Image segmentation is a computer vision technique for dividing an image into groups of pixels according to some criteria. The algorithm takes an image as input and divides it into regions or segments, through contours or segmentation masks (usually segmentation masks).
Segmentation allows computer vision models to understand structure, shapes, and object boundaries. You use segmentation when object outlines matter more than general image classification.
Two major segmentation approaches are semantic segmentation and instance segmentation. Both classify pixels, but only one distinguishes individual objects.
In this guide, we will review both techniques and understand their differences. By the end, you will be able to differentiate them clearly.
Let’s get started.
Instance Segmentation
Before introducing instance segmentation, it helps to start with the most essential image-related techniques.
The most basic image annotation type is image classification. It involves giving the photo a single label, like cat. This indicates that the image contains a cat, and nothing more. No drawings, no coordinates, no detection.
Localization finds our single object (the cat) and draws a tight bounding box around it. This box shows where the object is located in the image. It provides x, y, height, and width coordinates.
Combining classification and localization for multiple cat instances gives us object detection. Each cat instance is separately localized and has its own bounding box. Each is treated as an independent entity.

Instance segmentation is an extension of object detection. It uses pixel-level mask classification instead of (or alongside) bounding boxes. Both detect and localize objects, but instance segmentation does so more precisely with segmentation masks, especially for objects with irregular boundaries.
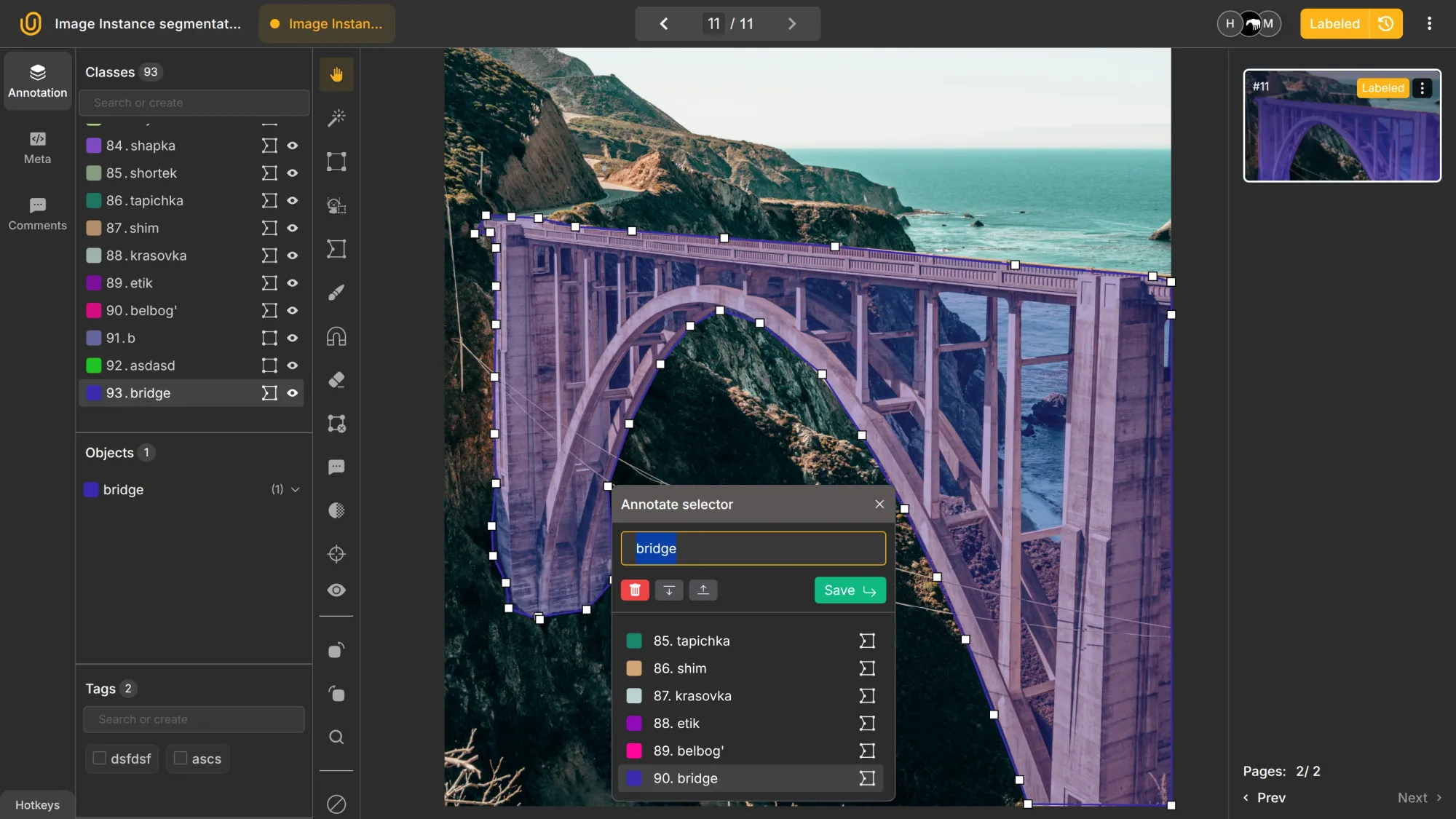
In short, instance segmentation performs pixel-level classification while also identifying each object instance separately. It provides both class labels and unique segmentation masks.
