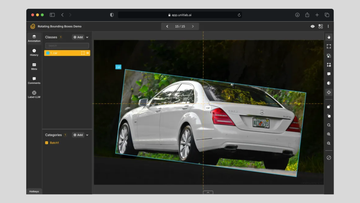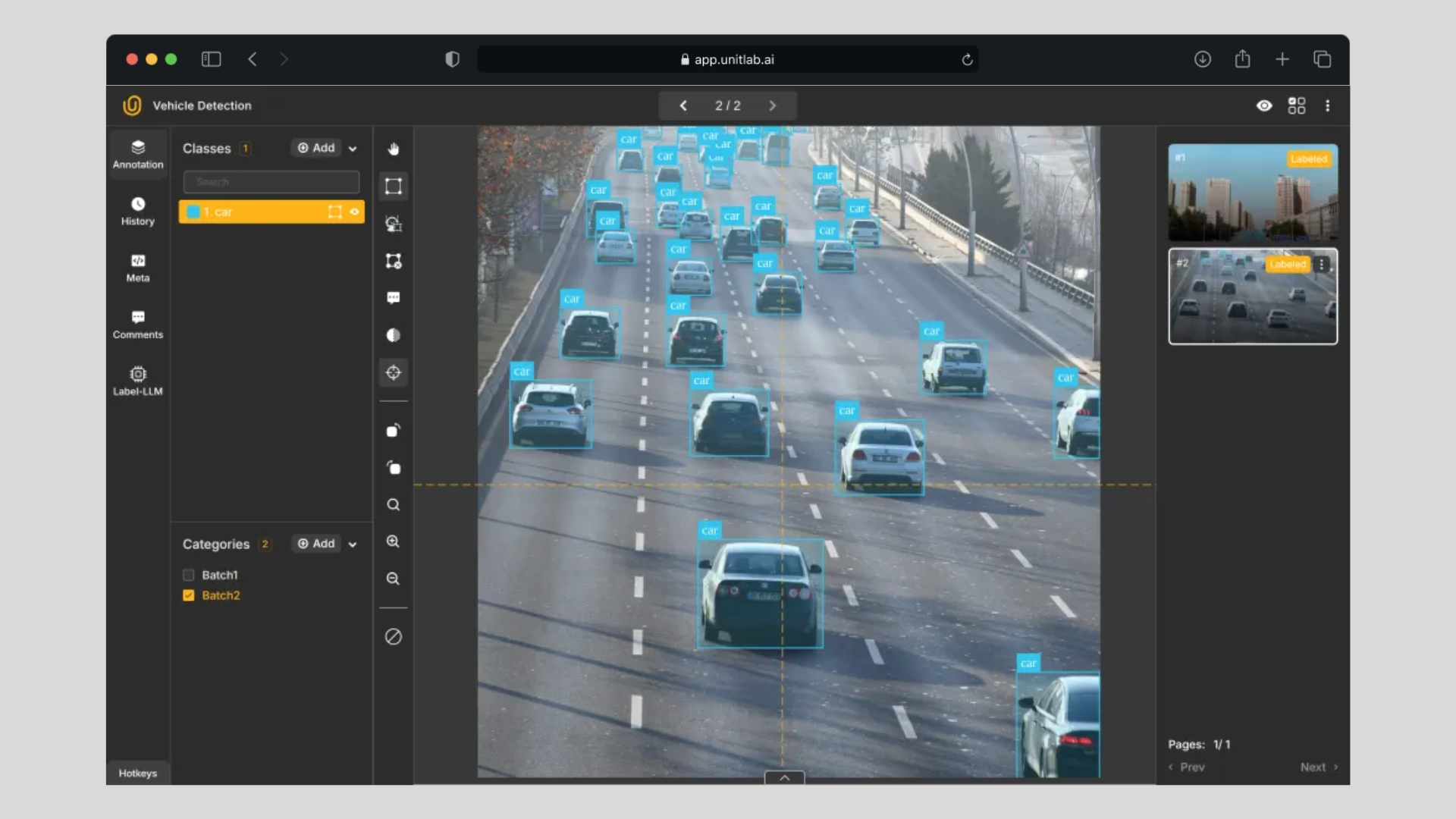
What do ideal datasets look like? How to prepare high-quality datasets for training AI/ML models?
