
Note: This is a simplified, quick version of our project creation docs. For full information, refer to this page:
Dataset Management Docs | Unitlab Annotate
Efficient dataset management is vital for building AI and Machine Learning (ML) models and computer vision projects. Dataset in computer vision, essentially, is a collection of labeled data ready for training AI/ML models.
Organizations and analysts rely on dataset management to ensure data quality, compliance, and business value, and datasets are often stored in data repositories and databases.
Dataset management refers to the process of creating and managing these source data for training and testing. Because training, testing, and validating computer vision models is an iterative process, effectively managing different versions of our source data is a fundamental task.
In this post, we learn how to release and manage a dataset in Unitlab Annotate.
Dataset Management in Unitlab Annotate
Unitlab Annotate simplifies and centralizes dataset management with version control, similar to git commits, allowing datasets to evolve over time while staying consistent and organized.
Data annotators can release specific versions for different uses, update them as additional source data are added, and keep track of all changes, ensuring smooth versioning and reproducibility. The platform also assigns access permissions to datasets to maintain data integrity and safety.
Metadata, attributes, and variables are defined for each file, and files can be stored in various formats, such as csv and xml, to facilitate data analysis and statistical analysis. The structure of datasets, whether in hierarchical formats like JSON, XML, or YAML, supports different analytical needs and use cases.
