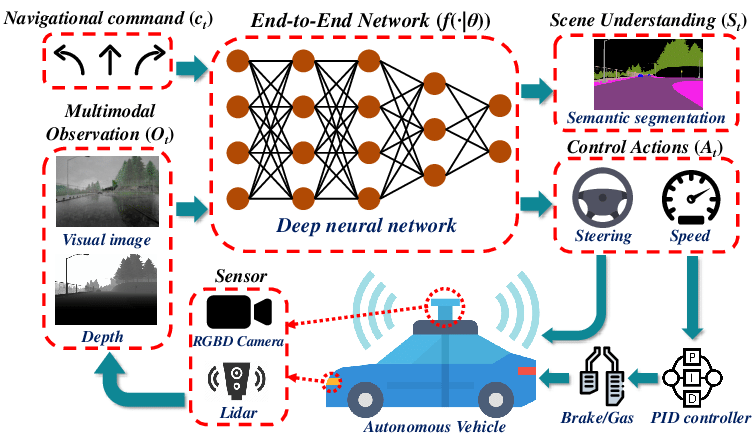
- Autonomous Vehicles: Self-driving cars rely on multimodal perception for safe navigation. They combine camera feeds (vision) with LiDAR/radar (depth and motion sensing) and sometimes GPS/data maps.
- For instance, Waymo and Tesla vehicles merge camera images and LiDAR point clouds to detect obstacles, read traffic signs, and make driving decisions. In fact, some studies show that combining visual, depth, and positional data yields much safer driving than any single sensor alone.
- Finance and Banking: In fintech, AI models analyze documents, images, and text together. Models can automate tasks like contract review and risk assessment by jointly analyzing text and document layout.
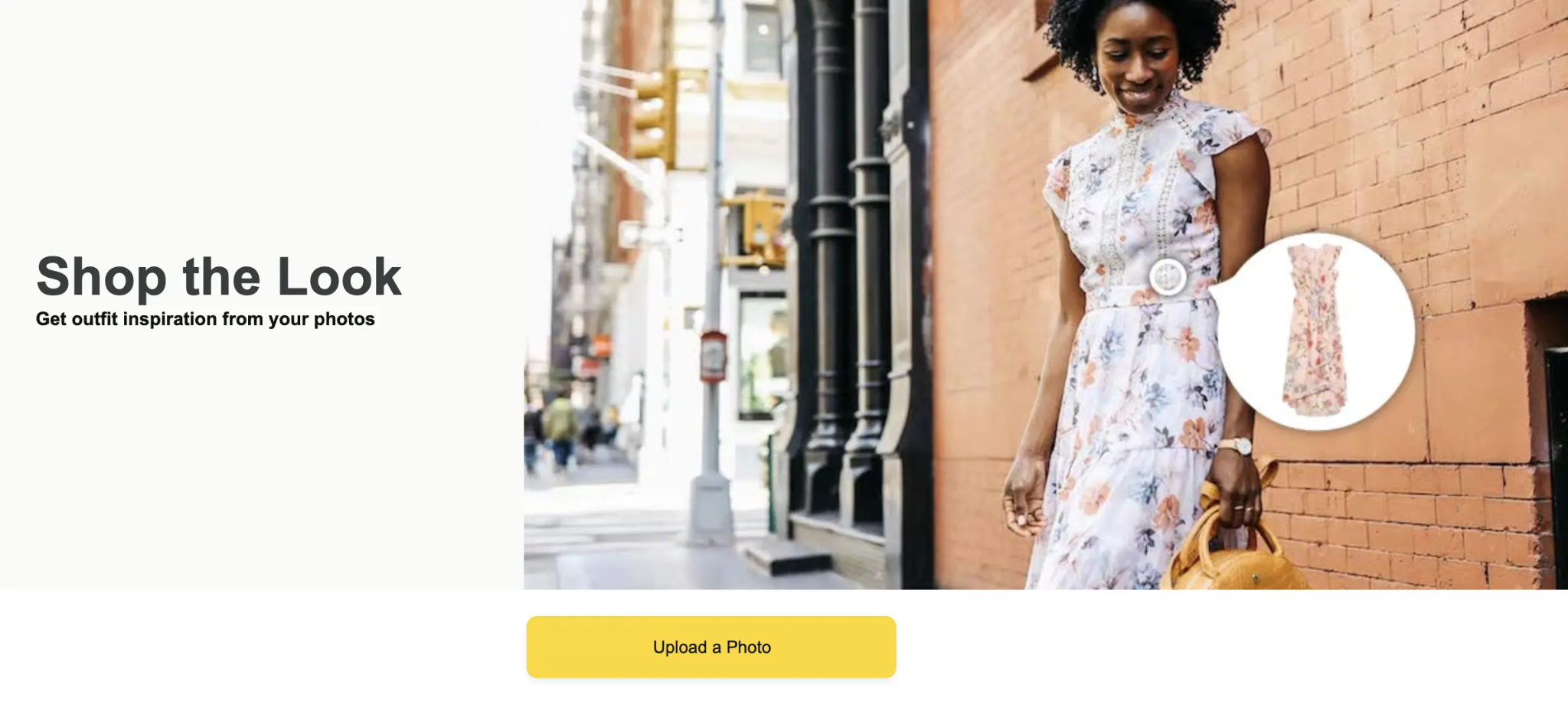
- Retail and E‑Commerce: Online retailers use multimodal AI to boost the shopping experience. Systems can offer better recommendations by combining product images, descriptions, and user reviews.
