

When we think about version control, most of us picture Git repositories or Apache Subversion and tracking changes in code. Software needs version control because code is neither static nor written all at once; it evolves over time and is worked on by many people.
No team writes hundreds of thousands of lines of code in one sitting. Ironically, Git itself has been under development since 2005. Version control allows teams to debug, roll back, and move forward with confidence.
The same applies in machine learning and AI, where another key asset evolves just as much: the dataset. When everyone has access to the same algorithms, the dataset (more specifically, its quality and scale) becomes the differentiator in a product’s success.

Your model is only as good as the data it learns from. Datasets, especially labeled ones, are constantly revised, corrected, and expanded. In that sense, datasets are dynamic, iterative entities like code and require version control. While there’s no standard solution yet, any company building serious AI/ML models needs some kind of system to version and manage datasets effectively.
How would a team of 20 engineers build a complex enterprise product in 2025 without version control? They’d struggle. Similarly, without version control for datasets, teams will face messy outcomes: inconsistent results, irreproducible models, and untraceable regressions.
This post is a practical look into why dataset version control is necessary, what benefits it offers, and how it works in real-world projects.
Why Version Control for Datasets
As mentioned above, AI/ML datasets are iterative. They’re high-volume, diverse, and often updated by multiple people. In any serious ML project, datasets are always changing:
- Annotators label raw data
- Reviewers fix errors or apply new guidelines
- Engineers add new data
- Data scientists experiment with filtering or preprocessing
- Others may contribute as well
On top of that, machine learning models are also iterative:
- Models are retrained regularly on new or improved data
- Models are tested against evolving benchmarks
- Performance depends heavily on the version of the dataset used
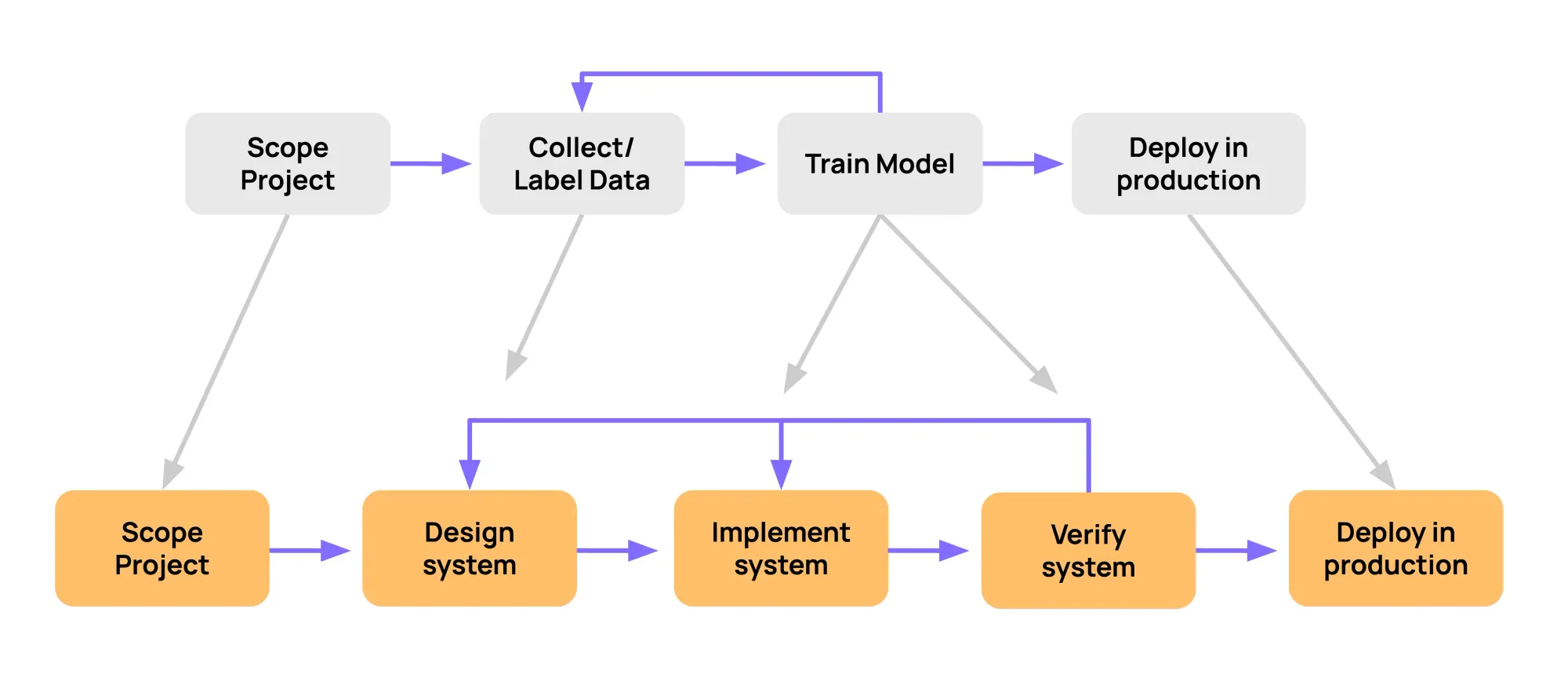
It becomes obvious why version control is crucial. Without it, you can’t easily answer questions like:
- What dataset version was used to train this model?
- When were labels corrected and by whom?
- Why did model performance suddenly drop?
