

Explore the evolution of YOLO from simple object detection to a unified multi-task vision framework, and see how modern YOLO models reshape data and annotation requirements.
Introduction
Data is the foundation of all AI systems, and computer vision is no exception. Building strong real-time vision models depends not only on model architecture, but also on having high-quality, well-structured, and sufficiently large training data. In the early days of computer vision, object detection models were trained on relatively simple datasets that only required bounding box labels, which made the training process easier to manage.
As YOLO became more popular and advanced, its capabilities grew far beyond basic object detection. Modern YOLO models now support tasks such as segmentation, pose estimation, and video tracking within a single framework. While this increases flexibility and performance, it also creates new challenges for data preparation and annotation, requiring more diverse data, multiple label types, and consistency across tasks.
What You’ll Learn in This Guide
- What YOLO is and how it evolved from simple object detection into a multi-task computer vision framework
- Key differences across YOLO versions, from YOLOv1 to YOLOv11, including architecture highlights and official repositories
- How YOLO’s evolution increased dataset complexity and changed data preparation and annotation requirements
- Practical considerations and future directions for building scalable, multi-task YOLO-based computer vision systems
Let’s begin our journey through the evolution of YOLO.
What Is YOLO and How It Evolved
To understand YOLO, it is first necessary to understand object detection, a core task in computer vision. Object detection identifies which objects appear in an image and where they are located by predicting bounding boxes and class labels. Unlike image classification, which assigns a single label to an entire image, object detection handles multiple objects within the same scene.
Because an image can contain many objects at different positions and scales, object detection is more complex than standard image classification, requiring both localization and classification simultaneously.
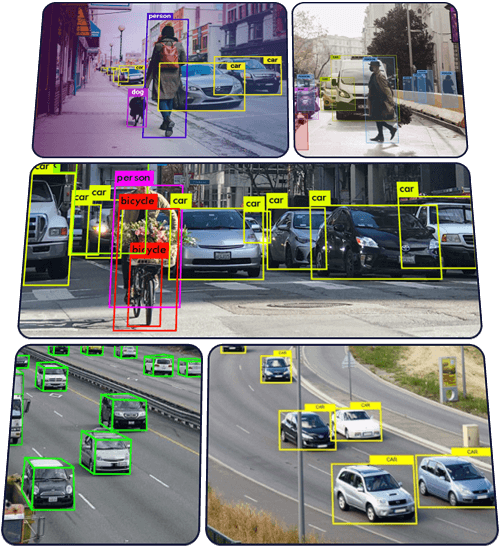
To address this complexity, YOLO was introduced as a unified approach to real-time object detection.
YOLO (You Only Look Once) is a widely used object detection model recognized for its ability to achieve fast, real-time performance while maintaining strong detection accuracy. The YOLO framework was first introduced in 2016 by Joseph Redmon and his collaborators to simplify object detection by treating it as a single, end-to-end learning problem rather than a multi-stage pipeline.
Since its introduction, YOLO has evolved through multiple versions from YOLOv1 to YOLOv11, with each release improving accuracy, efficiency, and training techniques while maintaining real-time, single-stage detection. Over time, YOLO expanded beyond basic object detection to support tasks such as instance segmentation, pose estimation, and video tracking within a unified framework.
This evolution moved YOLO beyond a real-time object detector into a flexible, multi-task computer vision framework. While this greatly expands its range of applications, it also brings new challenges related to data diversity, annotation complexity, and scalable training workflows. In the next section, we explore the key differences across YOLO versions from YOLOv1 to YOLOv11 with a focus on architectural changes and official implementations.
YOLO Versions: YOLOv1 to YOLOv11
This section walks through the major YOLO versions from YOLOv1 to YOLOv11, highlighting how each release introduced architectural changes, new training strategies, and performance improvements.
YOLOv1 (2016): The Beginning of Real-Time Object Detection
YOLOv1 was the first model to treat object detection as a single, unified prediction problem. Before YOLO, most object detection systems used multi-stage pipelines that first generated region proposals and then classified each region separately. While effective, these approaches were slow and computationally expensive, making real-time detection difficult.
Key Technical Ideas
YOLOv1 introduced a fundamentally different idea: instead of breaking detection into multiple steps, the model looks at the entire image only once and directly predicts object locations and classes in a single forward pass. This design greatly reduced inference time and made real-time object detection practical on standard hardware.
