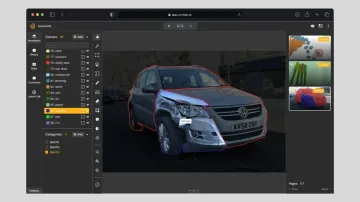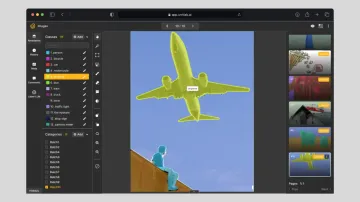
Computer vision is evolving quickly, and industries such as healthcare, insurance, and logistics are starting to use it to improve everyday workflows. But a major obstacle remains: most industries lack tailored datasets and computer vision models. Many open-source datasets exist, but they’re often too broad to meet the specific needs of real-world applications.
Computer vision is evolving quickly, and industries such as healthcare, insurance, and logistics are starting to use it to improve everyday workflows. But a major obstacle remains: most industries lack tailored datasets and computer vision models. Many open-source datasets exist, but they’re often too broad to meet the specific needs of real-world applications.
This gap creates a significant challenge: developing high-quality, custom AI/ML datasets and models from scratch. Fortunately, recent advances in computer vision have brought foundational models—pre-trained models that can handle a wide range of tasks without retraining.
These foundational models leverage machine learning and digital image processing techniques to analyze digital images for various applications, such as object detection and boundary delineation. These out-of-the-box solutions dramatically simplify the process of building, deploying, and scaling AI and CV systems.
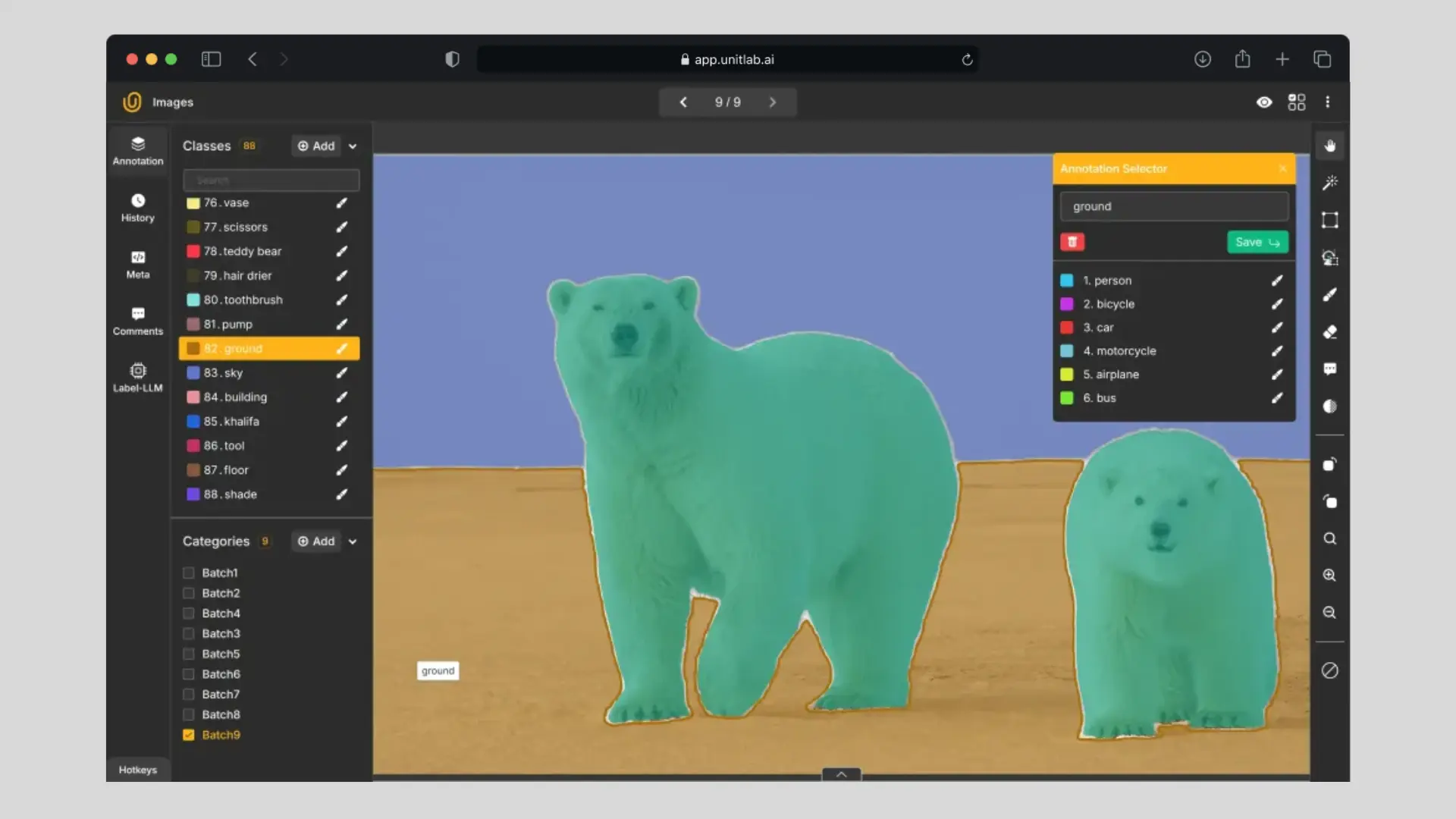
One of the most important examples is Meta AI’s Segment Anything Model (SAM), an open-source model built for both research and practical use. SAM is usually for image segmentation, a core task in artificial intelligence and digital image processing, enabling the partitioning of digital images into meaningful regions for further analysis.
In this guide we will explain:
- what SAM is
- why it matters
- how to segment images within Unitlab Annotate
What is SAM?