Releasing a dataset involves creating a version that is ready for use in AI or business applications. As the dataset grows, newer versions can be released to reflect improvements. Adequate data storage solutions, such as data lakes, are essential as well to handle increasing storage capacity requirements as datasets scale.
Version control ensures that every change is tracked, with options to revert to earlier versions or compare updates. Maintaining a record of different versions enables organizations to revert to a previous version if a mistake is made, ensuring data integrity and validation.
Monitoring datasets for quality and consistency is crucial to prevent inconsistencies across computer vision projects and fosters better teamwork.
Datasets can have different data annotation formats, depending on the use case. This flexibility is useful as they can evolve with a project’s needs and requirements.
For instance, a few examples of different types of data that can be included in datasets are images, audio recordings, and objects. Data visualization and analysis tools enable data scientists and analysts to analyze datasets and extract value.
Unitlab Annotate enables organizations to address data governance challenges, enable features for managing files, and integrate with other systems and data repositories to support machine learning models, code, and research workflows.
Robust processes are in place to ensure data quality, compliance, and workflow optimization. The platform also supports managing data from multiple data sources and the ability to store datasets securely in scalable environments. Additionally, users can link or manage related datasets for comprehensive data analysis and easier integration.
Setting up a project
First, in order to release an initial version of a dataset, we need to set up a project and annotate the data. The initial data files you upload represent raw data; these are the original, unprocessed images or information that will be transformed into a labeled training set.