Architecture
YOLOv1 divides the input image into an S × S grid. Each grid cell is responsible for detecting objects whose center falls inside that cell. For every grid cell, the model predicts:
- A fixed number of bounding boxes
- A confidence score indicating whether an object is present
- Class probabilities for each object category
By predicting bounding boxes and class labels together, YOLOv1 performs localization and classification simultaneously, rather than as separate steps.
YOLOv2 (2017): Better, Faster, Stronger
YOLOv2 was introduced to address the main limitations of YOLOv1, particularly its weaker localization accuracy and difficulty detecting small objects. While YOLOv1 demonstrated that real-time object detection was possible using a single-stage model, its grid-based formulation restricted flexibility and precision.
YOLOv2 improved upon this by refining both the model architecture and training strategy. Instead of relying on a fixed grid to predict bounding boxes directly, YOLOv2 introduced anchor boxes and several optimization techniques that significantly improved detection accuracy while maintaining real-time performance. The goal of YOLOv2 was not only to be fast, but also to be more accurate and scalable for real-world applications.
Key Technical Ideas
Moreover, YOLOv2 introduced several important improvements that significantly enhanced detection accuracy while preserving real-time performance. It replaced direct bounding box regression with anchor boxes, allowing the model to predict offsets relative to predefined box shapes and improving localization for objects of different sizes. Batch normalization was applied across all convolutional layers, which stabilized training, accelerated convergence, and reduced overfitting. YOLOv2 also adopted multi-scale training, randomly changing input image sizes during training so the model could better generalize across different resolutions at inference time. In addition, higher-resolution feature maps improved the detection of small objects compared to YOLOv1. Finally, the introduction of hierarchical classification (YOLO9000) enabled YOLOv2 to scale to thousands of object categories by jointly learning from detection and classification datasets.
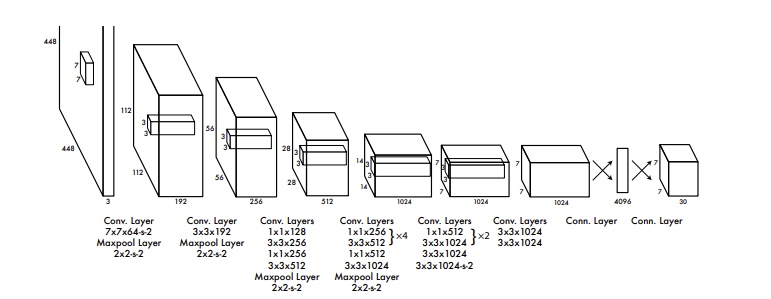
Architecture
YOLOv2 uses Darknet-19 as its backbone network, which consists of 19 convolutional layers and 5 max-pooling layers. The architecture is fully convolutional, removing the fully connected layers used in YOLOv1. This design improves spatial generalization and allows the network to process images of different sizes.
The detection head predicts bounding boxes using anchor boxes at each spatial location of the feature map. For each anchor, the model outputs:
- Bounding box coordinates (relative offsets)
- An objectness score
- Class probabilities
YOLOv3 (2018): Multi-Scale Detection
YOLOv3 was proposed to further improve detection accuracy, especially for small objects, while maintaining the real-time performance that defines the YOLO family. Rather than proposing a completely new detection paradigm, YOLOv3 focused on incremental but impactful architectural changes that addressed the main weaknesses of YOLOv2, such as limited performance on small and densely packed objects.
Unlike earlier versions that relied heavily on anchor-based prediction at a single scale, YOLOv3 expanded detection across multiple feature scales and improved feature representation throughout the network. These changes allowed YOLOv3 to better handle objects of varying sizes without sacrificing speed.
Key Technical Ideas
YOLOv3 introduced multi-scale detection, performing predictions at three different feature map resolutions so that large, medium, and small objects could be detected more effectively. It replaced softmax-based classification with independent logistic classifiers, allowing the model to handle multi-label classification scenarios more flexibly. To support deeper feature extraction, YOLOv3 adopted a new backbone network with residual connections, improving gradient flow and training stability. Together, these changes significantly improved detection accuracy—particularly for small objects—while preserving the core single-stage detection philosophy.