A dataset is the raw material of any AI/ML model. It’s what the model sees, learns from, and eventually uses to make decisions. And that means your model is only as good as the data you feed into it. This is the idea behind the phrase "garbage in, garbage out". No matter how fancy your algorithm is, it can’t outperform the quality of the dataset it was trained on.
Common Mistakes in Preparing Datasets
In a previous post, we talked about eight common mistakes people make when preparing datasets—things that quietly but seriously reduce the effectiveness of their models. That post focused on the data collection and data annotation phases. In this one, we’re zooming out a bit to explore what makes a dataset “ideal” in the first place.

Let’s break it down into five key factors, using object detection in computer vision as our main example.
Factors
Quality #1

First and foremost: quality. This word gets thrown around a lot, but what does it actually mean in the context of AI datasets?
Quality means that every image, video frame, or data point is useful and appropriate for the task at hand. If we’re building an object detection model for self-driving cars, that means we need clear, relevant images of streets, vehicles, pedestrians, and road signs—not blurry shots, low-resolution frames, or irrelevant scenery.
In short, the data should be clean, consistent, and truly reflective of the task the model is learning.
Diversity #2
Here’s a common trap: collecting lots of data but only from one type of environment. That might work for basic demos, but it falls apart fast in the real world.
Let’s stick with the self-driving car example. Imagine your model was trained only on sunny, daytime city streets. How will it perform in heavy rain at night? Or on a snowy suburban road?
A diverse dataset includes examples from all the different conditions your model might face: day and night, sunny and rainy, downtown and rural, common and rare. Diversity also means making sure the dataset represents all the object classes you care about, including edge cases.
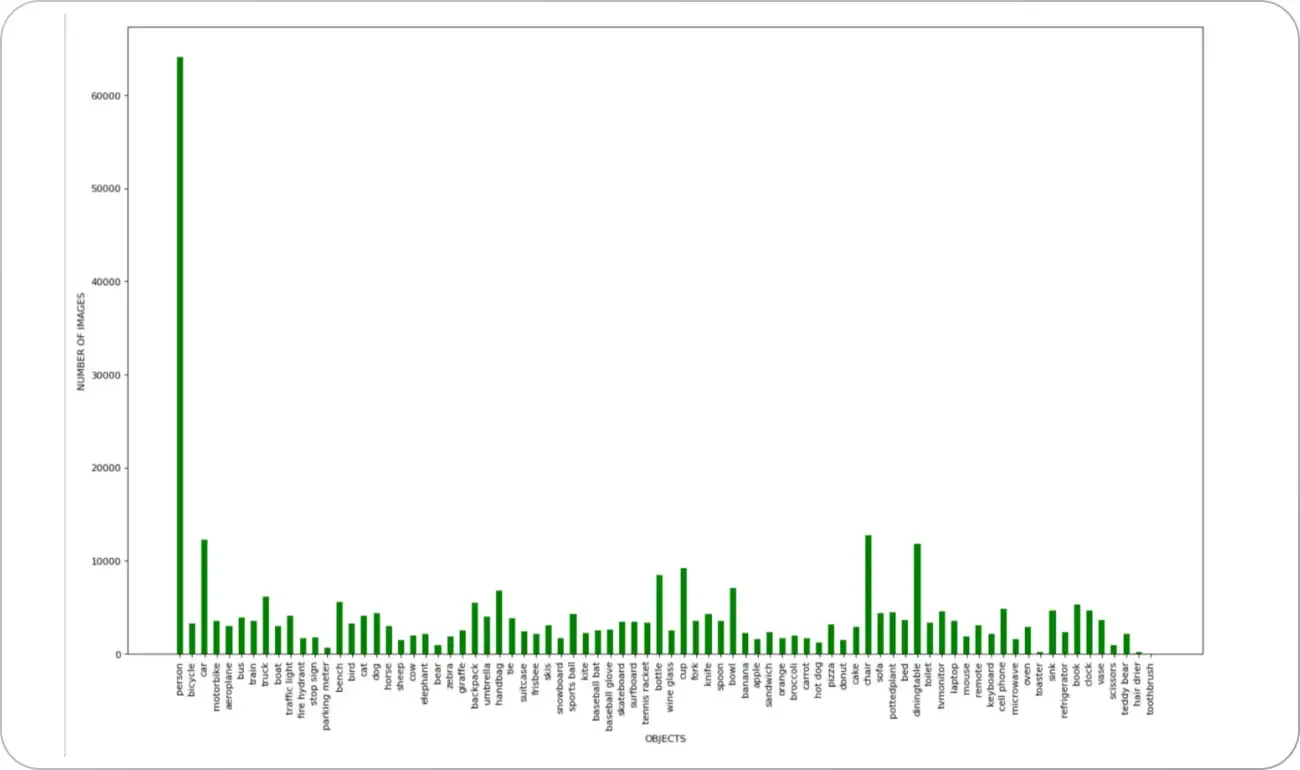
A related challenge is class imbalance: maybe 95% of your dataset contains cars, and only 5% contains cyclists or emergency vehicles. If your model rarely sees these rare cases, it won’t learn to recognize them well—and that could be dangerous in a real-world setting. This is especially important in sensitive fields like healthcare or finance, where an AI/ML model must capture edge scenarios reliably.