SAM, short for Segment Anything Model, is a foundational image segmentation model that can identify specific objects—or all objects—within an image. Unlike traditional models that need retraining or fine-tuning for new tasks, the model is promptable: it can generate accurate masks from minimal input such as clicks, bounding boxes, or reference masks.
In the video below, we generate accurate masks by drawing bounding boxes around the objects of interest, humans.
SAM-powered Segmentation | Unitlab Annotate
Developed by Meta AI, this segmentation model was trained on the SA-1B dataset, which contains 11 million images and 1.1 billion masks—about 100 masks per image. The SA-1B dataset is the largest segmentation dataset to date, providing diverse image distributions for robust training data. This large-scale training allows this model to generalize to new, unseen data and scenarios without extra training or domain-specific tuning.
This feature makes this computer vision model a zero-shot transfer model, meaning it can handle new tasks without prior exposure. SAM demonstrates exceptional zero shot performance and adaptability to new image distributions, making it highly effective across various segmentation tasks. This actually comes very handy when you do not have the time or resources to develop an industry-specific model every time.
Architecturally, SAM consists of an image encoder based on the Vision Transformer (ViT), paired with a lightweight decoder. SAM leverages deep learning and neural network architectures to process the input image and perform mask prediction. This makes it faster than most traditional segmentation models and often better than other machines and humans in labeling speed and quality.
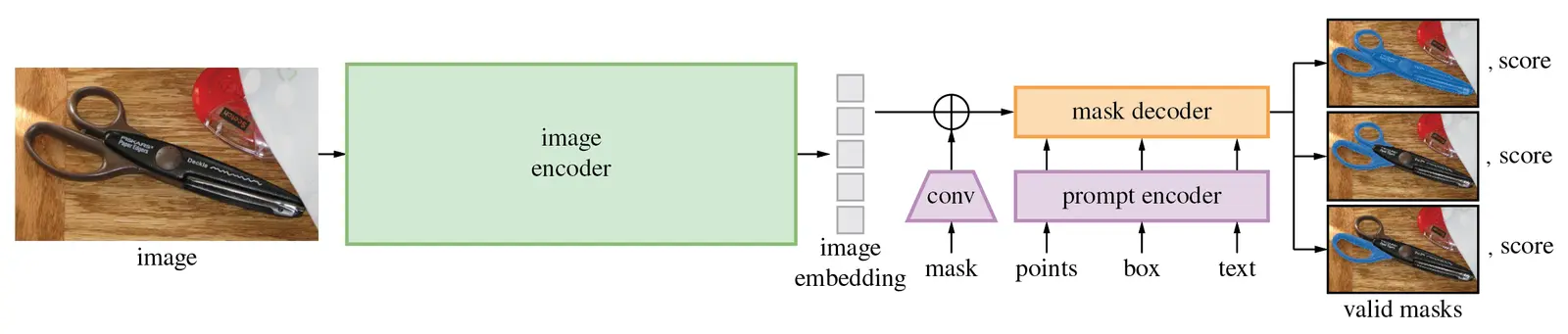
In short, the Segment Anything Model represents a new paradigm in photo segmentation: interactive, flexible, and ready to use in practical, real-world scenarios.