For example, you might upload a folder of unannotated images as your starting point. The annotated images will then form the training datasets used for machine learning models.

Project Creation at Unitlab Annotate
In our previous post, we learned how to set up a project at Unitlab Annotate. If you do not have a project, check out our guide and set up a project. We will continue with the project we created in the last post.
Data Labeling
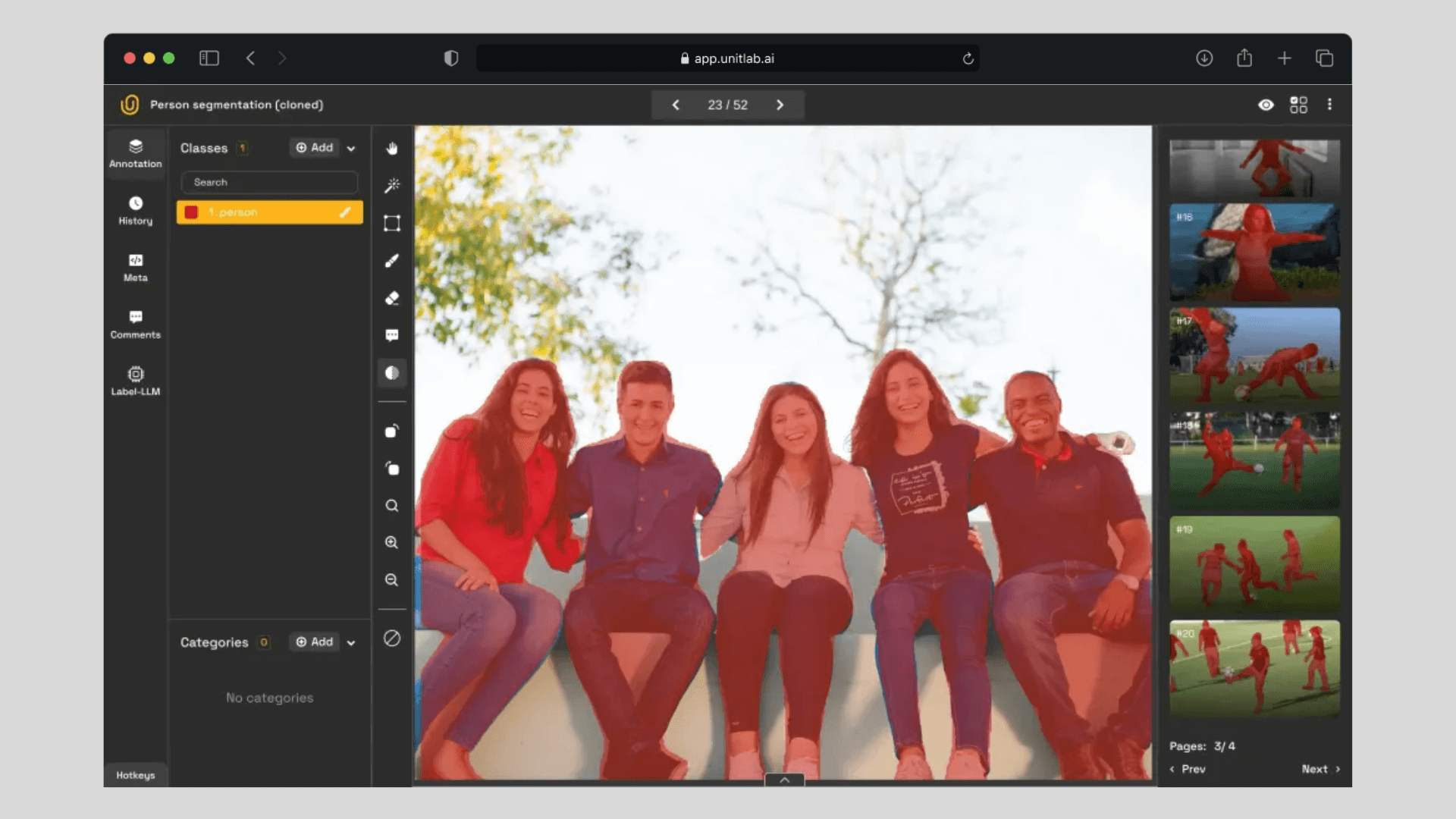
To release a dataset, we first need to label our source data. If an image is not labeled, then it will not be included in the dataset when it is released. The difference between a project and dataset is that the project contains all images, whereas the released dataset contains only the labeled images with specific values assigned during image annotation.
Various types of data can be annotated, including unstructured data such as images, videos, and text documents. For instance, for text-based unstructured data, natural language processing techniques can be used to extract and label relevant information.
Depending on how the project is set up, an AI Model can be used to automatically annotate, or annotators can label images themselves. In our case, we have selected as our AI model to auto-annotate our source images.
Auto-annotation using AI has several benefits: primarily, using AI models can speed up the image labeling process up to 15 times, using the batch auto annotation. It also contributes to improved accuracy and model performance by ensuring consistent and reliable annotations, which are essential for high quality datasets. In the demo video below, we present how it works:
Batch Auto Annotation Process | Unitlab Annotate