It achieves this using connected polygons rather than simple rectangular bounding boxes. Each object instance is uniquely identified, allowing for precise separation of objects even when they are close together or overlapping.
With instance segmentation, it follows, each object gets its own segmented region. You connect points along the borders of the object, and the area inside forms the segmented mask.
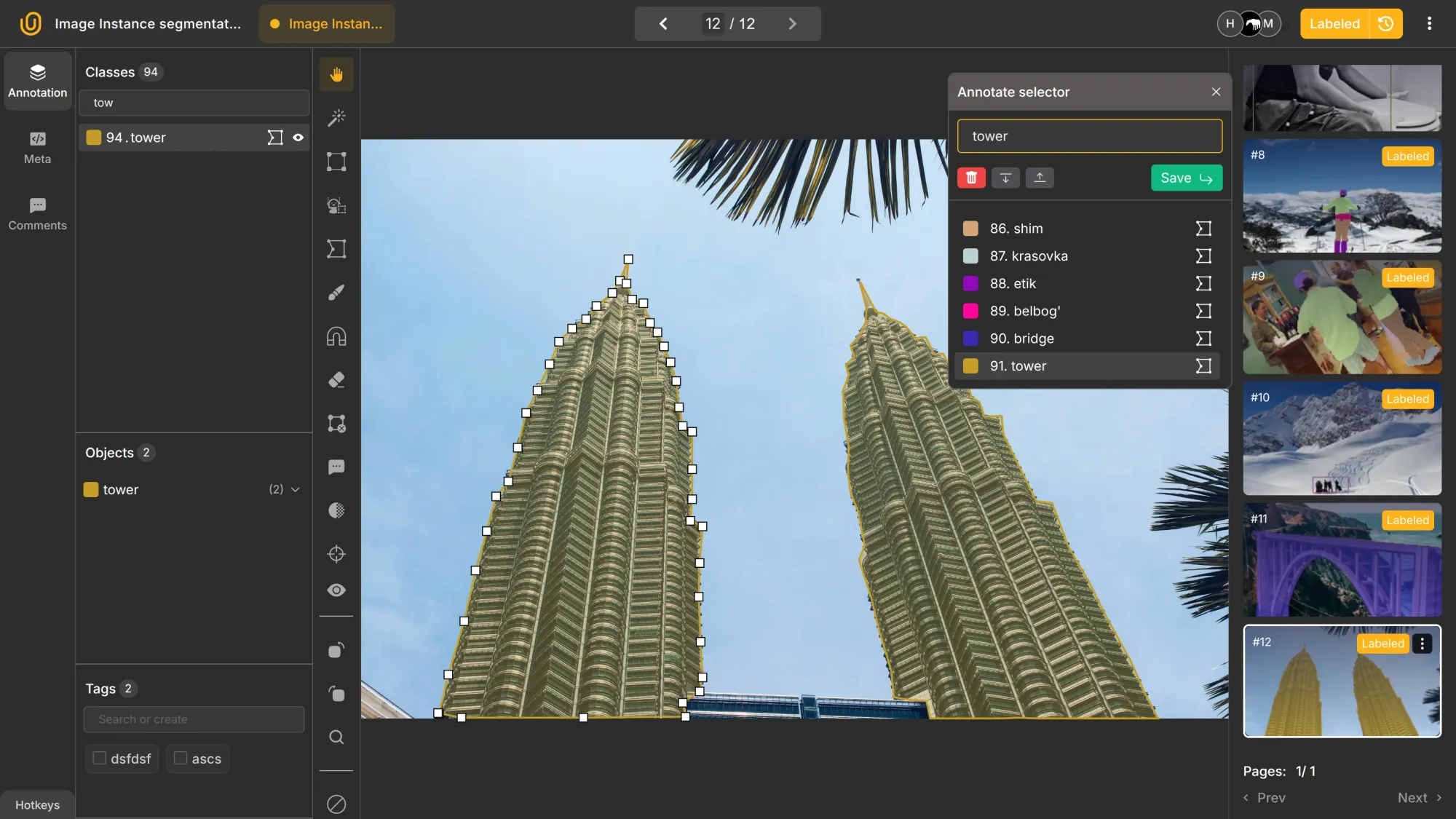
This allows you to differentiate one cat from another even if they overlap. Instance segmentation can also specify the number of objects present in an image, making it possible to count and distinguish each object individually.