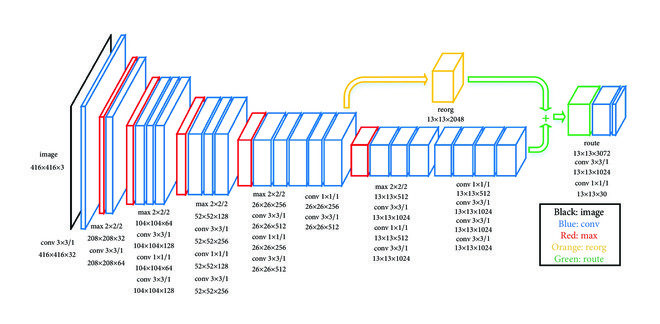
Architecture
YOLOv3 uses Darknet-53 as its backbone network, which consists of 53 convolutional layers with residual connections inspired by ResNet. Detection is performed at three different scales, each connected to feature maps of different spatial resolutions using upsampling and feature fusion techniques similar to a feature pyramid network (FPN). At each detection scale, the model predicts:
- Bounding box offsets relative to anchor boxes
- Objectness scores
- Independent class probabilities
YOLOv4 (2020): Optimal Speed and Accuracy
YOLOv4 was designed to achieve an optimal balance between detection accuracy and real-time performance by carefully combining effective architectural components with advanced training techniques. Rather than proposing an entirely new detection paradigm, YOLOv4 focused on identifying and integrating best practices from prior research to improve performance on standard hardware without increasing inference cost.
The main goal of YOLOv4 was to make high-accuracy object detection accessible for practical deployment. By refining both the network design and the training pipeline, YOLOv4 demonstrated that significant accuracy gains could be achieved while preserving the speed advantages of single-stage detectors.
Key Technical Ideas
YOLOv4 applied a collection of training and architectural optimizations known as Bag of Freebies and Bag of Specials. Bag of Freebies includes techniques that improve accuracy during training without affecting inference speed, such as Mosaic data augmentation, label smoothing, and advanced loss functions. Bag of Specials refers to architectural modules that slightly increase computation but provide notable accuracy improvements, including Cross-Stage Partial connections (CSP) and optimized feature aggregation. Together, these techniques enhanced feature learning, improved generalization, and increased robustness across diverse datasets.
Architecture
YOLOv4 uses CSPDarknet-53 as its backbone, which applies Cross-Stage Partial connections to reduce redundant gradient information and improve learning efficiency. The neck of the network is built using PANet, enabling effective feature fusion across multiple scales to better handle objects of different sizes.
The detection head follows the YOLO design principle, predicting bounding box offsets, objectness scores, and class probabilities at multiple scales. This architecture allows YOLOv4 to detect small, medium, and large objects effectively while maintaining real-time inference performance.
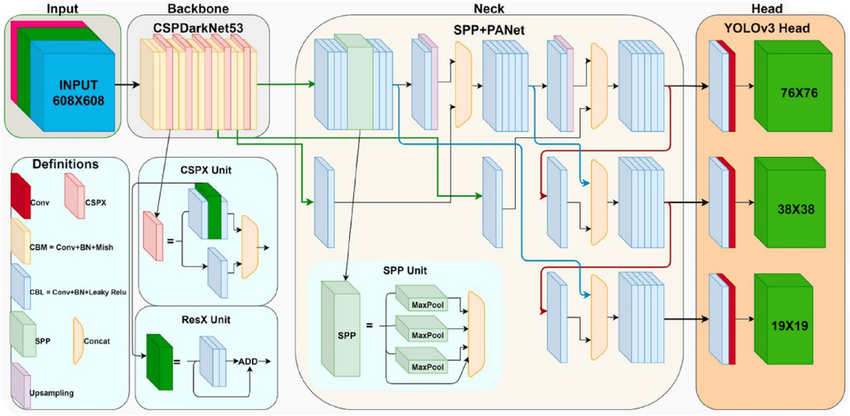
YOLOv5 (2020): PyTorch-Based Implementation
YOLOv5 marked a shift in the YOLO ecosystem toward engineering efficiency and usability rather than proposing a new research paper. Developed and maintained by Ultralytics, YOLOv5 focused on simplifying training, deployment, and experimentation while preserving the core YOLO principles of speed and accuracy. Its release significantly lowered the barrier for practitioners to adopt YOLO in real-world projects.
Rather than redefining detection theory, YOLOv5 emphasized clean code, modular design, and rapid iteration. This approach made YOLO more accessible to developers and accelerated its adoption across industry and research.