After the data annotation process, the first version of our dataset will be ready to be released and used for business purposes for training computer vision models. In our case, all 6 of the images in our project are auto labeled in a batch process. When we release this dataset, all images are included because they are all labeled.
Dataset Release
After annotating our project, we can release a dataset in the dashboard of our project. Because we are releasing the dataset for the first time, we do not have previous versions. The version automatically starts at 0.1. We can now release a dataset, by clicking the “+ Release Dataset” button.
When releasing new versions, it is important to incorporate new data to keep the dataset up to date and ensure model accuracy.
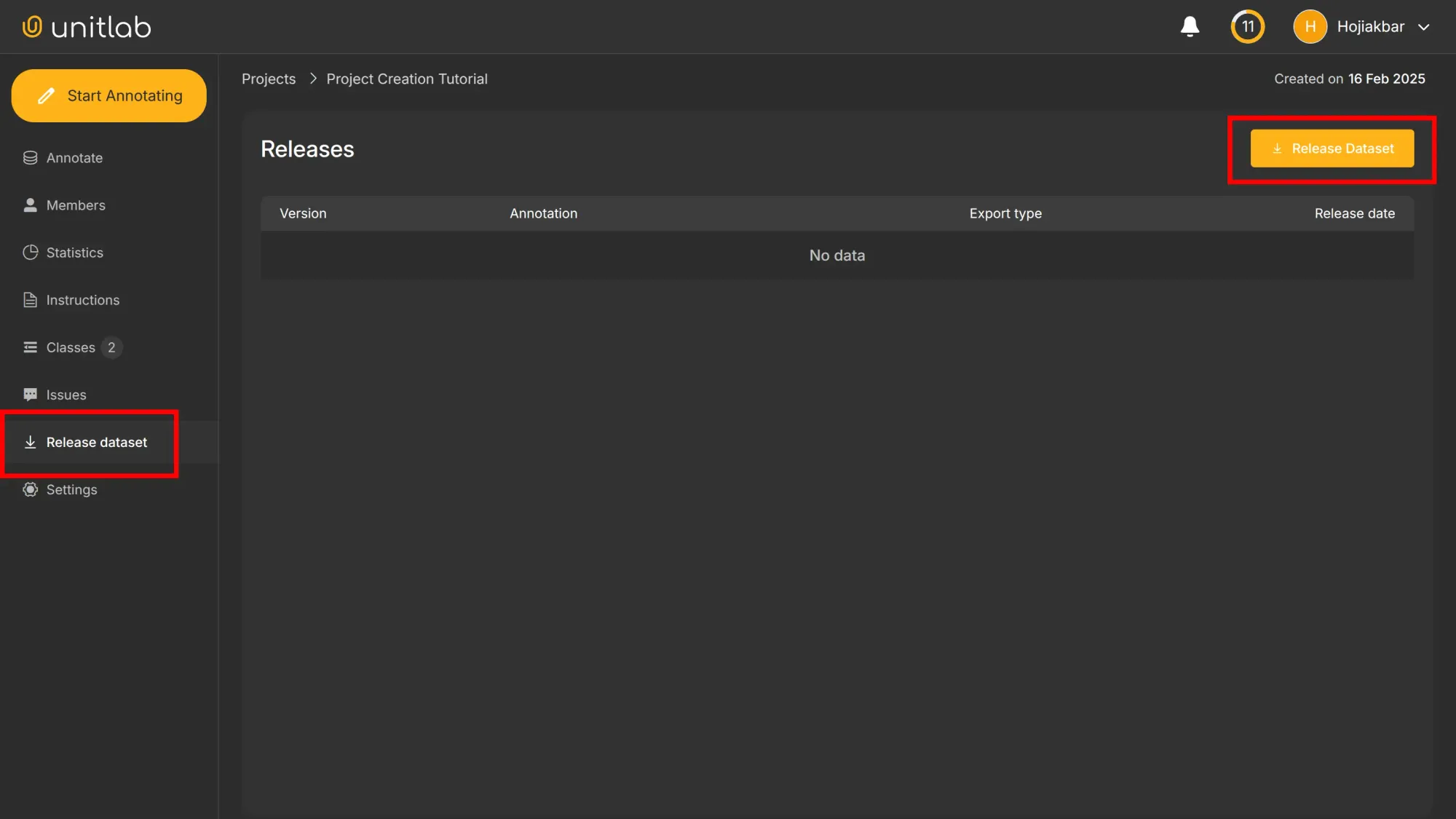
Since we are currently under the Pro plan. which is ideal for AI Teams, startups, and companies building high-scale training data and AI products, we release a private dataset by default. If we want to make it a public one, we can manage our dataset after the release.
When handling sensitive data, it is crucial to ensure proper access controls to protect privacy and comply with regulations.
Under the fee plan, which is ideal for hobbyists, students, and individual users, the released dataset will become a public dataset by default in the Unitlab Annotate database. If you need private datasets, you can check out other plans available at Unitlab AI.
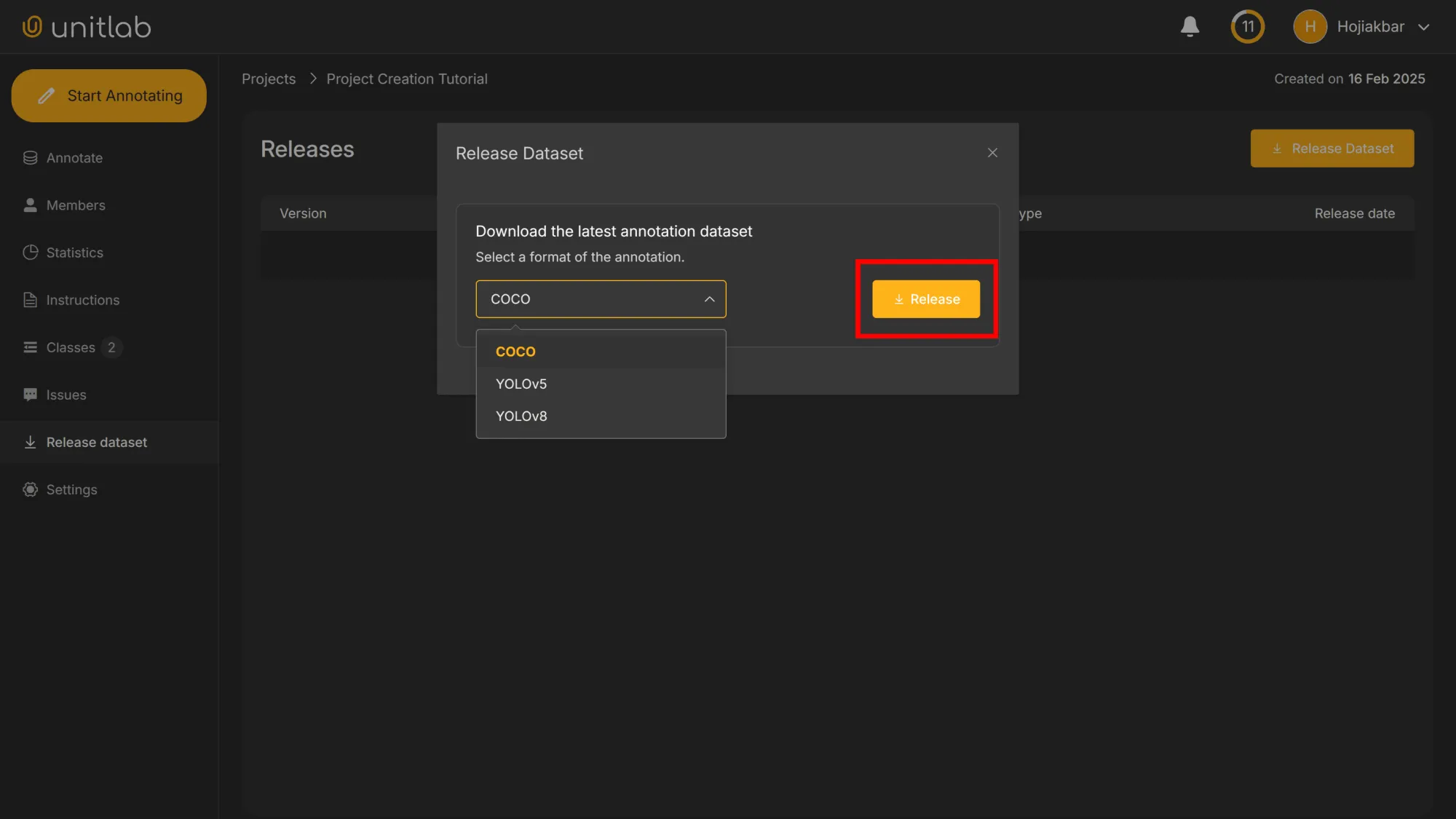
We must choose the format for our dataset. We can choose from COCO, YOLOv5 or YOLOv8; other types are coming in the future releases of Unitlab Annotate. We choose the general purpose COCO. However, it is possible to choose other formats depending on the business needs. Our initial version, 0.1, is now created:
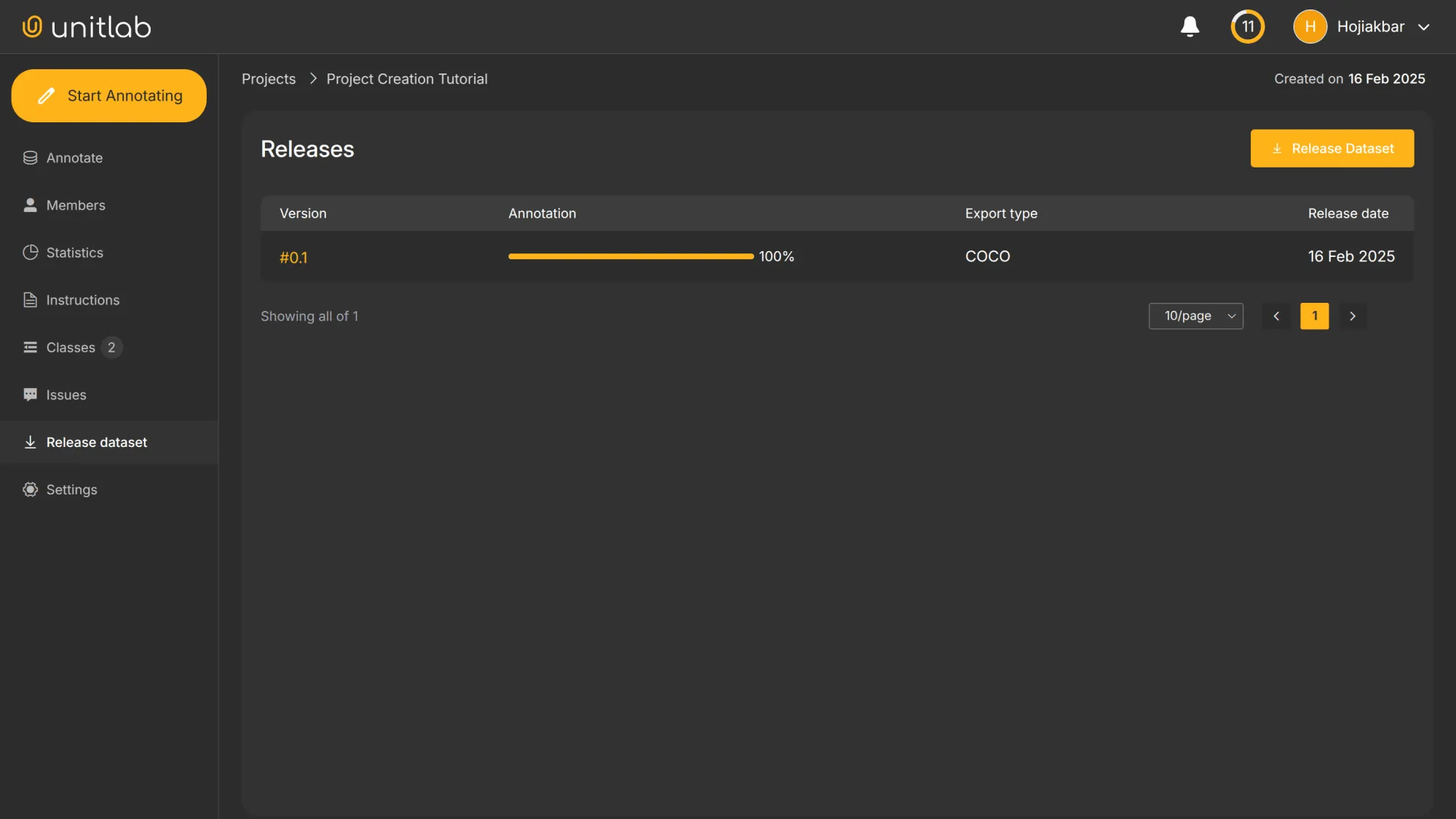
Our dataset by default takes on the name of the project and is accessible to you on the Dashboard of the Unitlab Annotate.