A sample coordinate system for the first Petronas Tower in COCO format would look like this:
{
"pk":"90056cde-ce60-4157-801e-07d16fd4a05b",
"class":93,
"points":[[518.3,3825.7],[580.7,3563.4],[686.8,3207.5],
[761.8,2870.4],[836.7,2608.1],[899.1,2377.1],[980.3,2277.2],
[1042.8,2052.4],[1099,1821.4],[1173.9,1671.5],
[1255.1,1496.7],[1317.5,1346.8],[1404.9,1259.4],
[1498.6,1196.9],[1567.3,1109.5],[1673.4,1022.1],
[1723.4,940.9],[1779.6,797.3],[1767.1,959.7],
[1804.5,1065.8],[1879.5,1090.8],[1923.2,1221.9],
[1973.1,1284.4],[2016.8,1378],[2060.5,1484.2],[2098,1609.1],
[2116.7,1783.9],[2141.7,1908.8],[2204.2,1946.2],
[2204.2,2196],[2204.2,2395.8],[2191.7,2539.4],
[2272.8,2576.9],[2254.1,2820.4],[2247.9,3045.2],
[2260.3,3344.9],[2272.8,3582.2],[2254.1,3675.8],
[2141.7,3750.8],[2160.4,3844.4],[1479.8,3850.7],
[668.1,3850.7],[512,3819.5]],
"isVisible":true,
"markup_type":"polygon"
},
It shows the primary key, visibility, markup type, and class. Most importantly, it includes coordinate pairs (X, Y) for the model to precisely locate the object. The segmentation mask here corresponds to the detected object, ensuring that each object is accurately outlined.
These features make instance segmentation more accurate, but also more expensive. It requires longer annotation time, more model training, higher latency, greater memory use, and more complex deployment.
Therefore, instance segmentation should be used where the additional accuracy justifies the higher cost.
Semantic Segmentation
Unlike instance segmentation, semantic segmentation does not distinguish between individual objects, so it cannot separate different instances of the same class. As a result, semantic segmentation cannot tell apart each different object when they overlap, making it impossible to count or delineate each one individually.
Semantic segmentation also assigns labels to image regions. However, the goal here is not to distinguish individual objects, but to assign labels such as car, road, or passenger to each pixel in the image. A semantic segmentation model assigns a class label to every pixel, enabling detailed pixel-level classification for various segmentation tasks.