Why SAM?
In any AI/ML workflow, dataset preparation (particularly data annotation) is the most resource-intensive phase. The data labeling part usually exceeds 25% of the total budget for the project.
Among all annotation tasks, pixel-perfect segmentation is the most time-consuming and complex. This involves marking and classifying every pixel in the photo, which takes considerable time and resources as you can imagine.
Traditional segmentation techniques and image segmentation techniques, including thresholding, clustering, and neural networks, often struggle with complex segmentation problems, especially in domains like medical imaging and autonomous driving. SAM changes that.
While this foundation model can be used for tasks such as synthetic data generation and real-time AR/VR, its most direct and impactful application is image segmentation for AI/ML datasets.
Here’s why Meta AI's model and its training dataset, SA-1B are used everywhere and now considered the gold standard:
SAM is fast
As mentioned above, its efficiency stems from both its lightweight design and zero-shot capability. Once prompted, SAM can generate accurate masks within seconds, requiring little adjustment from human annotators. This rapid performance is achieved by efficiently running inference on the model.
For example, a medical image that might take five minutes to segment manually can now be done in about 30 seconds with SAM, as shown in the video:
Medical Imaging Segmentation | Unitlab Annotate
This means decreasing the annotation time by 10-20 times on average. Instead of manually drawing pixels, a human labeler just clicks the area; SAM does the heavy lifting.
SAM is accurate
SA-1B contains 1.1 billion masks across 11 million images, making it six times larger than the next biggest open-source dataset, OpenImages v5. This scale helps the model generalize well across most domains.
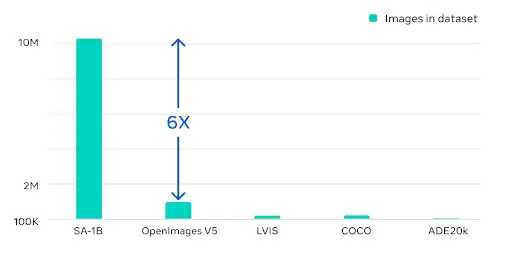
But here it gets really interesting: it’s not just the number of images and masks in the dataset; it’s the diversity and scale of the dataset. The SA-1B dataset includes a diverse set of images featuring different objects and even satellite images, ensuring comprehensive coverage across a wide range of domains, objects, people, scenarios, and environments.
Additionally, researchers focused on the diversity of cultural, national, and even continental contexts to address unconscious bias towards minority or less represented groups. The carefully curated SA-1B dataset resulted in the model that works well for global use across domains, not just for high-income Western countries across a few selected industries.
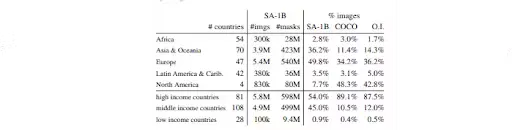
Imagine you have an open-source fast, accurate, and inclusive computer vision model for image segmentation. No wonder SAM is popular and used everywhere.
SAM is flexible
As noted above, this foundational CV model supports different types of prompts for segmentation: point clicks, bounding boxes, freeform masks, and even text inputs when linked with generative AI tools like ChatGPT. This capability makes the model easy to integrate with different tools, workflows, and user preferences in the development pipeline.