The dashboard also provides search functionality, allowing you to quickly locate specific datasets or data points:
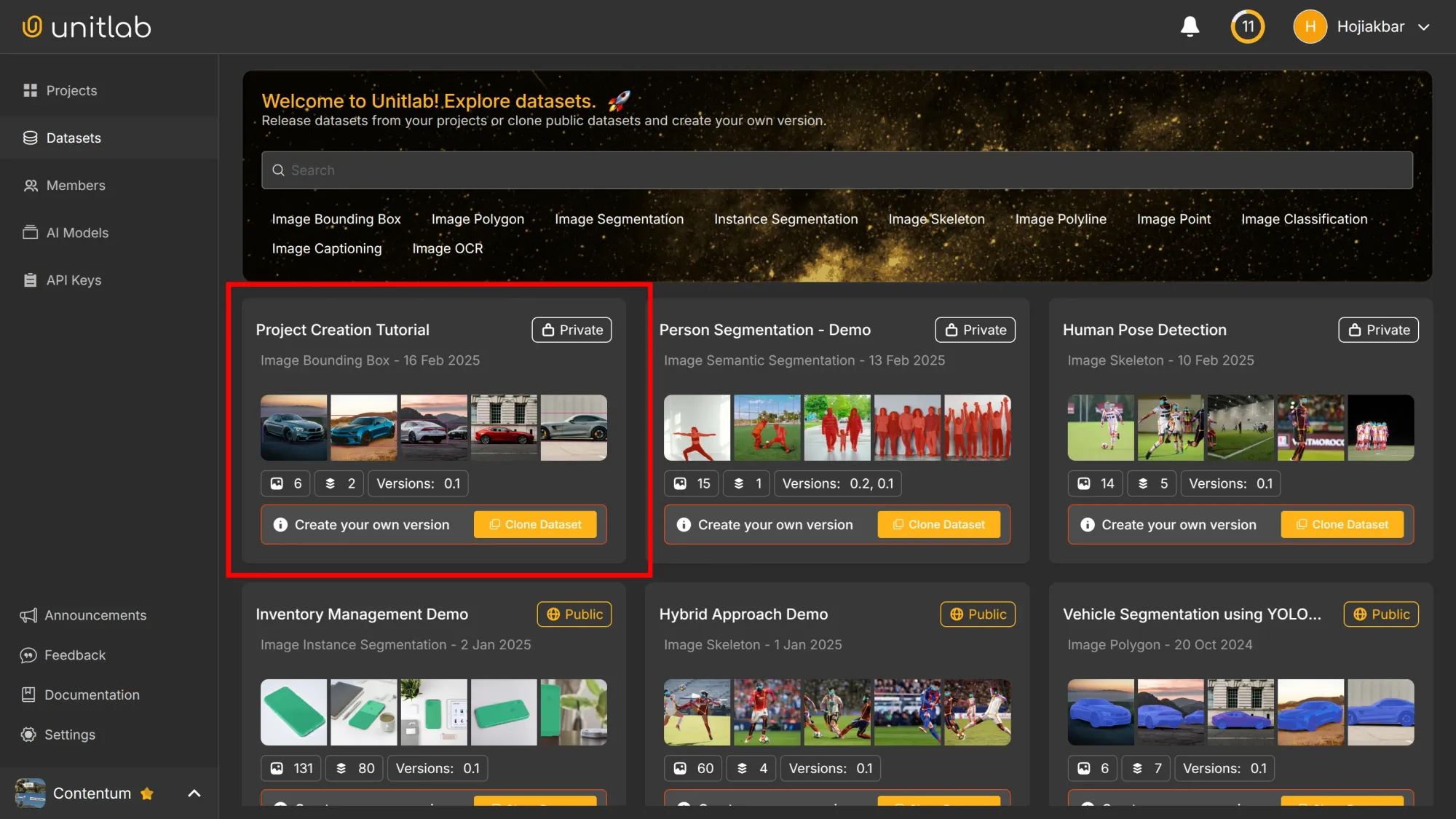
Dataset Management
With our dataset released, we can now manage it. When you click on the newly created dataset, we can carry out several management actions, including setting edit permissions for users.
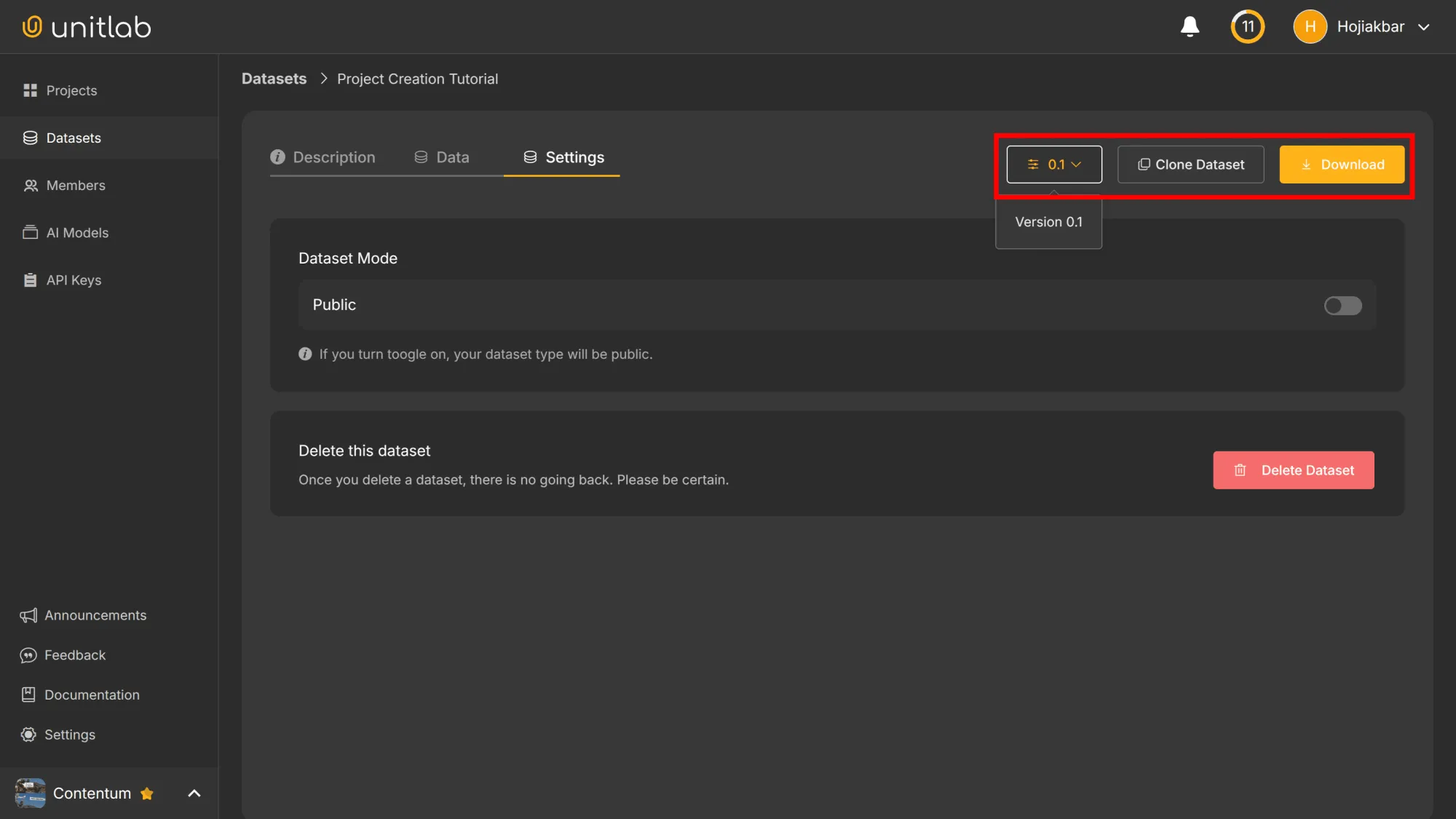
Public Dataset
Currently, our dataset is private; only our team can access it. If we want to make it public, we need to choose an open-source license. An open-source license grants certain permissions to the user that is using a particular piece of software