It shows where specific classes are located. But it does not separate multiple objects of the same class. For example, if you have two towers in an image, semantic segmentation labels both as tower without differentiating them:
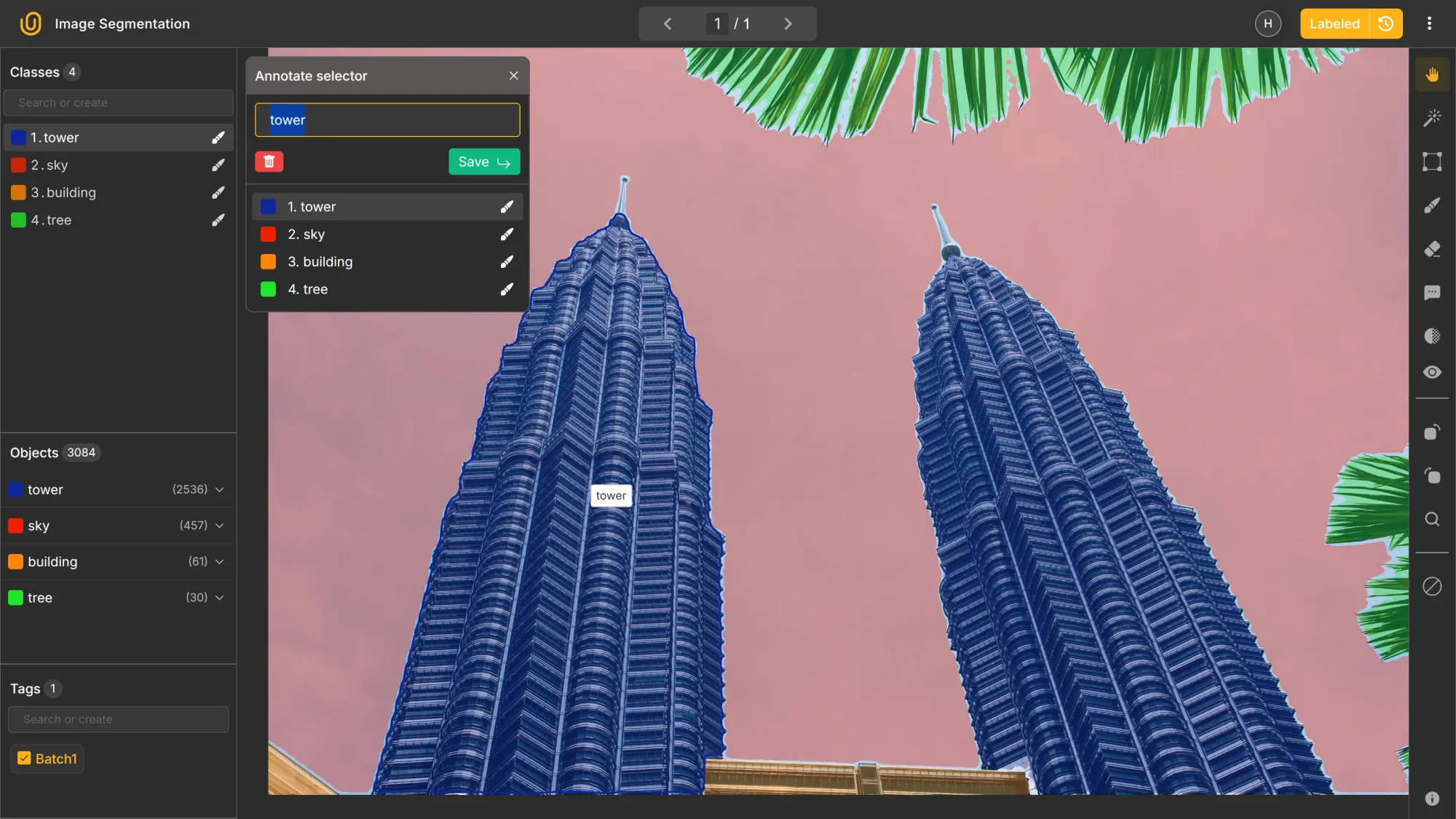
Both towers merge into one mask. They are not treated as separate objects. This is the key difference from instance segmentation.
For the image above, the exact annotation output in the COCO format differs as well:
[
{
"classID":1,
"contours":[
{
"id":"301147b9-3688-44d2-b0d9-15fc8ed86960",
"points":[[5614.964444444445,3843.423888888889]]
},
{
"id":"7b77979f-df13-413a-816c-4ac0edb7f3a1",
"points":[[4394.32,3101.4005555555555],
[4395.926111111111,3099.7944444444443],
[4397.532222222222,3101.4005555555555],
[4395.926111111111,3103.0066666666667]]
},
}
]
...This output is a segmentation map, where each pixel is assigned a class label, representing the segmentation maps generated by segmentation models.
I cut the output short because it would be literally thousands of lines because each point in the image is being assigned to a class.