SAM is scalable
SAM’s zero-shot accuracy, flexible input system, and consistency make it highly scalable. Whether you have 100 images or 100,000, it lets you segment images faster, with higher quality and fewer errors. SAM can process the entire image or the whole image at once, producing accurate segments for each object or region.
Regarding scalability, on supported data platforms, you can even perform segmentation in batches. For instance, Unitlab Annotate offers Batch Auto-Annotation, which lets you label many images simultaneously with SAM:
Person Segmentation Batch Auto-Annotation | Unitlab Annotate
No configuration needed. You just click—and it labels the batch for you.
It is not hard to see why almost all data annotation platforms provide some form of support for SAM-based photo segmentation.
Now, let's segment images ourselves to see how it really works in practice. We'll use Unitlab Annotate, a fully automated data annotation platform.
Demo Project
To see SAM in action, we will create a demo project on Unitlab Annotate. First, create a free account.
To segment our photos, we will use the tool called Magic Touch, powered by SAM. It is free forever, and supports both Image Segmentation and Instance Segmentation. When you upload your images, each file acts as a source image for the segmentation process.
Step 1: Project Setup
After logging in, click Add a Project, set the data type to Image, and choose Image Segmentation as the labeling type:
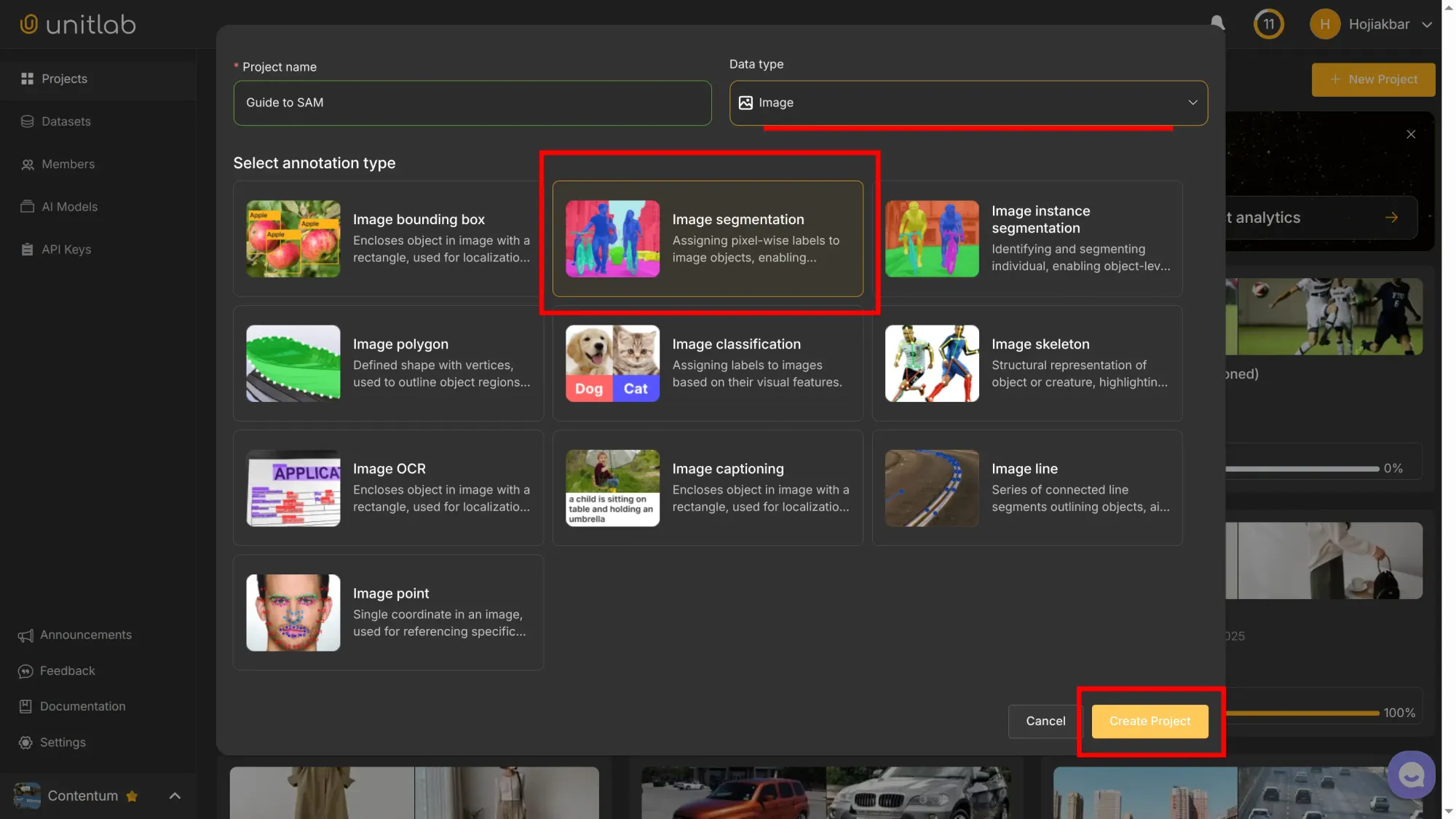
Upload the downloaded sample images as a folder. You can download sample fashion images here.
Then assign the annotation task to an annotator (yourself):
Next, enable Automation Workflow by going to Automation > Create Automation:
For this example, choose Fashion Segmentation. You may also add other foundational models (e.g., Person Detection, OCR) if needed in other projects. The default settings for this foundational model are sufficient for this demo:
Name your workflow, start the run, and note that you can create multiple workflows within a project:
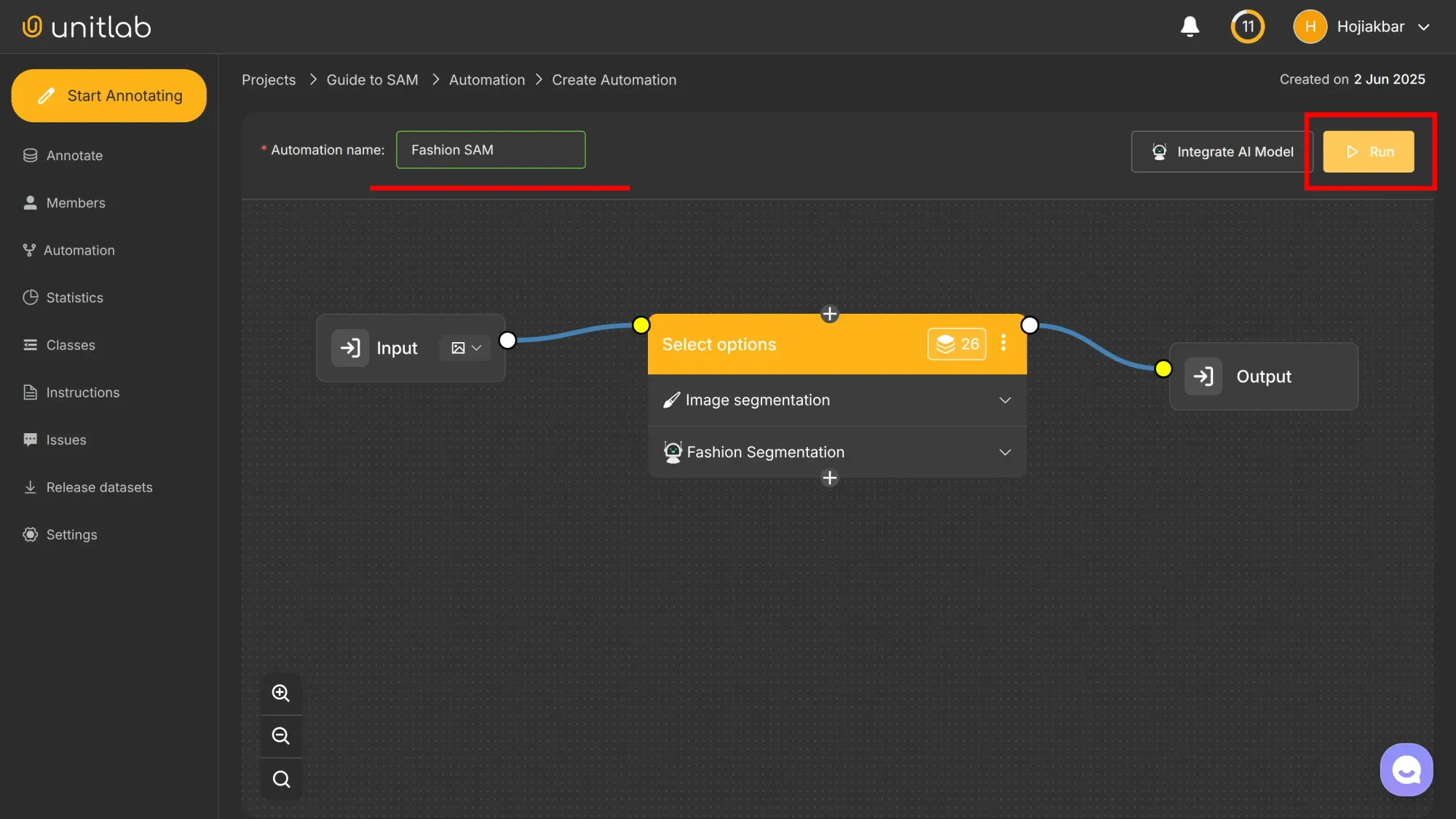
Step 2: SAM-powered Photo Labeling
Magic Touch lets you annotate by simply clicking an object. One click is enough for SAM to return an accurate segmentation mask, for which you specify the class. Each segmentation mask is associated with a class label, and the model can generate segmentation masks for each object.
SAM-powered Segmentation | Unitlab Annotate