or dataset. In essence, the license dictates what can and cannot be done with the dataset. There are, as of now, four licensing options available at Unitlab Annotate:
- MIT - Permissive, allows commercial use
- CC BY 4.0 - Requires attribution
- Public Domain - No restrictions
- BY-NC-SA 4.0 - Restricts commercial use and requires the same license for derivatives
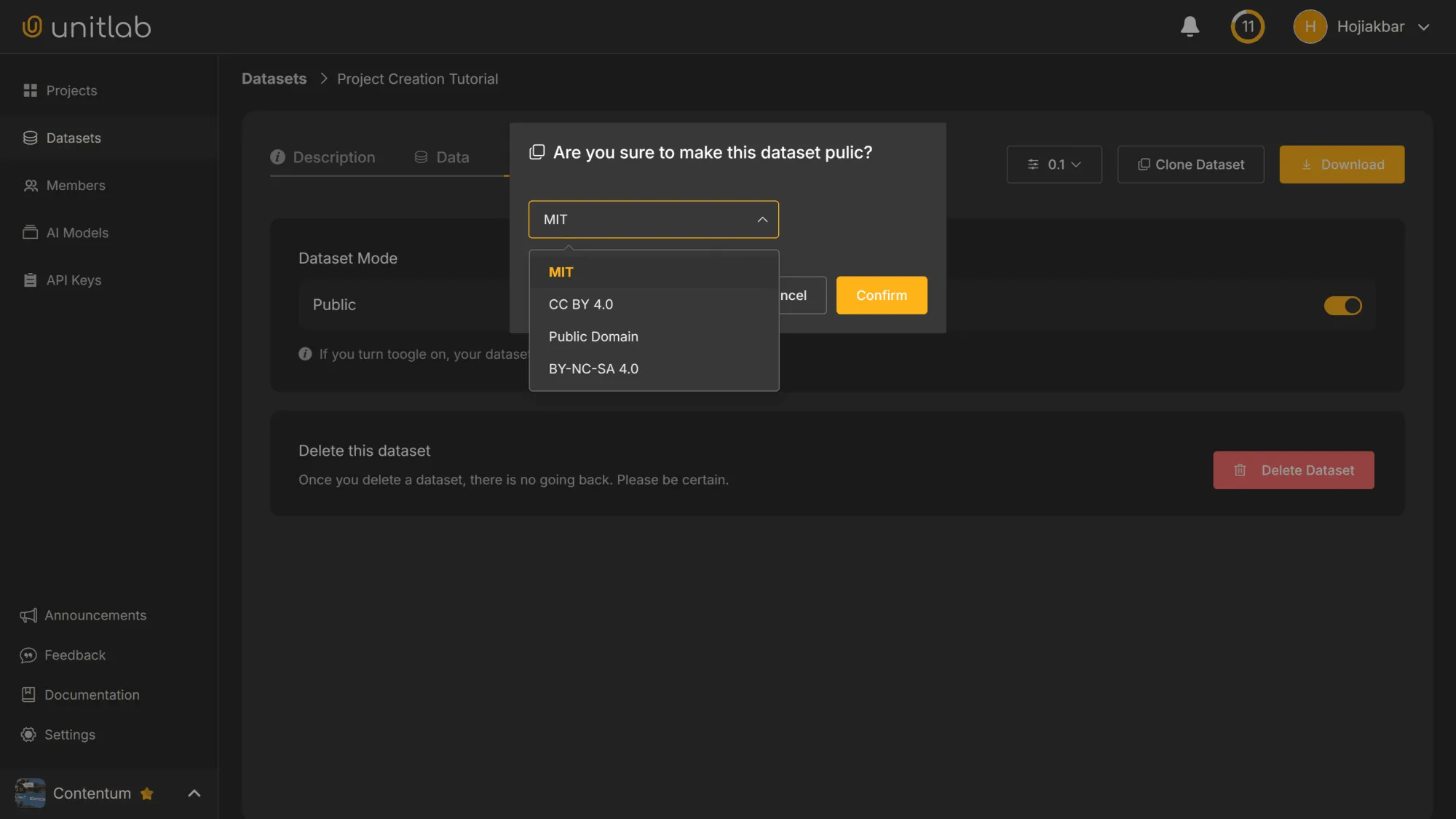
For our purposes here, we use the MIT license, which is widely used for open-source software and open datasets. After choosing the format and the license, our dataset becomes public and visible in the Dataset section of the data annotation platform.