Key Technical Ideas
YOLOv5 emphasized practical optimization, introducing automated anchor generation, flexible model scaling, and streamlined training pipelines. It provided multiple model sizes to balance speed and accuracy, along with built-in support for export to deployment formats such as ONNX and TensorRT. These features made YOLOv5 especially appealing for production environments where ease of use and deployment speed are critical.
Architecture
YOLOv5 follows a three-part architecture consisting of a backbone, neck, and head. The backbone, based on CSPDarknet, is responsible for extracting hierarchical visual features from the input image. These features are then passed to the PANet neck, which performs multi-scale feature fusion to better capture objects of different sizes. Finally, the YOLO detection head processes the fused features and outputs the final object detection predictions, including class labels, confidence scores, and bounding box coordinates.
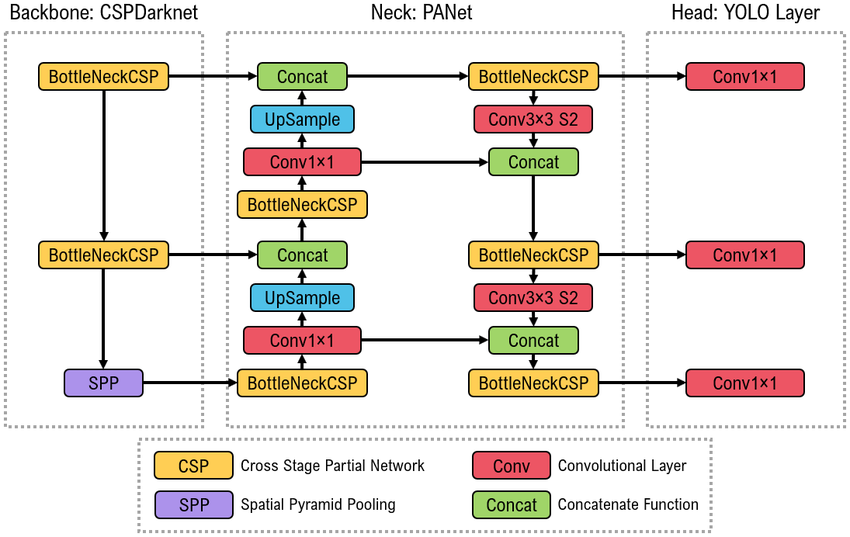
YOLOv6 (2022): Industrial Deployment Focus
YOLOv6 was developed with a strong focus on industrial deployment requirements, such as inference efficiency, hardware compatibility, and training stability. Unlike earlier versions that balanced research and usability, YOLOv6 explicitly targeted production environments where performance constraints are strict.
The design of YOLOv6 reflects a shift toward optimizing both training and inference for real-world systems, particularly in edge and enterprise applications.
Key Technical Ideas
YOLOv6 adopted an anchor-free detection strategy, simplifying bounding box prediction and reducing hyperparameter tuning. It introduced decoupled detection heads, separating classification and localization tasks to improve convergence and accuracy. Additionally, YOLOv6 incorporated hardware-aware optimizations to ensure efficient execution across different deployment platforms.
Architecture
YOLOv6 uses the EfficientRep backbone for efficient feature extraction and the Rep-PAN neck for effective multi-scale feature fusion. The architecture is carefully optimized to balance accuracy and inference speed, making it well suited for industrial-scale deployment.
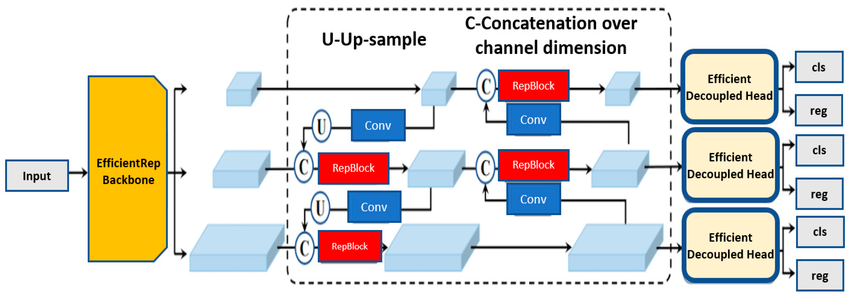
YOLOv7 (2022): Training Efficiency Leader
YOLOv7 focused on improving training efficiency and model performance without increasing inference cost. It demonstrated that better training strategies and architectural refinements could yield state-of-the-art results while preserving real-time detection speed. Rather than prioritizing ease of use or deployment, YOLOv7 emphasized learning efficiency, making it particularly attractive for large-scale training scenarios.
