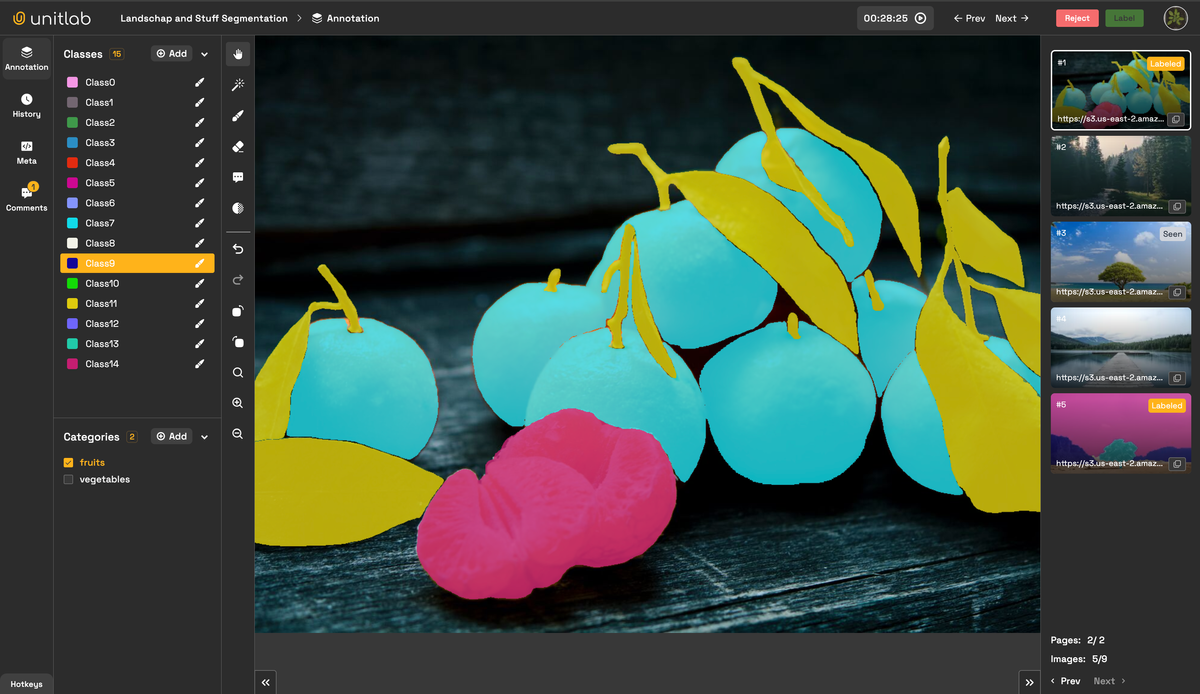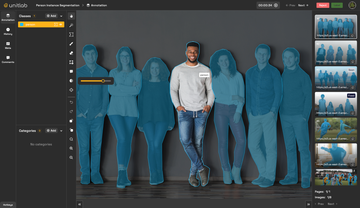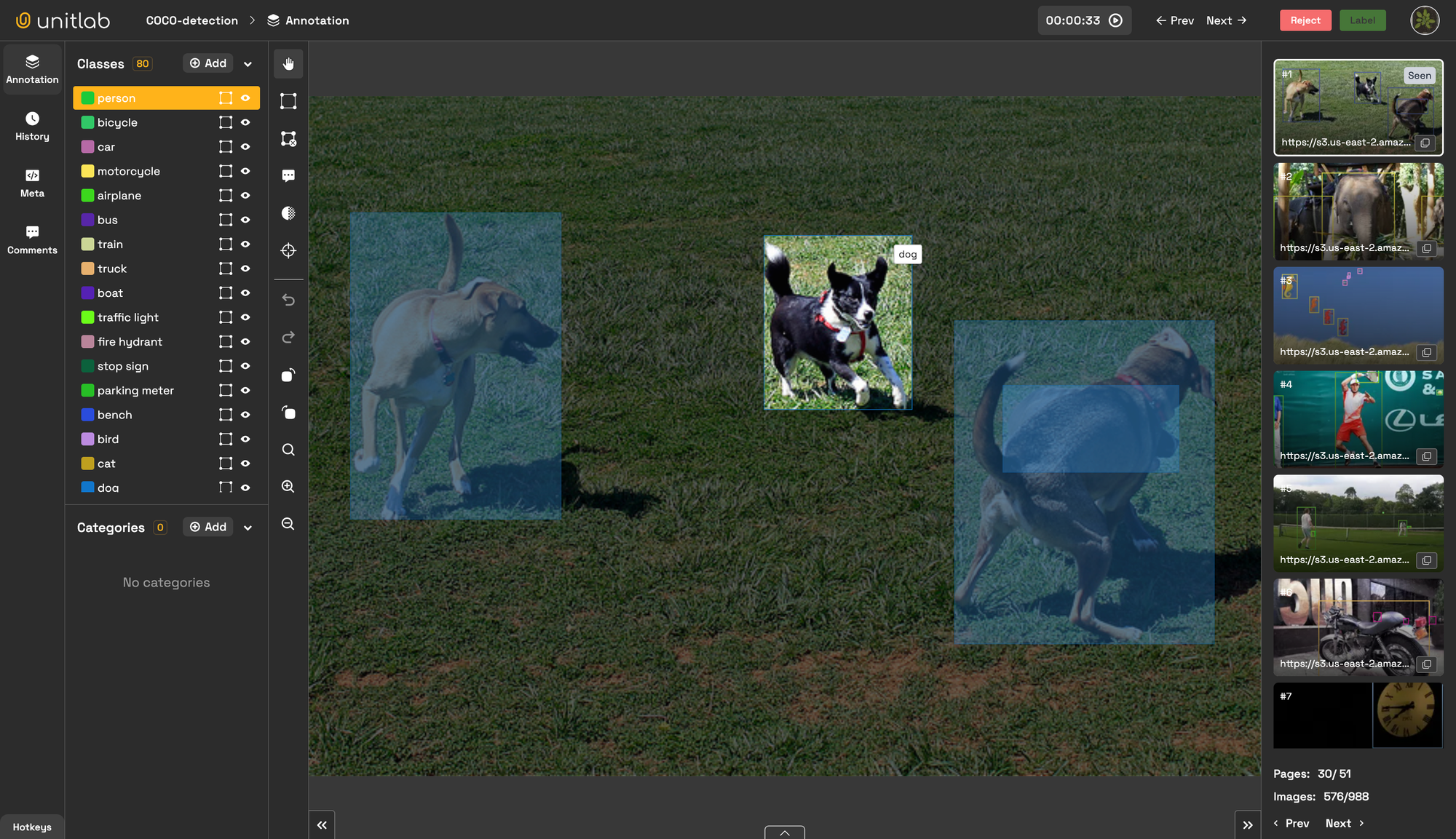
Developing an Artificial Intelligence (AI) or Machine Learning (ML) model that accurately simulates human behavior requires comprehensive training datasets. Data annotation is the process of labeling or tagging data, creates training datasets for ML models. This step is crucial for the development and improvement of AI and ML models, as they learn from these datasets. The quality and accuracy of data annotation directly impact the performance of AI models, making it a vital step in the development of intelligent systems.
Data Annotation Types
- Text Annotation: Involves labeling or categorizing text data for natural language processing (NLP) applications. This can include sentiment analysis, entity recognition, and part-of-speech tagging.
- Image Annotation: Image annotation involves annotating bounding boxes to identify objects, features, or areas of interest. This is essential for computer vision applications, such as object detection and recognition, OCR, autonomous vehicles, and medical imaging analysis.
- Video Annotation: Similar to image annotation but applied to video sequences. It involves tagging objects, actions, or events over time, crucial for surveillance, activity recognition, and sports analytics.
- Audio Annotation: Involves transcribing or tagging audio data, including speech, music, or environmental sounds. The audio annotation datasets are used for speech recognition, music recommendation, and sound classification in AI applications.
- Semantic Annotation: Assigning meanings to certain parts of the data (e.g., linking entities in a text to their real-world counterparts), crucial for search engines, recommendation systems, and knowledge graphs.
Methods of Data Annotation
- Manual Annotation: Performed by human annotators, ensuring high accuracy but can be time-consuming and costly.
- Semi-Automated Annotation: Combines machine learning algorithms with human oversight, where AI suggests annotations that are reviewed and corrected by humans.