If you are under the Pro plan, you can switch your dataset to a private one easily in the same way.
Dataset Download
Our public dataset is now released and ready to be used. Unitlab users can now clone it and use it for their own computer vision projects if necessary, under the MIT license.
If we have a need to download the source images or data annotations in our labeled dataset to our local storage, Unitlab Annotate enables us to download them in a programmatic (CLI and Python SDK) and non-programmatic (Web browser) way.
If we want to download the source images, we can download the images in a zip format. We can separately download the image annotations in a JSON format.
As the primary use case of annotation is for training and testing computer vision models, the models expect the data annotations in a standardized format that they can understand.
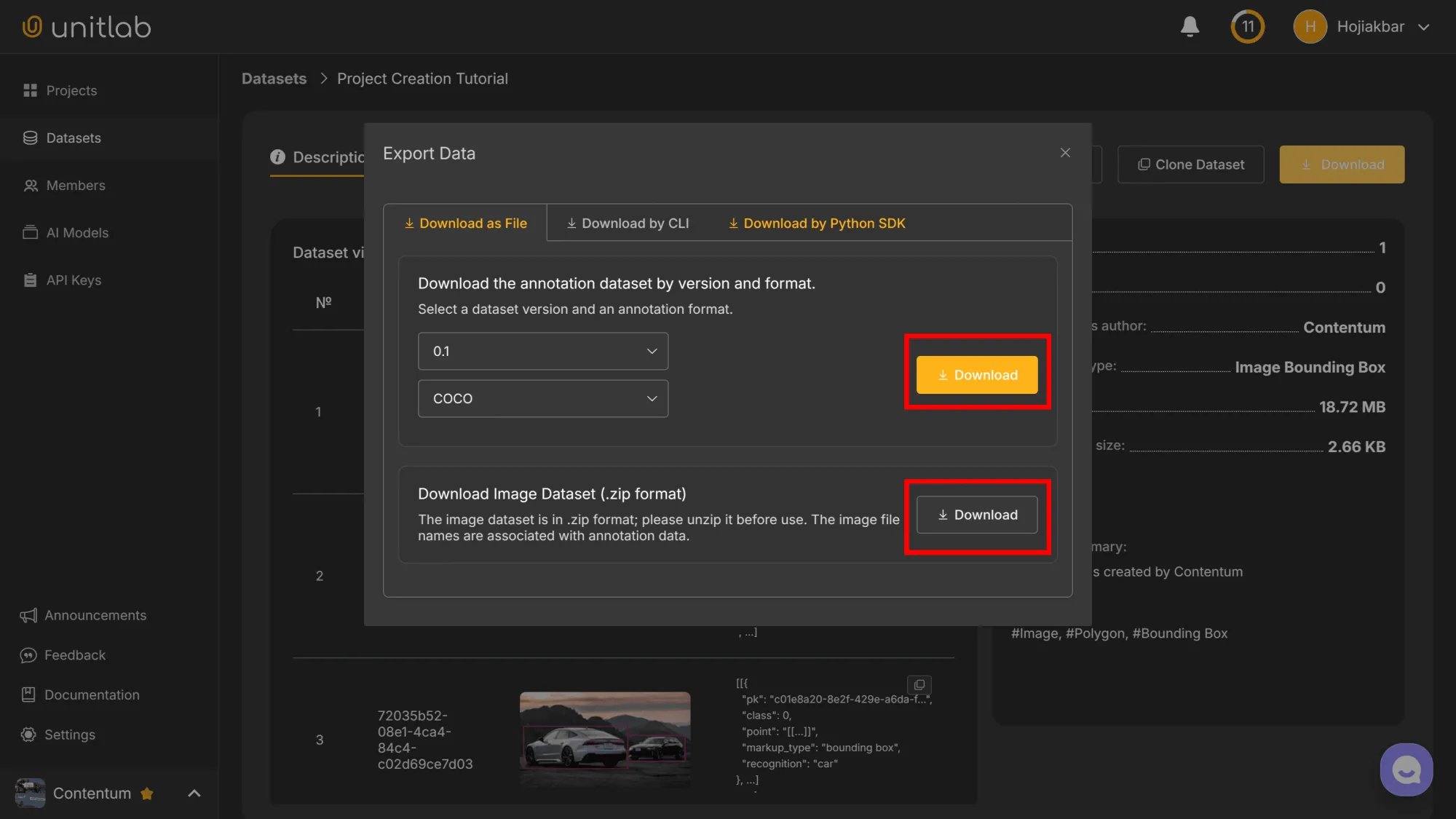
We have three options to download the results:
- Web interface: the standard browser functionality.