Detailedness #3
Not all labels are created equal. The more specific and detailed your labels are, the more your model can learn.
Let’s say you're using an image labeling tool to tag road objects. If you label everything as “vehicle,” your model won’t learn the difference between a bus and a bicycle. But if you provide detailed labels—“sedan,” “pickup truck,” “motorbike,” “van,” and so on—then your model starts to understand nuances and learns to make more precise predictions.
Detailedness also applies to metadata. Information like the weather, time of day, or location (if relevant) can add context that helps models perform better. This is why many modern data annotation solutions include advanced labeling interfaces and support for rich metadata.
Accuracy #4
Accurate labeling is the cornerstone of a good dataset. Every mislabeled object is a step in the wrong direction. If your bounding boxes are off or your categories are mislabeled, your model will learn incorrect associations and behave unpredictably.
Think of it this way: if a stop sign is labeled as a yield sign—even just once—it’s training your model to make mistakes on the road. That’s why accuracy is non-negotiable.
Image annotation is often the most time-consuming part of dataset creation. It’s also the most important. Whether you’re doing manual labeling or using auto labeling tools, everything starts with precision. A lot of what people refer to as a “high-quality dataset” simply comes down to the accuracy of its labels.
Quantity #5
Let’s be honest—building a large dataset is hard. But it’s also necessary. You can’t teach a model to understand the world using just a few examples. That said, more is not always better. Too much data can make training slower, harder to manage, or even lead to overfitting. The trick is to have enough data to generalize well, without drowning in it.
As T.S. Elliot put it eloquently,
Where is the knowledge we have lost in information?
A good rule of thumb is the 10x rule: you should aim for a dataset that’s roughly 10 times larger than the number of parameters in your model.
In domains like medicine or robotics, where collecting labeled data is difficult, you might use data auto labeling or augmentation (rotating, flipping, cropping) to scale your training set efficiently. Tools that support auto labeling workflows can significantly reduce manual effort without sacrificing quality.
At the same time, effective dataset management—including version control—becomes essential as you scale. Without it, it’s easy to lose track of what changed, why your model started to degrade, or which version of the dataset led to which result.
Conclusion
Ideal datasets have five essential traits:
- They’re high in quality
- Rich in diversity
- Detailed in their labels
- Spot-on in accuracy
- And large enough in quantity to support robust learning
When you get these five right, you’re not just building a dataset—you’re building a solid foundation for any AI/ML model that follows. Because in the end, the effort you put into your dataset shows up in every prediction your ML model makes.
Explore More
If you're interested in learning more about preparing and managing AI/ML datasets, check out these related reads:
- 8 Common Mistakes in Preparing Datasets for Computer Vision Models
- 7 Tips for Accurate Image Labeling
- Dataset Management at Unitlab
References
- Bohan Du. (Oct 18, 2023). Introduction to Dataset Creation - What Makes a Good Dataset? Hugging Face: Source
- Michael Abramov. (May 12, 2021). Creating the ideal dataset: everything you need to know. Keymakr Blog: Source