

The first fact of life: things are vastly different at scale.
This principle holds true across nearly every industry, construction, retail, logistics, manufacturing, and services. Constructing a small housing project in a suburban area is a relatively contained task. By contrast, building a megastructure like the Burj Khalifa demands vastly more planning, coordination, and technical complexity.
Similarly, while local governments may fund road upgrades, international infrastructure programs like the New Silk Road operate at an entirely different magnitude of scale and challenge.
In software, this difference is just as stark. A developer can build a blog over the weekend, but creating and maintaining a production-ready, revenue-generating platform requires a dedicated team, investment, infrastructure, and time.

Guidelines, processes, and assumptions all shift with scale. As projects grow in size and complexity, so does the number of components and their interdependencies. For instance, consider Instagram’s evolution from a three-engineer startup in 2011:
Laws, guidelines, and best practices change at scale. As the projects increase in size and complexity, each component tends to increase as well, resulting in exponential complexity. For example, take Instagram's scaling story with just 3 engineers in 2011 and look at this diagram:
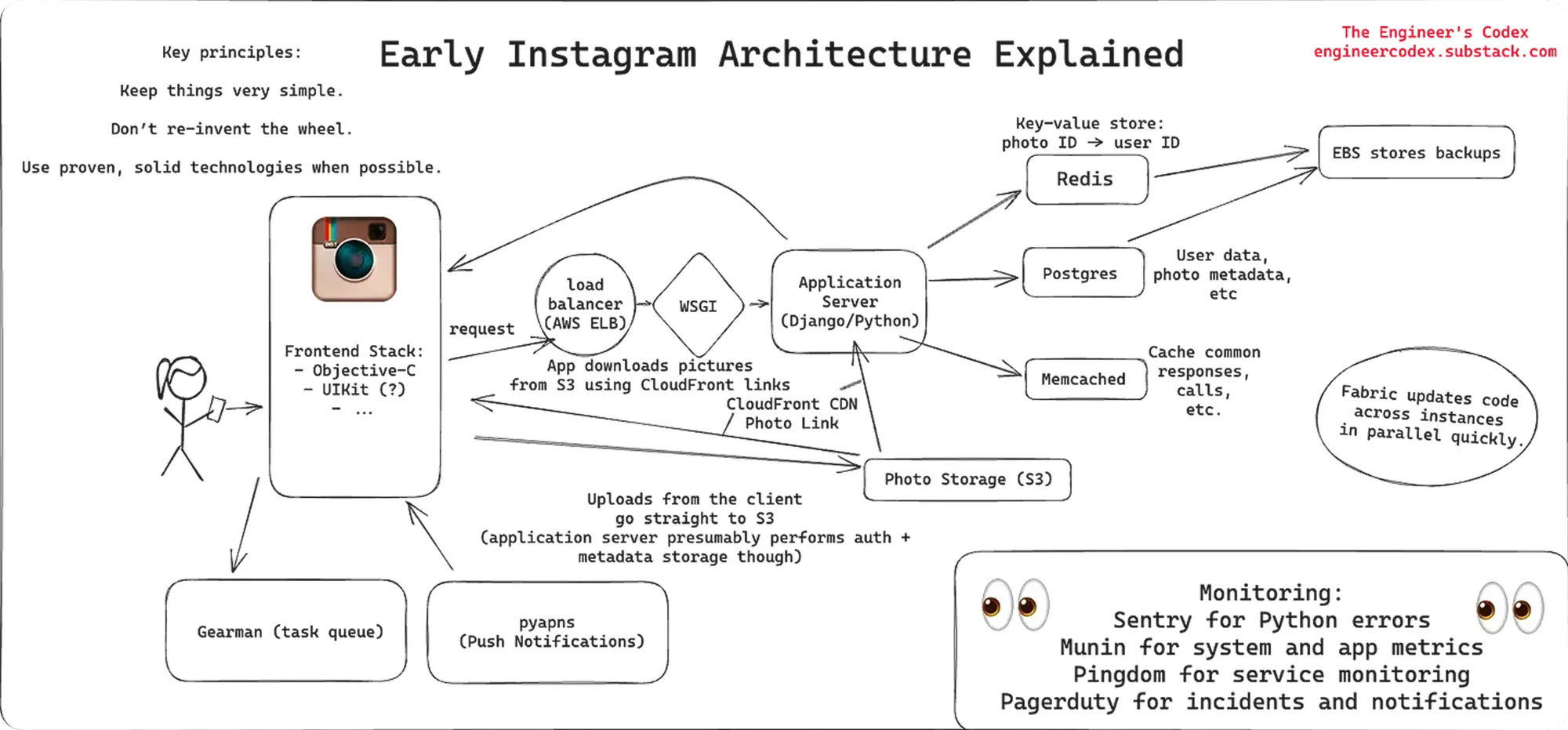
One does not have to be a software engineer to see a complex web of interconnected services. In systems like these, even a single point of failure can cascade, causing widespread service disruptions both for the company and users alike. The bigger they are, the harder they fall.
Today, Instagram supports over 2 billion users globally across four official platforms (mobile, web, desktop, and lite), with continuous user interaction and updates. Its scaling challenges now extend far beyond technology into hiring and managing global teams, compliance, financial operations, and organizational structure.
In this post, we explore how similar scaling dynamics apply to artificial intelligence (AI), particularly in one of its most resource-intensive stages: data annotation.
Scaling in AI
Developing robust AI models requires vast quantities of data. A commonly cited rule of thumb suggests that a training dataset should contain at least ten times more samples than the number of model parameters. In the case of large language models (LLMs) and generative AI systems, this volume becomes particularly pronounced. Take a look at this GenAI development cycle:
While large-scale data collection is technically feasible (typically accomplished through web scraping and distributed data gathering) it raises serious ethical and legal questions, as seen in The New York Times v. OpenAI. The goal is to gather inclusive, representative data that generalizes well across use cases, without introducing noise, hallucinations, or unintended biases:
The data collected often reaches terabyte-scale, necessitating strong engineering practices to store, analyze, and clean it effectively. Yet among all stages of the machine learning pipeline, data annotation is frequently the most time-consuming and operationally complex.
Manual annotation of such large volumes is infeasible. On the other hand, fully automated labeling tools often lack the domain-specific nuance required for high-quality results. A practical solution involves human-in-the-loop approaches, where AI tools assist in annotation while human reviewers validate and correct the output.
Even within this hybrid setup, many critical, micro-level operational questions arise:
- Should data labeling be outsourced or managed in-house?
- How can teams ensure labeled dataset consistency and accuracy?
- What’s the best way to version control datasets as the project evolves in our case?
- And many others.
We did not even touch the business part, which has its own scaling issues.