- Unitlab CLI: the command-line interface.
- Python package: the
unitlabPython package.
The CLI and Python SDK | Unitlab Annotate
For this tutorial, we’ll use the first and simplest option, the web browser.
Dataset Clone and Version Control
In Unitlab Annotate, users can clone public datasets and start working with the dataset. There are numerous public official and user-created datasets available at our data labeling platform. You can clone a dataset as follows:
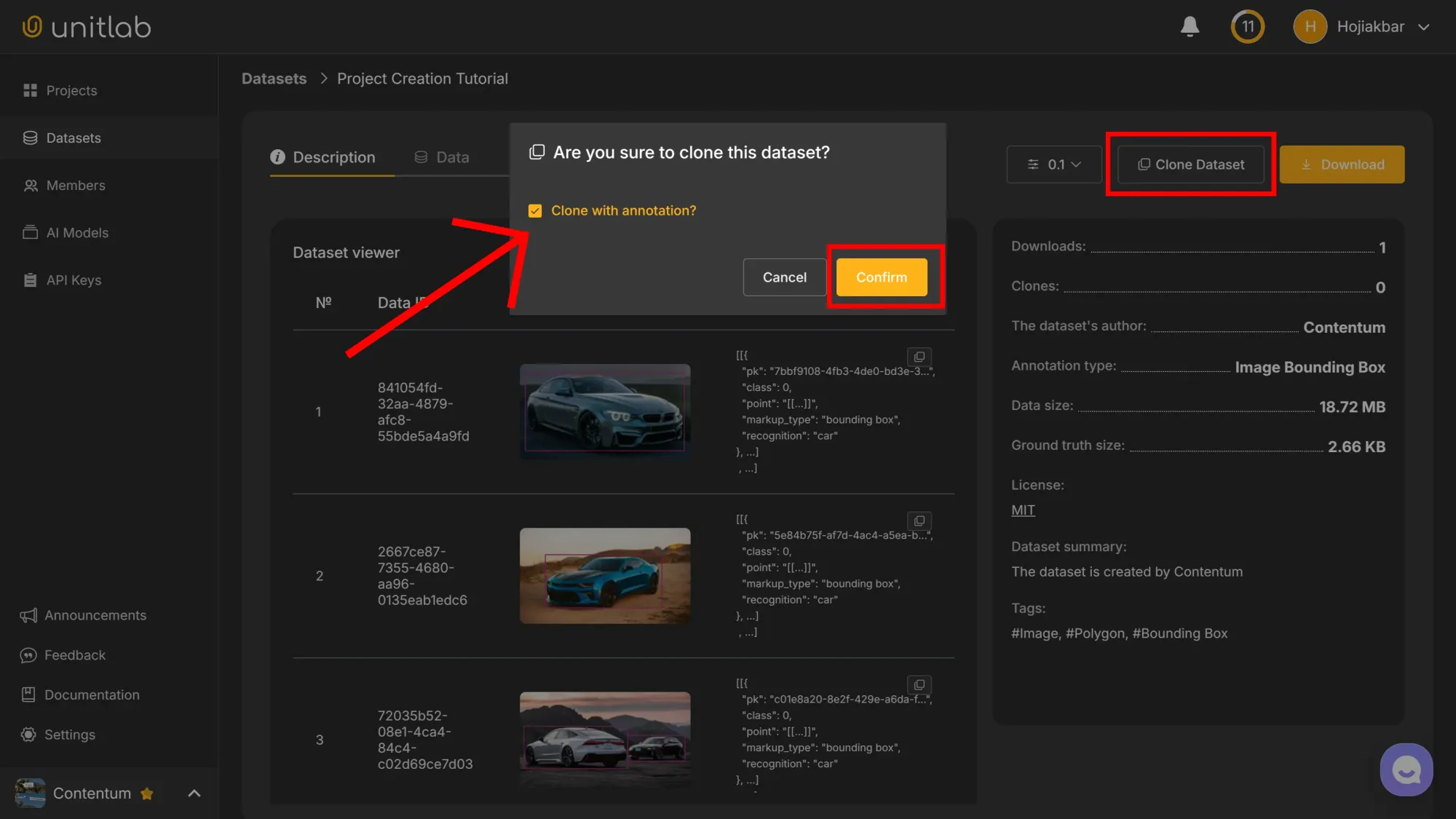
If we clone with the annotations, our project contains all the image annotations in addition to the source images. Otherwise, we only clone the source images. The rest will continue in the same way as creating a project.
Conclusion
Unitlab’s version-controlled dataset management ensures that data remains consistent and accessible throughout the project. Whether the goal is to build an AI/ML model, collaborate with a team, or share work publicly, the platform provides a smooth, reliable way to manage and release datasets.
With options for tracking changes, selecting licenses, and flexible download methods, Unitlab Annotate makes it easy to create structured, reproducible datasets for any purpose.
By keeping datasets organized and up to date, projects benefit from improved collaboration, reduced errors, and better AI performance.