Alternatively, draw a box around the area of interest—SAM will segment everything inside it and assign the right classes. Whatever works best in your case.
SAM-powered Segmentation | Unitlab Annotate
To speed up work, you can annotate large volumes of data with Batch Auto-Annotation. This often boosts labeling speed by 10x. After that, you can review and fine-tune the annotation resluts if needed:
SAM-powered Segmentation | Unitlab Annotate
Step 3: Dataset Release
We had 22 images in our upload folder. Once all the photos are annotated, go to Release Datasets > Release Dataset to create the initial version of your dataset.
Choose the dataset format you need. In real-world projects, your dataset will likely grow over time, with new images and annotation classes added constantly. That’s why we have datasets in the first place.
Expanding your dataset with additional training data, such as images containing other pathologies or multiple objects of the same class, helps improve model performance and generalization.
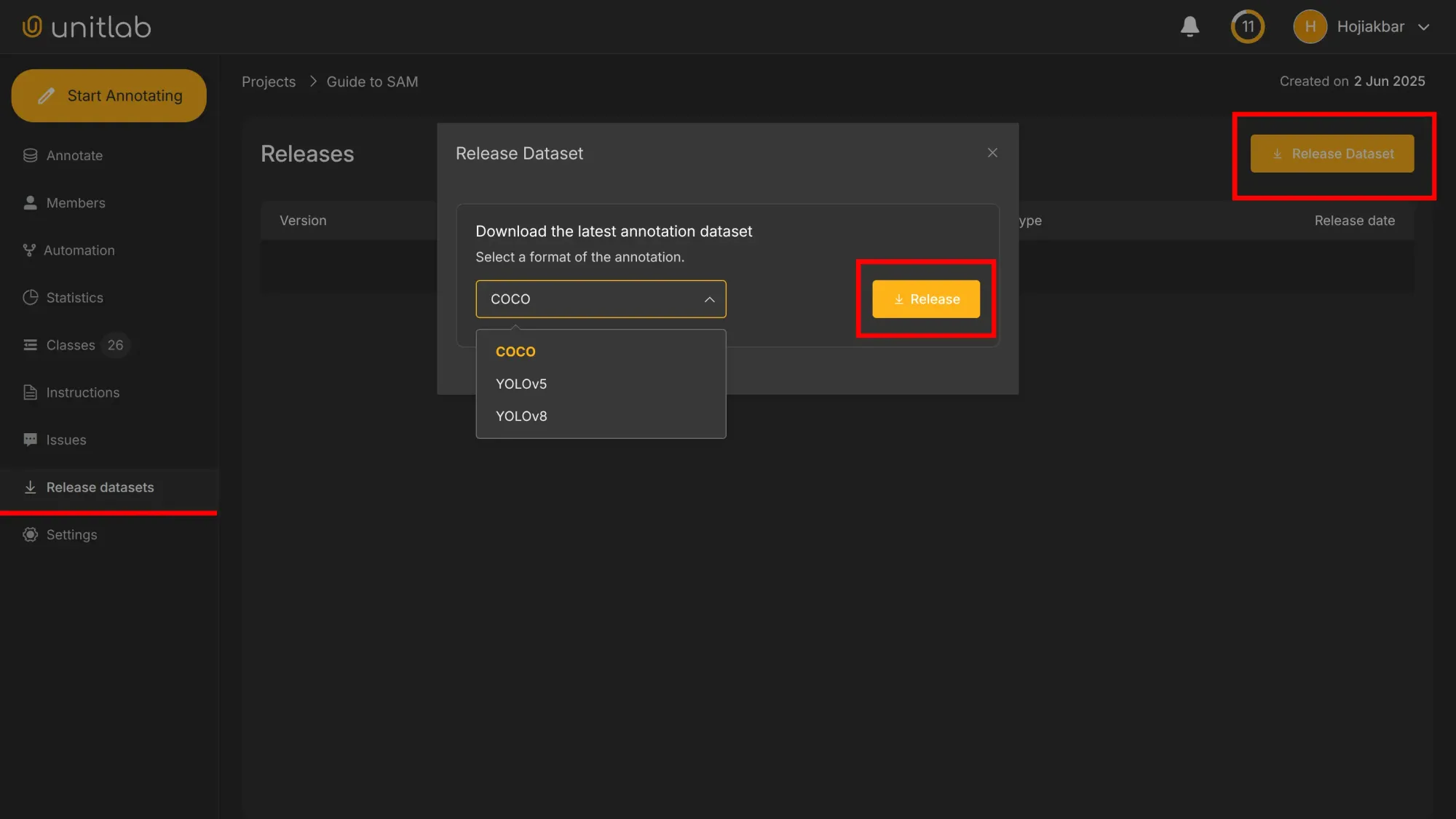
Note: under the free plan, all datasets are public by default and accessible by anyone. Private datasets require an active or pro account. You can view the released dataset here:
Conclusion