Just like software matured with Git, dataset development needs structure. Although there's no one-size-fits-all tool yet, many data annotation platforms now offer version control features to bridge the gap.
Key Components of Dataset Version Control
There’s no single gold standard for dataset versioning, but a solid system needs to do more than just back up files. Here are the core components:
- Snapshots: At every key point (initial annotation, review, or augmentation) you should be able to save the state of your dataset and return to it later.
- Metadata Tracking: It’s critical to know who made what change, when, and why. Metadata is what makes datasets auditable and debuggable.
- Change Logs: You need a way to track what was added, removed, or modified, much like Git logs for code.
These features make your data process transparent and reproducible, especially when datasets evolve alongside models.
Benefits of Good Dataset Versioning
Once dataset version control is in place, the payoff is immediate and compounds over time.
✅ Reproducibility: You can always trace a model back to the dataset version it was trained on. Or you can clone the latest version and start over.
✅ Collaboration: Teams can work in parallel. Data scientists continue training on a stable release while annotators work on the next one.
✅ Traceability: Versioning lets you see what changed, when, and why. Critical for debugging and for answering questions like: when did the drop in accuracy happen?
✅ Disaster Recovery: If something goes wrong, you can roll back to a previous version without losing your progress or your model's training data.
Dataset Version Control in Practice
Let’s look at a hands-on example: image-based dataset versioning inside Unitlab Annotate, a fully automated, accurate data annotation platform. In this earlier post, we already had a project with two dataset releases.
Automation Workflow | Unitlab Annotate
Now, let’s say we upload another image and annotate it:
Adding & labeling a new image | Unitlab Annotate
Next, we publish a new dataset version in the Release Datasets panel:
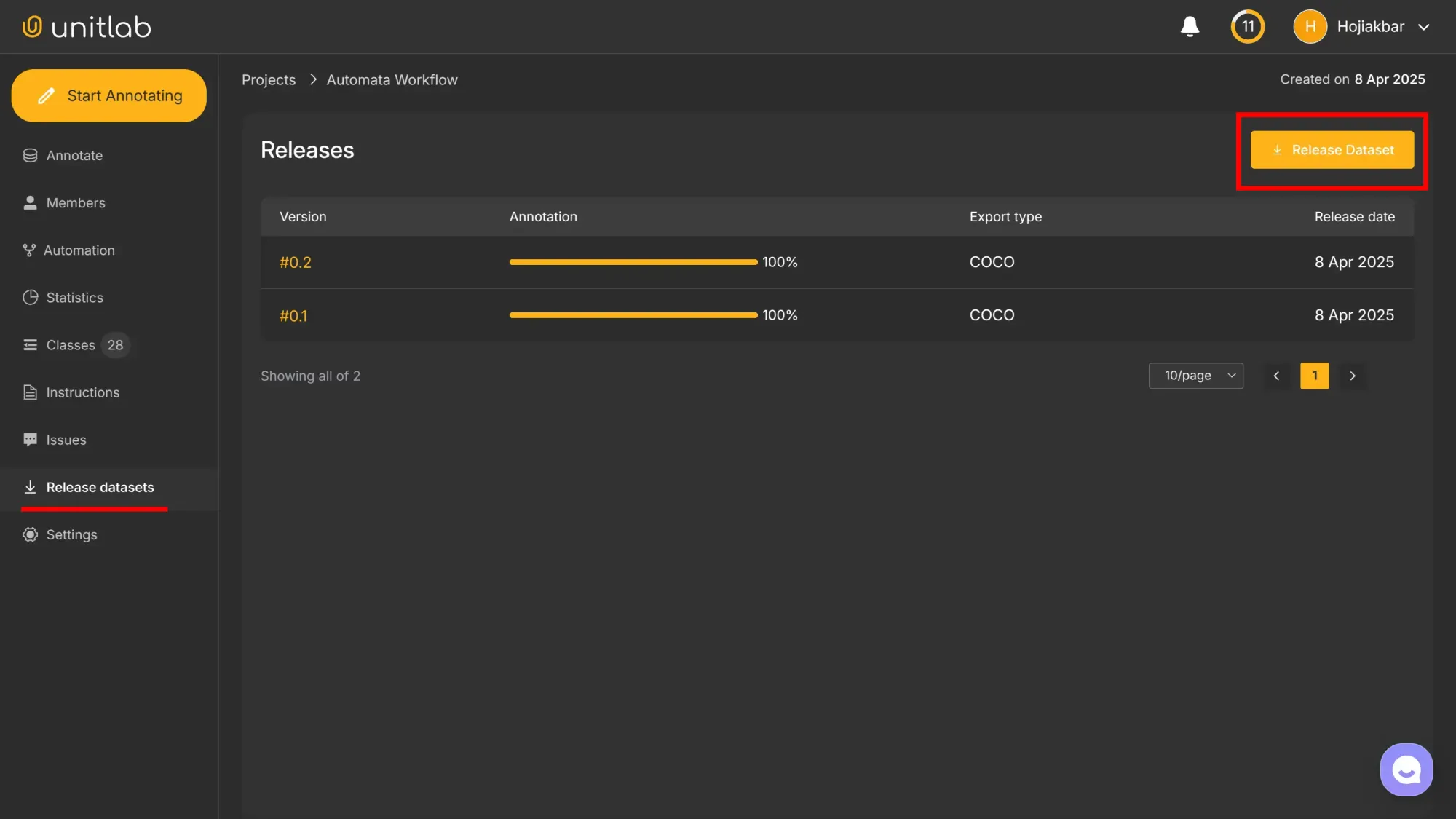
We choose the dataset format, for now, it’s either COCO or YOLO, both popular in computer vision tasks:
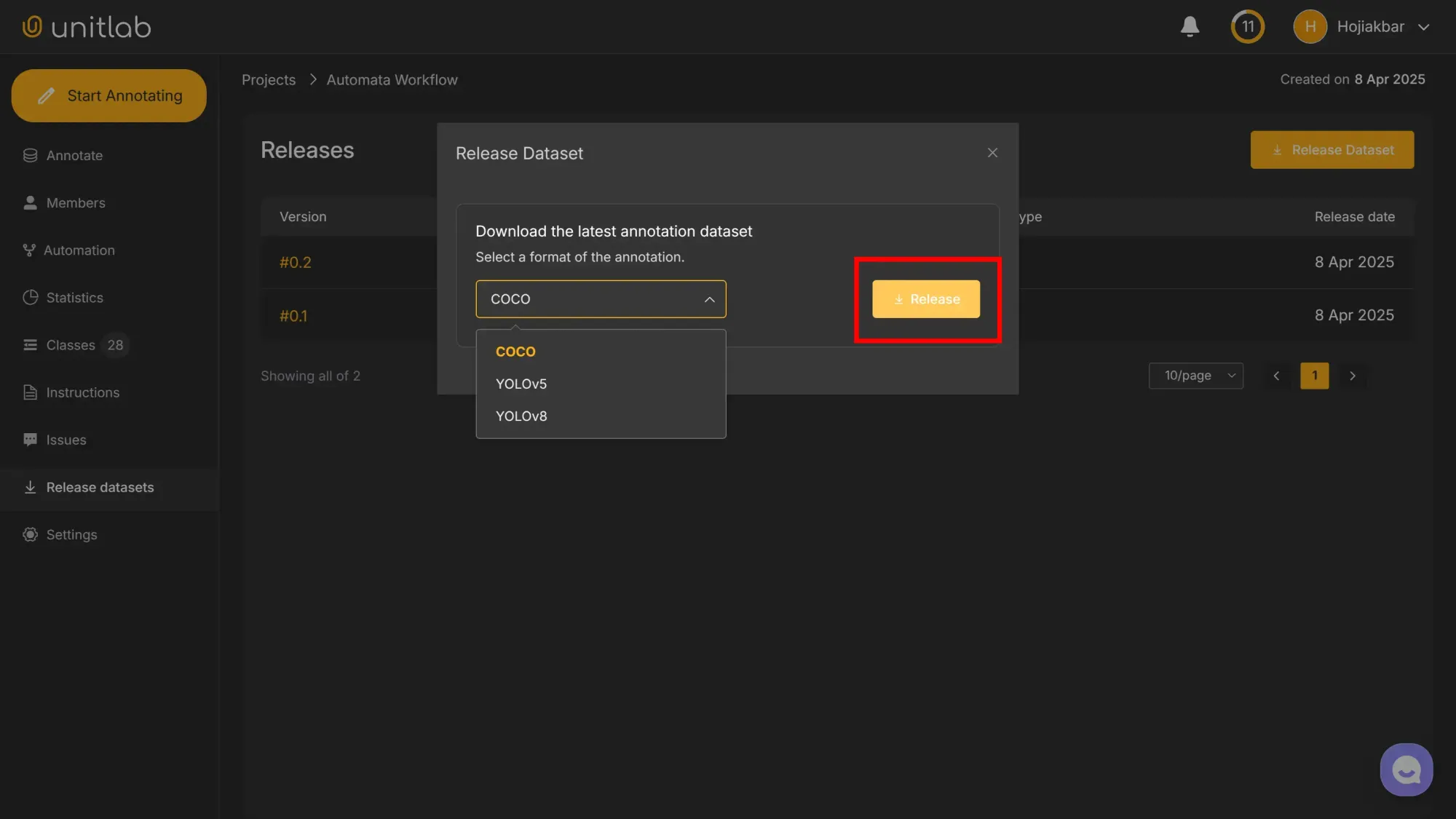
The third dataset version, 0.3, is now released, which contains our latest labeled image:
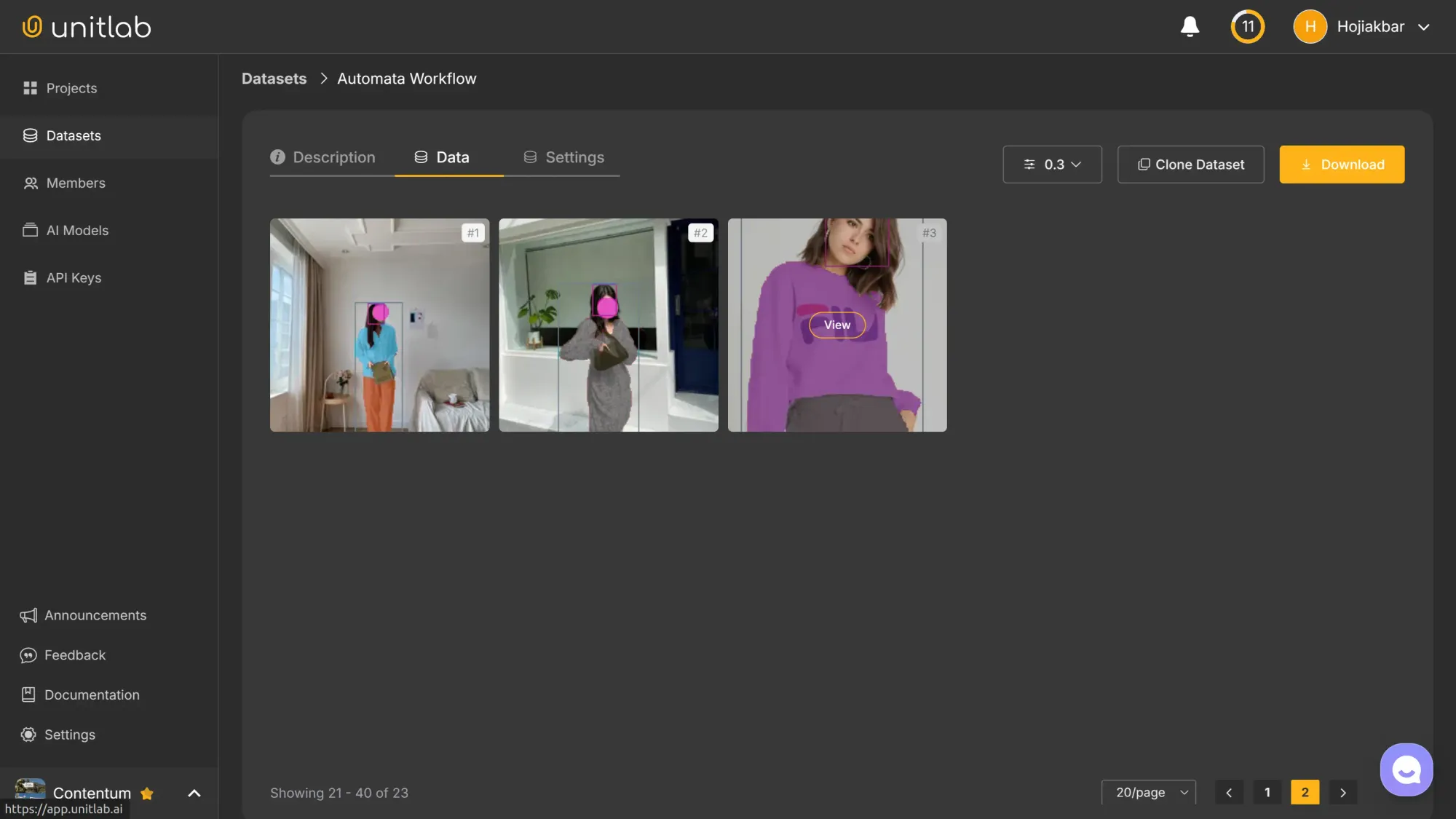
This process is clean, structured, and scalable, exactly what version control is meant to deliver.
Conclusion
We need dataset version control because ML development is inherently iterative, just like software development. Models change. Data changes. Mistakes happen. Versioning makes it possible to move fast without breaking things.
While we don’t yet have a dataset versioning standard as mature as Git is for code, the landscape is evolving. Most serious platforms offer some form of dataset versioning, as we’ve seen in the case of Unitlab Annotate. If you’re still manually tracking datasets with folders like "0.3_version," it might be time to rethink your workflow.
Explore More
Check out these resources for more on AI/ML datasets:
- How to Make Ideal Datasets: Best Practices in 2026
- 8 Common Mistakes in Preparing Datasets for Computer Vision Models
- Dataset Management at Unitlab AI [2026]
References
- Doris Xin and et. al. (May 2018). How Developers Iterate on Machine Learning Workflows: A Survey of the Applied Machine Learning Literature. arXiv: Source
- Einat Orr (Feb 26, 2024). Data Version Control: What It Is and How It Works. Lakefs IO: Source
- Michael Abramov (Feb 05, 2025). Dataset Version Control: Keeping Track of Changes in Labeled Data. Keymakr Blog: Source