Key Technical Ideas
YOLOv7 introduced re-parameterization techniques that improve training dynamics while keeping inference efficient. It expanded the use of advanced label assignment and optimization strategies to improve gradient flow and learning stability. These techniques allowed YOLOv7 to achieve strong accuracy gains without increasing model complexity.
Architecture
YOLOv7 is built around the E-ELAN backbone, which enhances feature aggregation and learning capacity. The architecture employs compound scaling strategies and optimized detection heads to balance accuracy, speed, and training efficiency.
YOLOv8 (2023): Unified Multi-Task Framework
YOLOv8 represents a major evolution of the YOLO framework by moving beyond object detection into a unified multi-task computer vision system. Developed by Ultralytics, YOLOv8 supports detection, segmentation, pose estimation, and tracking within a single, cohesive API.
This shift reflects the growing demand for versatile vision models that can handle multiple tasks without maintaining separate architectures.
Key Technical Ideas
YOLOv8 adopts anchor-free detection by default, simplifying training and improving generalization. It introduces native multi-task support, allowing a single model family to address different vision problems. A simplified API and standardized workflows further enhance usability and consistency across tasks.
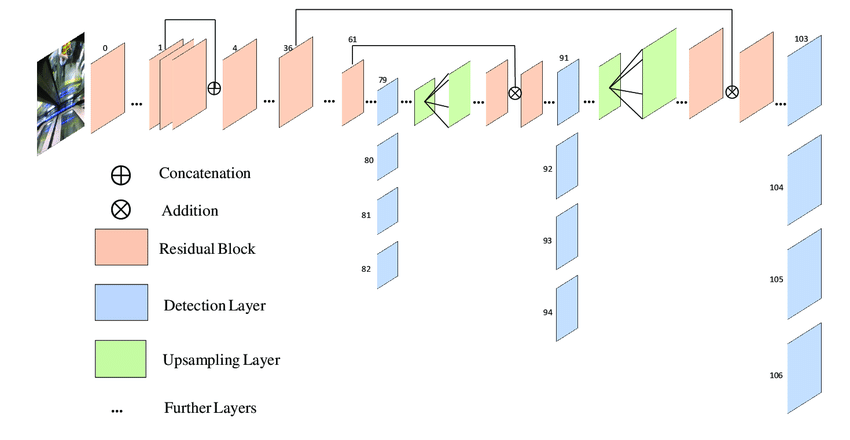
Architecture
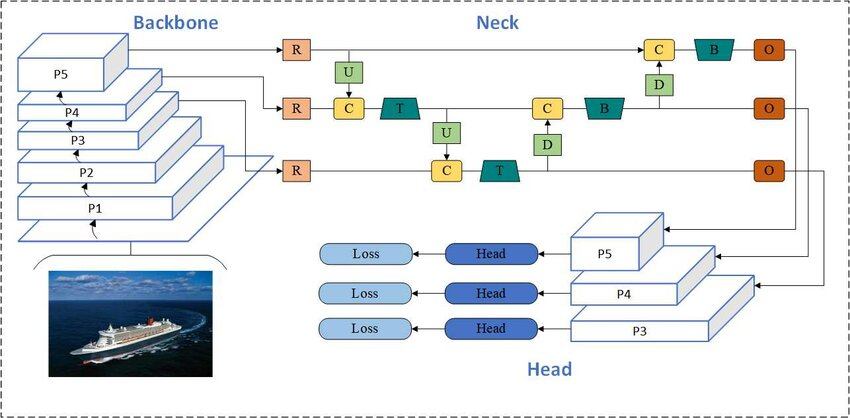
YOLOv8 uses a CSP-style backbone with decoupled task-specific heads. The architecture shares feature extraction across tasks while maintaining separate heads for detection, segmentation, pose, and tracking, enabling efficient multi-task learning.