Training and evaluation loops in AI are inherently iterative. Each stage must be repeated at greater scale and with increasing precision, compounding the complexity of the annotation process.
Scaling Data Annotation
Fortunately, machine learning development is inherently incremental; projects can scale annotation operations gradually as demand grows.
For many teams, data annotation is the most labor-intensive part of AI development. This has led to the rise of numerous data annotation platforms over the past decade, particularly in the last five years. While their capabilities vary, organizations seeking enterprise-grade infrastructure may consider robust solutions such as Scale AI or SuperAnnotate. These tools offer extensive automation, collaboration, and quality control features but often at a high cost.
Smaller teams and research groups may find that lightweight platforms are more than sufficient for pilot projects, proofs of concept, or demos. Data labeling capacity can then be expanded incrementally as project requirements evolve.
One unifying principle across scalable annotation efforts is the use of AI-powered tooling to enhance, not replace, human annotators with superpowers. These systems offer pre-labeling, pattern recognition, and model-based suggestions, dramatically increasing throughput. With proper implementation, such workflows can achieve high-quality results at a fraction of the manual effort.
To illustrate how auto-annotation works in practice, consider three features for image labeling, available in Unitlab Annotate, a fully automated data annotation platform. Similar capabilities exist in other vendors, depending on the data modality (text, audio, or video):
- Batch Auto-annotation: Enables high-volume annotation across datasets using consistent templates or pre-trained models
Batch Fashion Segmentation Auto-annotation | Unitlab Annotate
- Crop Auto-annotation: Automatically detects and labels object instances within an image.
Crop Fashion Auto-annotation | Unitlab Annotate
- SAM Annotation: Uses Meta’s Segment Anything Model to label objects at the pixel level with minimal input.
Medical Image Labeling with SAM | Unitlab Annotate
Used effectively, AI-powered auto-annotation tools allow teams to significantly reduce manual workload without compromising precision or dataset integrity.
Conclusion
Things are vastly different at scale. Operating at scale introduces new dimensions of technical, operational, and strategic complexity. Whether in infrastructure, software, or machine learning, the transition from small to large systems demands new tools, new mindsets, and new forms of collaboration.
Artificial intelligence is no exception. Every phase (from data collection to annotation, training, validation, and deployment) must be reimagined as projects grow. And among these, data annotation remains one of the most resource-intensive and critical components.
Organizations that succeed in large-scale annotation efforts do so by combining automation with expert oversight. This is not a matter of replacing people with machines, but of augmenting their capabilities, an idea Peter Thiel championed in Zero to One more than a decade ago. In scalable AI, the future lies not in man versus machine, but in man plus machine.
Explore More
For additional insights into data annotation:
- Data Annotation: To Outsource or Not? [Updated 2026]
- Four Essential Aspects of Data Annotation [2026]
- Unitlab Annotate - Data Annotation Platform for Computer Vision
References
- Bhavik Sarkhedi (Sep 12, 2024). Best Practices for Scaling Data Annotation Projects in 2024. Content Whale: Source
- Michael Abramov (Nov 10, 2022). The Challenges of Large Scale Data Annotation. Keymakr Blog: Source
- Sigma AI (no date). Best practices to scale human data annotation for large datasets. Scale AI: Source

![Understanding ML Bias in AI Models [2026]](/content/images/size/w360/2025/12/bias-1.png)
{kind=link}