This is sometimes called pixel-perfect labeling. It provides very high accuracy, but is very costly and time-consuming to produce at scale. Creating a high-quality segmentation dataset for training segmentation models requires significant resources.
As a result, semantic segmentation is often used where precision is critical, such as in medical imaging. Medical image segmentation is widely applied to segment medical images for tasks like tumor detection. It plays a crucial role in image analysis for clinical applications
Panoptic Segmentation
Panoptic segmentation combines the two techniques to create pixel-perfect masks that also separate individual objects:
- Things: countable objects (cars, people, chairs).
- Stuff: non-countable background regions (road, sky, grass).
This approach provides a complete scene structure and is useful when both object-level detail and region-level understanding are required.

Key Differences
So, we have extensively covered both instance and semantic segmentation types. Here's the quick summary table:
| Aspect | Instance Segmentation | Semantic Segmentation |
|---|---|---|
| Output | Class + Object ID per pixel | Class per pixel |
| Object Count | Supported | Not supported |
| Complexity | High | Highest |
| Resources | High | Highest |
| Best For | Irregular shapes that cannot be captured with rectangles | Pixel-level understanding |
| Industry | Satellite, self-driving vehicles, robotics | Healthcare |
Common Segmentation Models
To complete the discussion, here are some of the popular computer vision models for each type: Most modern segmentation models are based on deep learning models, which have significantly advanced the field of image segmentation"
Semantic Segmentation
- U-Net: Uses an encoder-decoder structure with skip connections to preserve spatial detail. U-Net is an example of an encoder decoder architecture, enabling detailed segmentation outputs. It processes feature maps at multiple scales to generate accurate segmentation outputs.
- DeepLabV3+: Uses atrous convolutions and a decoder to refine object boundaries across different scales. DeepLabV3+ builds on fully convolutional networks, leveraging their strengths for pixel-wise classification. The model processes feature maps through its architecture, and the final layer produces the segmentation map.
- SegFormer: Transformer-based model without heavy convolutions. Efficient and scalable across image sizes. SegFormer represents new segmentation techniques by utilizing transformer-based architectures for improved performance.
Instance Segmentation
- Mask R-CNN: Extends Faster R-CNN with a branch that predicts pixel masks for detected objects. Mask R-CNN uses a region proposal network to generate candidate object regions, enabling precise instance segmentation.
- YOLO-based segmentation heads: Generate bounding boxes and masks in a single pass for real-time segmentation. YOLO-based models are object detectors with segmentation capabilities, combining detection and segmentation in a unified framework.
- Segment Anything (SAM): Produces masks from prompts and is useful for annotation acceleration. SAM is notable for its advanced segmentation capabilities, allowing flexible and efficient mask generation.
Panoptic segmentation often extends these base models to joint outputs.
Conclusion
Semantic segmentation provides category-level pixel labeling. Instance segmentation adds object-level separation. The best choice depends on the task:
- If you need region understanding → use semantic segmentation.
- If you need to count or track objects → use instance segmentation.
- If you need both → use panoptic segmentation.
The choice of instance segmentation model depends on the specific application and requirements.
The availability of high-quality segmentation datasets is crucial for training accurate models, as these datasets provide the necessary pixel-level annotations. Sufficient training data is essential to ensure robust model performance and generalization.
That said, be aware that higher accuracy gains come at the cost of expensive data labeling, higher expenses, and longer development.
Explore More
Check out these resources for more on image segmentation:
- Guide to Image Instance Segmentation
- Guide to Pixel-perfect Image Labeling
- Intro to Polygon Brush Annotation
References
- Hojiakbar Barotov (Feb 20, 2025). Guide to Image Instance Segmentation. Unitlab Blog: Source
- Jacob Solawetz (Nov 26, 2024). What is Instance Segmentation? A Guide. [2025] Roboflow Blog: Source
- Keylabs. (Mar 18, 2024). Instance vs Semantic Segmentation: Understanding the Difference. Keylabs: Source
- Media Cybernetics (Aug 28, 2025). Semantic vs. Instance Segmentation in Microscopy: A Complete Guide | AI Essentials. Media Cybernetics: Source
![The Guide to Medical Image Annotation: Essentials, Techniques, Tools [2025]](/content/images/size/w360/2025/12/medical.png)