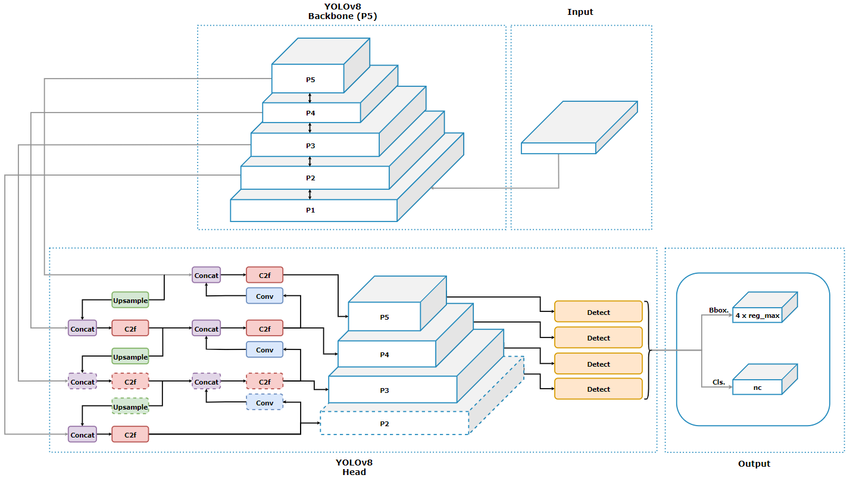
YOLOv9 (2024): Feature Reliability Improvements
YOLOv9 focused on improving the reliability and effectiveness of feature learning. Instead of increasing model size or complexity, YOLOv9 addressed inefficiencies in how features are propagated and learned during training.
This version reflects a growing emphasis on understanding and controlling learning behavior in deep detection models.
Key Technical Ideas
YOLOv9 introduced Programmable Gradient Information (PGI) to improve how gradients are propagated through the network. By reducing redundant feature learning and emphasizing relevant gradients, YOLOv9 improved training stability and representation quality without increasing inference cost.
Architecture
YOLOv9 employs an enhanced backbone incorporating PGI mechanisms, along with optimized feature aggregation pathways. This design improves feature reuse and learning efficiency while maintaining real-time performance.
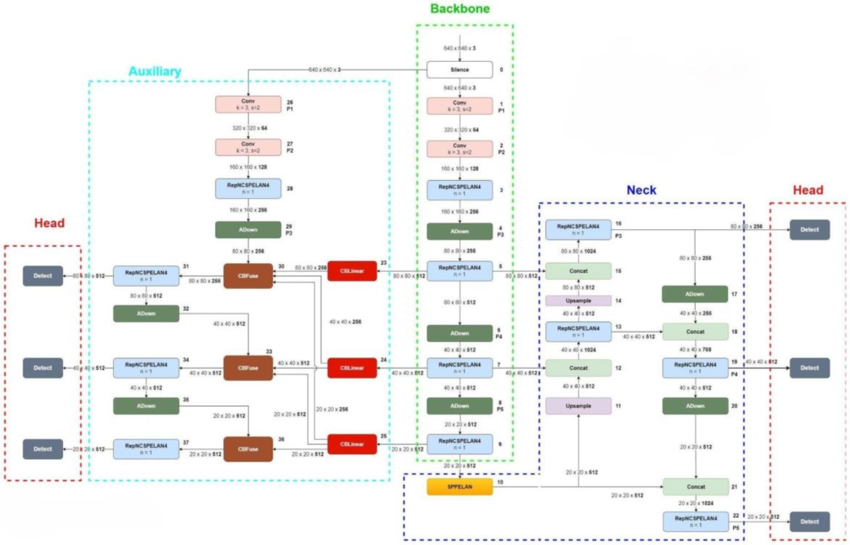
YOLOv10 (2024): End-to-End Detection Without NMS
YOLOv10 aimed to simplify the detection pipeline by removing the need for Non-Maximum Suppression (NMS) during inference. This approach enables a fully end-to-end detection process, reducing post-processing latency and simplifying deployment.
YOLOv10 reflects a broader trend toward minimal and fully differentiable detection pipelines.
Key Technical Ideas
YOLOv10 introduced NMS-free detection using optimized assignment strategies and end-to-end training. By integrating detection confidence and assignment directly into the model, YOLOv10 eliminated the need for traditional post-processing steps while maintaining competitive accuracy.
Architecture
YOLOv10 features an optimized detection head designed for end-to-end inference. The architecture supports dual assignment strategies and simplified inference logic, enabling faster and cleaner deployment pipelines.