The Segment Anything Model, trained on one of the largest and most diverse datasets in computer vision, has changed the way image segmentation is done. Its speed, prompt-based interaction, and accuracy make it a key model for the future of AI-assisted labeling.
In this guide, we introduced SAM, explained how it works, and showed why it’s a breakthrough for annotation tasks. With the hands-on demo in Unitlab Annotate, you’re ready to start using SAM to accelerate your own image labeling pipeline.
Frequently Asked Questions (FAQ)
- Is SAM free in Unitlab Annotate? Yes. SAM, branded as Magic Touch in Unitlab Annotate, is completely free for all users—forever. You just need an account to get started.
- Can I use SAM for Polygons? Yes. Magic Touch currently supports SAM-powered auto-annotation for both Image Polygons and Image Segmentation tasks.
Explore More
Interested in more resources for automating your annotation workflow?
- 3-step Hybrid Way for Superior Image Labeling
- AI Model Management in Unitlab Annotate
- 5 Tips for Auto Labeling
References
- Meta Segment Anything Model (no date). Meta AI: Link
- Nikolaj Buhl (Dec 10, 2024). Meta AI's Segment Anything Model (SAM) Explained: The Ultimate Guide. Encord Blog: Link
- Shohrukh Bekmirzaev (Jan 4, 2024). Data Annotation with Segment Anything Model (SAM). Unitlab Blog: Link