- Automated Annotation: Uses group of pre-trained Models to annotate data fully and human in the loop in the monitoring and reviewing.
- Fully Automated Annotation: Uses batch data auto-annotation through one or a group of "expert" pre-trained models for a specific domain. The model continuously improves in the loop with newly generated data. This system operates automatically; no human intervention is required.
The Use Case of Data Annotation
- Model Training: Annotated data is used to train AI models.
- Model Evaluation: Annotated data is also split for test purposes, allowing the evaluation of AI model performance, which helps AI engineers understand the strengths and weakneses of the models.
- Improving Model Accuracy: Through iterative training and re-annotation, the accuracy and reliability of AI models can be significantly improved.
Challenges of Data Annotation
Despite its importance, data annotation faces several challenges. These include the high cost and time required for manual annotation, ensuring the quality and consistency of annotations, and the need for domain-specific knowledge for certain types of data. Additionally, maintaining privacy and ethical standards, especially when dealing with sensitive data, is a critical concern.
Data annotation is a foundational element in the field of artificial intelligence. It enables the development of sophisticated and accurate AI models by providing them with the high-quality, labeled data they need to learn and make decisions.
What Can Unitlab Do for You?
Unitlab Annotate is an AI-driven collaborative data annotation platform, offering on-premises solutions and integrated labeling services. It automatically collects raw data and enables collaboration with human annotators to produce highly accurate labels for machine learning models. Unitlab Annotate is designed to optimize data annotation work efficiency, control annotation quality, and minimize costs.


 Shohrukh Bekmirzaev
Shohrukh Bekmirzaev Shohrukh Bekmirzaev
Shohrukh Bekmirzaev Shohrukh Bekmirzaev
Shohrukh Bekmirzaev