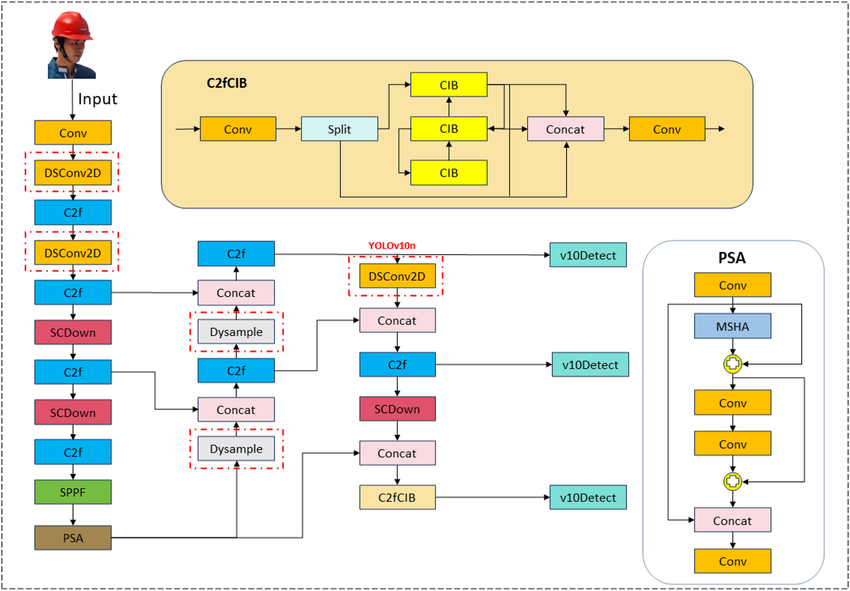
YOLO11 (2024): Toward Scalable Vision Systems
YOLO11 represents the continued evolution of YOLO toward scalable, production-ready vision systems. It builds on the multi-task capabilities introduced in YOLOv8 and further refines performance, scalability, and deployment efficiency.
This version emphasizes consistency, extensibility, and readiness for large-scale applications.
Key Technical Ideas
YOLOv11 enhances multi-task learning, improves scalability across datasets and tasks, and incorporates deployment-oriented optimizations. The focus is on building robust vision systems that can adapt to diverse real-world requirements.
Architecture
YOLOv11 uses a unified backbone shared across detection, segmentation, and pose estimation tasks, combined with modular task-specific heads. This design supports efficient scaling and streamlined deployment in production environments.
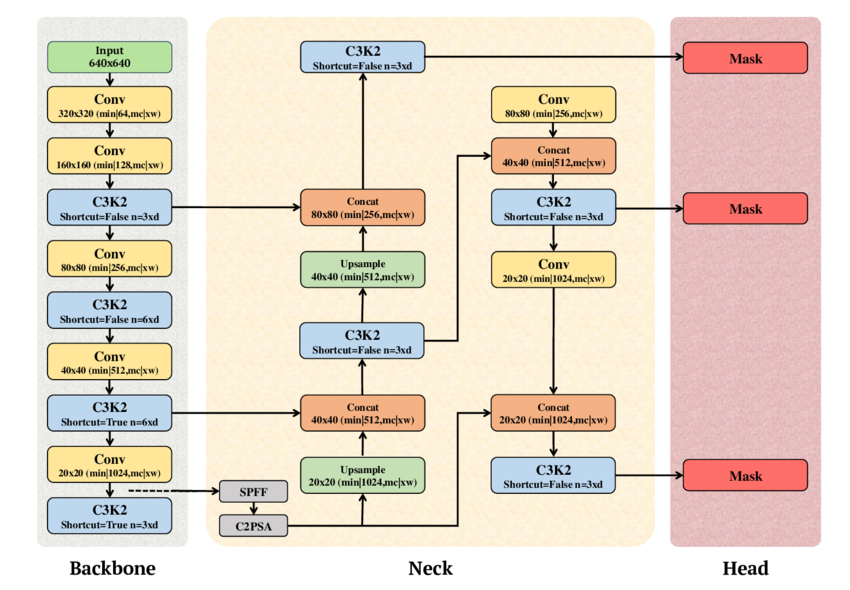
Comparison of YOLO Versions
The table below summarizes the key differences across major YOLO versions, highlighting when each model was released, who developed it, and its main strengths and limitations. This comparison provides a high-level view of how YOLO has evolved over time in terms of performance, usability, and application focus.
