

Algorithms and machines can’t be biased from an objective point of view; they are inanimate tools designed to run computer bytes in their processors. Still, we regularly see stories of computer bias and biased systems in the news, even those developed and used by government entities and major corporations.
For the record, Amazon's recruiting systems were found to favor men over women in their selection. This is a clear example of gender bias, where artificial intelligence systems can reinforce harmful stereotypes about job roles, leading to discriminatory outcomes.
COMPAS (Correctional Offender Management Profiling for Alternative Sanctions), a risk assessment sentencing algorithm, used by state judges in the US, was biased against black defendants. Bias in machine learning can lead to real harm.

The bias affects how AI systems learn patterns, generate outputs, make decisions, recognize people, and interpret the world. The GIGO principle holds: with biased datasets and workflows present in your AI/ML development pipeline, you cannot expect final unbiased super ML models.
The bias affects how AI systems learn patterns, generate outputs, make decisions, recognize people, and interpret the world. The GIGO principle holds: with biased datasets and workflows present in your AI/ML development pipeline, you cannot expect final unbiased super ML models.
In this post, we are going to cover bias in computer vision models and offer practical advice on how to mitigate it. Let’s get started.
What is Bias?
First of all, what is bias? Specifically, in the context of computer vision and machine learning?
Machine learning bias refers to systematic and unfair disparities in the output of machine learning algorithms. These biases can manifest in various ways and are often a reflection of the data used to train these algorithms.
— Wikipedia
ML bias, in other words, refers to the tendency of the model to behave unfairly toward certain groups or conditions. A notable example has been facial recognition models that perform poorly on darker skin tones.
Many early facial recognition systems were trained on images of light-skinned people, resulting in systematic bias. Then, algorithms were optimized for overall accuracy, not individual subgroup performance, increasing the bias even further.
Other human biases and biased language present in the training data also led to unfair model outcomes, perpetuating discrimination and reducing fairness. The result was the CV model that worked accurately for people with lighter skin but not for those with darker skin:
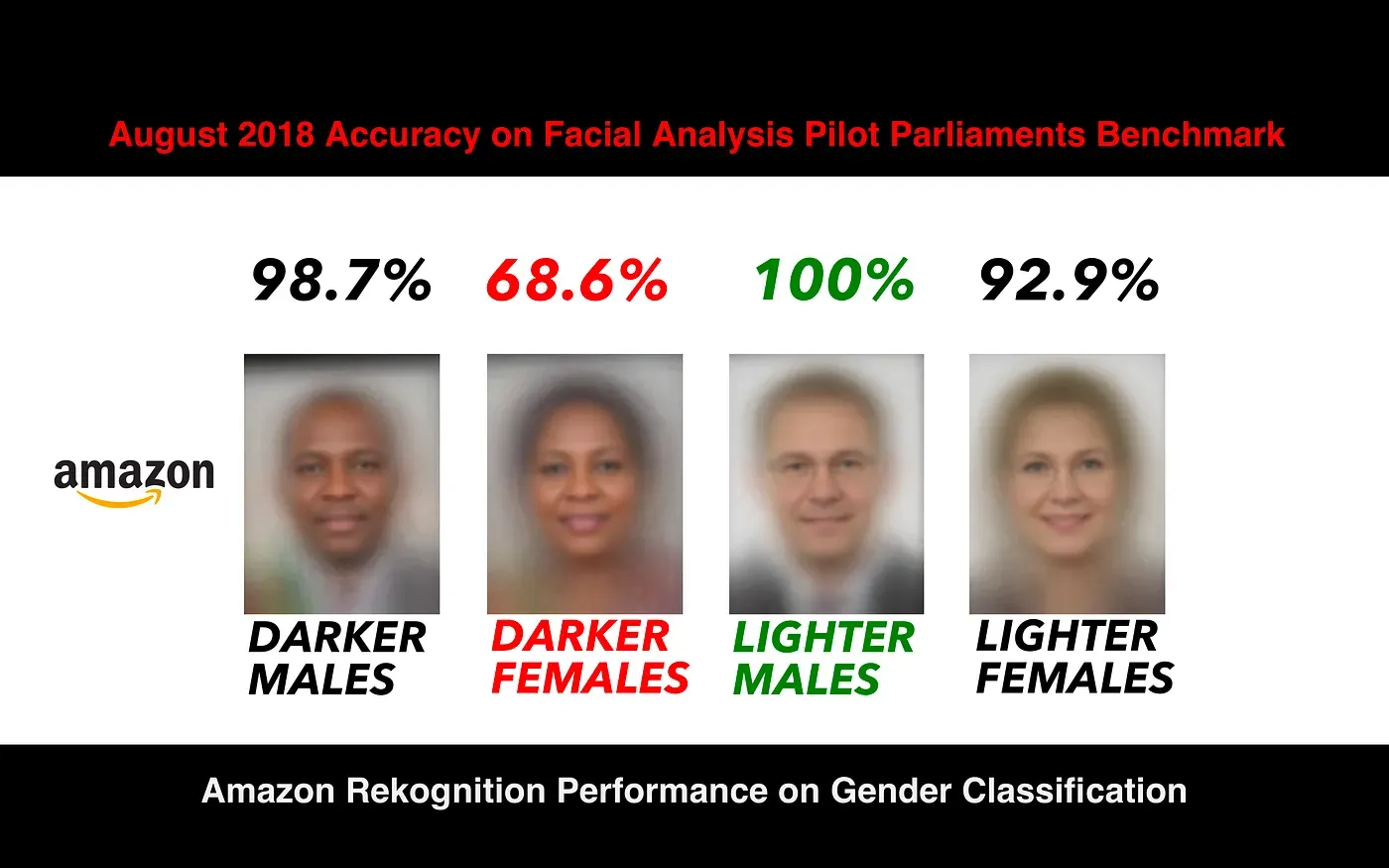
Bias can crop up in any phase of AI model development, but it often stems from its training data (systematic bias) or its training algorithms (algorithmic bias). More often than not, however, these two factors may combine to produce a variety of biases in computer vision models.
Implicit bias and cognitive bias can also be introduced during data labeling and model development, as individuals may unconsciously or subjectively influence the process, further embedding bias into AI systems.
No matter the source, a biased computer vision model will produce skewed outputs. This decreases its accuracy, hinders its effectiveness, and even causes damage to the reputation of the computer vision model developer. If you build or deploy computer vision systems, bias isn’t something to ignore. Needless to say, it is bad for the bottom line.
Now, let's see how we can detect and mitigate bias in our models.
Detecting and Mitigating Bias in Computer Vision
Technically, bias is divided into two categories: cognitive bias and emotional bias. The first class refers to the bias that happens due to the inefficiencies or ignorance of our brains. The other is driven by emotions; we humans are particularly susceptible to it (i.e., loss aversion or overconfidence).
Informational (cognitive) bias can be fixed by, well, information. With better knowledge and tools, we can detect and mitigate this bias. Luckily for us, most bias in computer vision is informational in its nature.
That said, bias doesn’t fix itself. We still have to actively search for and understand it in our development pipelines. Addressing bias throughout the AI development process is essential, and leveraging software tools (such as fairness-aware algorithms and audit frameworks) can support these efforts.
No wonder our quest for avoiding biases in CV starts with understanding their sources.
1. Understand the Sources of Bias
As mentioned, bias can enter your CV model development at multiple points. Or one bias in one workflow might be intensified by another workflow in the pipeline. The most common points include:
- Data collection: This part is most susceptible to biases. Data imbalance in data collection leads to unbalanced datasets and then to unbalanced weights in pattern recognition. For example, if your image dataset for the vehicle recognition system mostly contains photos of only the day scenario, your CV model will lean toward it. Even the choice of image acquisition devices (such as cameras, sensors, or scanners) can be the part of bias in data acquisition.
- Annotation: Human annotators are not usually consistent or objective. They are influenced by many factors outside the job and may bring bias to the dataset.
- Model training: Even if your dataset is fully balanced with high-quality annotations, it can still produce biased outputs if the algorithm favors or discards certain patterns. A notable example is political correctness bias present in many GenAI models:

Ask yourself: Where could your computer vision model learn something unintended or in an unintended way?
2. Build a Balanced Training Dataset
This topic is so wide and complex that entire research articles are written about it. We have also written a guide on developing balanced image sets for computer vision models.
The obvious fact: your dataset is your foundation, from which everything flows. A biased dataset will produce a biased model, no matter how advanced your architecture is.
Several practical steps to build balanced datasets:
- Collect source photos from diverse demographics and scenarios. For the vehicle detection AI, this could include day, night, windy, rainy, and snowy conditions.
- Include edge cases like different lighting, angles, shadows, and environments.
- Ensure each input image is accurately annotated, and use labeled images to provide clear ground truth for training and evaluation.
- Avoid overrepresentation of a single group or scenario.
- Use stratified sampling to balance the dataset. Assign weights to each category (strata) and collect samples accordingly.
Large, balanced data improves the generalization of CV models. It makes them more accurate and robust in real-world scenarios.
3. Standardize Annotation Guidelines
After you collect your raw data, it needs to be annotated consistently and accurately according to guidelines. Data labeling is enormously affected by the data annotator. If you are not careful, human subjectivity will likely hinder the dataset quality.
For example, without proper guidelines, some annotators might label people in wheelchairs as “pedestrians”, while others might annotate them as “wheelchairs” or even “objects”. Some might just ignore them altogether. The result is a confused AI that misclassifies disabled individuals in wheelchairs on the street. Instead, clearly defining specific objects and applying object detection techniques ensures accurate identification and localization in digital images.
We have written a comprehensive tutorial on developing image labeling guidelines, but here are the concise steps:
- Define what each class or label means in detail.
- Train annotators with examples and edge cases.
- Regularly review annotation consistency.
- Use inter-annotator agreement metrics to catch inconsistencies.
4. Choose Unbiased Algorithms
Even with a balanced dataset, your choice of algorithm can shape how bias spreads through the model. Some algorithms amplify majority group patterns more than others.
Focus on these points:
- Avoid algorithms that overfit dominant patterns. For example, a standard classification loss may optimize for overall accuracy, ignoring poor performance on minority subgroups.
- Use fairness-aware training objectives. Techniques like adversarial debiasing or group reweighting reduce the model’s reliance on sensitive features.
- Regularize with fairness constraints. Add constraints that limit disparities between subgroups during training.
- Evaluate subgroup performance during model selection. Don’t pick the model with the highest overall accuracy. Choose the one that performs consistently across groups.
5. Use Bias Detection Techniques
We humans tend to think that we are doing okay even though we aren't, also known as The Dunning-Kruger effect. After taking the steps above, we might conclude that there is no significant bias in our model development. We might as well be cutting the branch we are sitting on:

Don’t assume your dataset is fair. Measure it objectively, not intuitively. Employ available bias detection techniques:
- Analyze the distribution of classes and demographic attributes. Computer vision systems process visual data from digital images to detect bias in these distributions.
- Run subgroup performance tests (e.g., accuracy by demographic group).
- Use fairness metrics like false positive and false negative rates per subgroup.
- Visualize data imbalance through charts. Image processing techniques can help highlight bias by enhancing and analyzing digital images for imbalanced patterns.
If some groups perform significantly better or worse, that’s a giant red flag.
6. Apply Bias Mitigation Strategies
OK, you collected a balanced dataset, annotated it consistently and accurately, chose a balanced algorithm, and ran through bias detection to the best of your ability. You discovered a few systematic errors along the way.
Once you detect bias, you need to act. This is easier said than done, but with your CV model, business and reputation at stake, you should consider implementing these technical strategies:
- Reweighting: Adjust the importance of underrepresented samples.
- Resampling: Oversample minority groups or undersample majority groups.
- Adversarial debiasing: Train the model to minimize sensitive information leakage.
- Post-processing: Calibrate outputs to equalize performance across groups.
Just in case someone didn’t know, no single technique solves every problem. Pick the right combination for your problem.
7. Foster Awareness in Teams
This advice is not technical per se, but bias is not just a technical error. It is a systematic error that enters and remains undetected in our model development workflows.
Fortunately for us, most of the biases in computer vision are related to information processing. With awareness and knowledge of the bias, we can avoid bias in the first place. Therefore, it pays to raise awareness in our teams: among data engineers, annotators, scientists, and project managers.
Human oversight is essential in this process, as it helps detect implicit biases that may be present in training data or model outputs, ensuring fairness and ethical standards.
That's it. These 7 steps should be enough to detect and address cognitive biases in your ML models. They reasonably take time and resources. But it is a necessary sacrifice that you should do lest your model becomes another example of AI hallucinations.
That’s it. These 7 steps should be enough to detect and address cognitive biases in your ML models. They reasonably take time and resources. But it is a necessary sacrifice that you should do lest your model becomes another example of AI hallucinations. These efforts contribute to a better understanding and mitigation of bias in your computer vision model.
Conclusion
Bias is a systematic, often undetected error that happens during our computer vision model development and affects its performance negatively. It can cause AI hallucinations, skewed outputs, and plain weird results.
However, it is possible to detect, avoid, and mitigate AI bias in CV. This consists of timely bias detection, balanced datasets, consistent labeling, unbiased algorithms, bias measurement, bias mitigation, and self-awareness. This is not easy but worth doing during development, not during production.
Understand that avoiding bias in computer vision isn't a one-time fix. It’s a continuous process of designing better datasets, applying the right techniques, and staying aware of intricate implications. The goal isn't just accuracy either. It is practical computer vision models that create value in the real world.
Understand that avoiding bias in computer vision isn’t a one-time fix. It's a continuous process of designing better datasets, applying the right techniques, and staying aware of intricate implications. Bias mitigation can help reduce health disparities by ensuring equitable outcomes.
The goal isn’t just accuracy either. It is practical computer vision models that create value in the real world.
Explore More
Check out these articles to learn more about biases in developing computer vision models:
- Biases in AI/ML Models
- 8 Common Mistakes in Preparing Datasets for Computer Vision Models
- Best Computer Vision Courses
References
- Görkem Polat (Jan 31, 2023). 5 Ways to Reduce Bias in Computer Vision Datasets. Encord Blog: Source
- Hojiakbar Barotov (May 05, 2025). Biases in AI/ML Models. Unitlab Blog: Source
- Roboflow (Mar 13, 2022). Preventing Algorithmic Bias in Computer Vision Models. YouTube: Source
- Sepehr Dehdashtian et. al. (Aug 05, 2024). Fairness and Bias Mitigation in Computer Vision: A Survey. arXiv: Source
- Zac Amos (no date). How to Fight AI Bias in Computer Vision. Swiss Cognitive: Source

![The Guide to Medical Image Annotation: Essentials, Techniques, Tools [2025]](/content/images/size/w360/2025/12/medical.png)