- A prime example of this in action is Amazon's StyleSnap. It uses computer vision and natural language processing (NLP) to suggest similar products based on item photos. StyleSnap even optimizes shipping by matching package images to size specs.
- Education and Training: AI-powered tutoring app integrates pre-recorded lectures with dynamic, interactive question-and-answer functionality. A student watching a video can pause, type a question, and receive AI-generated explanations that are contextually linked to the material just presented.
- According to an experiment, a multimodal AI education system improves the accuracy rate by 23.6% over traditional evaluation methods.
- Manufacturing and IoT: In industrial settings, AI can combine sensor data (audio/vibration), camera images, and maintenance logs.
- For example, Bosch uses AI to monitor factory machine sounds and visuals and predict equipment failures before they occur. The system detects anomalies more reliably and reduces downtime by fusing video of machinery with sensor readings (such as temperature or sound).
Limitations and Risks of Multimodal AI
Multimodal AI can be powerful but is more complex. It demands more computing resources, quality data, and attention to privacy and fairness. Here are some of the challenges:
- High Computational Cost: Multimodal models tend to be large and resource-intensive. Encoding images and processing text in a single model requires many parameters and high memory usage. Training or even inference can require dozens of gigabytes of GPU memory.
- Data Quality and Hallucinations: Multimodal models can produce hallucinations (nonsensical outputs), especially on visual content.
- For example, a vision-language model might confidently describe details not present in an image or video. So, ensure high-quality and aligned training data; otherwise, the model may combine modalities incorrectly.

- Privacy and Ethics Concerns: Because multimodal AI handles sensitive data from different sources, it raises privacy risks. An AI using speech, video, and location data might unintentionally expose private information by linking across modalities.
- There is also the risk of bias. If one modality (like facial images) encodes a bias and another (like job application text) another bias, their combination can amplify discriminatory outcomes. Handling multimodal data requires strict controls, including anonymization, secure storage, and bias audits.
- Dependence on Data Alignment: Aligning different modalities in training data can be complex. For example, pairing the right text with the right image at scale is labor-intensive.
- Poor alignment (wrong captions, mis-transcribed audio) degrades model performance. This dependence on multi-source datasets makes data preparation more complex than for unimodal models.
The Future of Multimodal AI
The future of multimodal AI involves deeper integration across various modalities and aims for autonomous agent-like behavior.
- Embodied AI and Robotics: We will see the widespread application of vision language models in robotics and enable machines to "see," "hear," and "feel" their environment for precise task execution in complex settings.
- Emotionally Intelligent Systems: Advances in cross-modal learning will lead to cognitive AI assistants that can detect and respond to subtle human emotions, transforming mental health wellness and personalized education.
- Edge and On-Device Multimodality: Models like the Google Nano series are bringing multimodal capabilities to consumer devices for real-time image creation and editing without relying on cloud infrastructure.
- Advanced Fusion Techniques: Research into gated cross-attention and dynamic fusion weights will allow models to be more noise-resistant and efficient, selecting only the most relevant information from various data streams at any given moment.
Conclusions
Multimodal AI brings text, images, audio, and more together to provide a much richer understanding and capabilities than single-modality systems.
It lets machines perceive and reason about the world more like humans do.
But building production-ready, large multimodal models is challenging due to the massive computational power and high-quality, aligned training data required.
Looking ahead, ongoing research and engineering will make multimodal systems more efficient, reliable, and ubiquitous.
Stop struggling with manual, separate data annotation tools. Use Unitlab’s AI-assisted workflows to prepare your datasets 5x faster and scale your model demand.
![Best Multimodal ML Data Annotation Tools in 2026 [Comparative Guide]](https://storage.ghost.io/c/48/f4/48f4b614-5c29-430d-9cb3-e0b3f34395f3/content/images/size/w360/2025/12/Robotics--4-.png)