| YOLO Version | Year | Introduced By | Advantages | Disadvantages |
|---|---|---|---|---|
| YOLOv1 | 2016 | Joseph Redmon et al. | Real-time detection, single-stage pipeline, simple end-to-end design | Poor small-object detection, coarse grid, limited localization accuracy |
| YOLOv2 | 2017 | Joseph Redmon et al. | Anchor boxes, better localization, multi-scale training, faster convergence | Still struggles with very small or crowded objects |
| YOLOv3 | 2018 | Joseph Redmon et al. | Multi-scale detection, stronger backbone, improved small-object detection | Increased model complexity, slower than v2 |
| YOLOv4 | 2020 | Bochkovskiy et al. | High accuracy-speed balance, advanced data augmentation, production-ready | More complex training pipeline |
| YOLOv5 | 2020 | Ultralytics | Easy to train and deploy, PyTorch-based, modular design | No official research paper, implementation-driven |
| YOLOv6 | 2022 | Meituan | Anchor-free design, industrial optimization, efficient inference | Less flexible for research experimentation |
| YOLOv7 | 2022 | Wang et al. | Strong training efficiency, state-of-the-art accuracy at release | Complex architecture, higher training cost |
| YOLOv8 | 2023 | Ultralytics | Unified multi-task support, anchor-free, clean API | Requires more data for multi-task training |
| YOLOv9 | 2024 | Wang et al. | Improved feature learning (PGI), stable training | More research-oriented, limited tooling |
| YOLOv10 | 2024 | Tsinghua University | NMS-free end-to-end detection, simplified inference | New design, still maturing in adoption |
| YOLOv11 | 2024 | Ultralytics | Scalable multi-task framework, production-focused | Limited public documentation (early stage) |
Data Impact: How YOLO Evolution Changed Data and Annotation
As YOLO models evolved in capability and scope, the requirements for training data and annotations became increasingly complex. What was once a model-centric challenge has gradually shifted toward data quality, structure, and scalability.
Model Evolution Increases Dataset Complexity
As YOLO progressed from early single-task detectors to modern multi-task frameworks, models became more sensitive to data quality, diversity, and balance. Accurately detecting small, overlapping, or rare objects now requires higher-resolution images, richer visual variation, and more precise annotations than earlier YOLO versions.
From Simple Boxes to Multi-Dimensional Annotations
Early YOLO models relied primarily on bounding box annotations and class labels. Modern YOLO versions extend beyond basic detection to support tasks such as instance segmentation, pose estimation, and object tracking, significantly increasing annotation depth and structural complexity.
Multiple Annotation Types Within a Single Dataset
Today’s YOLO datasets may include multiple annotation formats, such as:
- Bounding boxes for object detection
- Segmentation masks for pixel-level understanding
- Keypoints for pose estimation
- Temporal labels for video-based tracking
Ensuring consistency across these annotation types within a single dataset has become a critical challenge.
Real-World Example: Autonomous Driving Datasets
Autonomous driving datasets often combine object detection (vehicles and pedestrians), segmentation (roads and lanes), keypoints (human pose), and video tracking across frames. Training modern YOLO models on such datasets highlights how annotation complexity increases alongside model capability.
Data Workflows Become as Important as Model Design
As YOLO evolved into a multi-task computer vision framework, the primary challenge shifted from model architecture to data preparation, annotation quality, and scalability. Modern YOLO development requires datasets that support multiple annotation types—such as bounding boxes, segmentation masks, keypoints, and video-based labels—within a single, consistent pipeline.
Unitlab AI supports these requirements by enabling multi-task and multi-modal data annotation across images and video. By streamlining annotation workflows and supporting diverse label formats, Unitlab helps teams prepare high-quality datasets that align with the growing complexity of modern YOLO models.
Conclusion
The evolution of YOLO from YOLOv1 to YOLOv11 highlights a clear shift in computer vision—from fast, single-task object detection to unified, multi-task vision frameworks. Each YOLO version introduced architectural and training improvements that expanded capability while preserving real-time performance.
As YOLO models grew more powerful, the main challenge moved beyond model design to data quality, annotation complexity, and scalability. Modern YOLO systems rely on diverse, high-resolution datasets that support multiple annotation types across images and video, making efficient data workflows essential.
Looking ahead, the success of YOLO-based applications will increasingly depend on how well teams manage complex datasets and multi-task annotations at scale. For more information on scalable computer vision data workflows, visit Unitlab AI.

