Robots have existed as a concept, academic subject, and industrial automation tool for decades now.
A robot is a machine (especially one programmable by a computer) capable of carrying out a complex series of actions automatically. Traditionally, robots were created with very specific purposes in mind, so they didn’t always look like the humanoid robots we tend to associate them with.
With the rise of computer vision, ML, and computing power over the last two decades, autonomous robotics has seen impressive results as well: from Big Dog for the military to Amazon's inventory robots like Hercules to humanoid, athletic Atlas from Boston Dynamics.
Atlas even surpasses most humans in selected physical activities (like doing a backflip). What percentage of humans do you think can do a perfect backflip? Less than 1%.

In this article, we’ll cover robotics in general and focus on how computer vision allows robots to observe, interpret, and interact with the world independently.
Let's dive in.
Modern Robotics
First, let’s make this point clear: robots have existed for a long time in factories to automate manufacturing. There are even some economic arguments about how automation was responsible for 87% of the job losses in American manufacturing at the end of the 20th century.
Engineers were creating all sorts of robots that could also be controlled remotely. A notable example is the first rover on the Moon, Lunokhod 1, which was controlled from Earth with a 2-second latency.

They are still primarily used in factories or places humans cannot reach.
These robots work in a static world where code is rigid, situations are exact, and green is greener.
The robots we are about to discuss are agents that can act, interact, and decide independently. They can learn and adapt. They can perceive new visual and audio information, not only pre-trained data.
Computer vision plays a great role in making such robotics possible because most of the information we (and robots) receive is visual.
What makes robotics different in the case of Vision AI is that robots are not usually fixed in one place and have a physical body, meaning they can move and operate. Mechanics aside, this adds another layer of complexity when applying computer vision in robotics (like 3D cameras and edge computing).
Computer Vision in Robotics
Computer vision gives robots the ability to perceive and interpret their surroundings. By combining visual data with deep learning, robots can detect, classify, and interact with objects. This shift moves robotics beyond predefined rules and into adaptive, data-driven decision-making.
Specifically, machine vision in robotics refers to using cameras and AI models to enable visual perception. The process starts with image or video frame capture, followed by interpretation through algorithms that analyze shapes, depth, colors, textures, and movement.

In a nutshell, machine vision does for machines what our eyes do for us humans. We receive visual data through our eyes, process it through our sensors, and our brain makes decisions based on it in a split second.
At a high level, this is how robots utilize computer vision in their operations:
- Perception: capturing visual input through 3D RGB, stereo, or depth cameras
- Processing: running convolutional neural networks (CNNs) to extract features
- Decision-making: applying insights to perform actions such as grasping or navigating
Unlike traditional static robots that depend on fixed instructions, vision-based dynamic robots can learn from their environment, adapt to new conditions, and perform complex tasks autonomously.
This is what makes them such a potential game changer for the future.
Core Components
When you look at how machine vision powers robotics, three major components stand out. They roughly correspond to the perception, processing, and decision-making phases described above.
Cameras & Sensors
These can be roughly equated to human eyes.
- Robots rely on input hardware to “see.” Most robots operate on a physical plane, so 3D stereo and depth cameras and LiDAR (Light Detection and Ranging) are commonly used.
- The quality of input affects the outcome. Low resolution, slow frame rates, or poor placement affect performance negatively.
- The choice of sensor depends on the task: a robot driving carts in an Amazon warehouse may only need a 2D RGB camera, while an autonomous Tesla car definitely needs depth/stereo cameras and LiDAR.
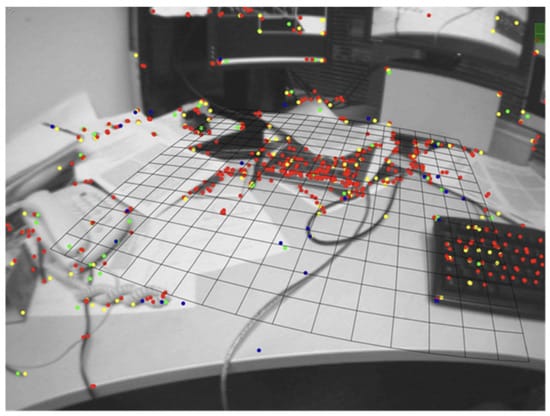
SLAM (Simultaneous Localization and Mapping)
One fundamental challenge for modern robots is navigating a new environment while tracking their own location at the same time. If GPS is available, great, but most of the time it isn’t (think of rooms or corridors a robot needs to navigate).
In extreme cases, the robot might literally be on Mars, where GPS is not available. The Perseverance rover used stereo cameras (dual cameras) to map its environment and track its location.
SLAM is the process that robots use to address this problem. Our sense of physical direction is a rough analog to SLAM.
- SLAM enables the robot to build and update a map of its environment while tracking its own position.
- It’s especially critical for mobile robots (drones, AGVs) that must navigate dynamic spaces.
- Integrating SLAM with vision allows robots to adapt when the environment changes (new obstacles, moving objects).
Machine Learning & Deep Learning Models
Once visual data is processed into structured data machines can understand, ML models make decisions, such as turning left on a green light after ensuring there’s no car or pedestrian.
- Once data is captured, models like convolutional neural networks (CNNs) process the visuals and extract meaning.
- These models power tasks like object detection, classification, and segmentation.
- For robotics applications, you often train custom models that match the operational tasks (e.g., detect a handle, identify a human, classify a defect).
Together these core components form the backbone of vision-enabled robotics. They must work in harmony: hardware must capture precise data, and models must interpret it correctly.
Core Capabilities
With these core hardware and software components, robots evolve from fixed, static machines to dynamic agents with advanced capabilities:
- Object Detection and Tracking: identifying and following objects in real time, useful in sorting, assembly, and pick-and-place operations.
- Segmentation: differentiating between regions of interest and background to locate object boundaries accurately.
- Pose Estimation: understanding object orientation and position to support manipulation tasks.
- Depth Perception: using stereo or LiDAR data to estimate distance and avoid obstacles.
- Anomaly Detection: identifying defects or irregularities in industrial inspection.
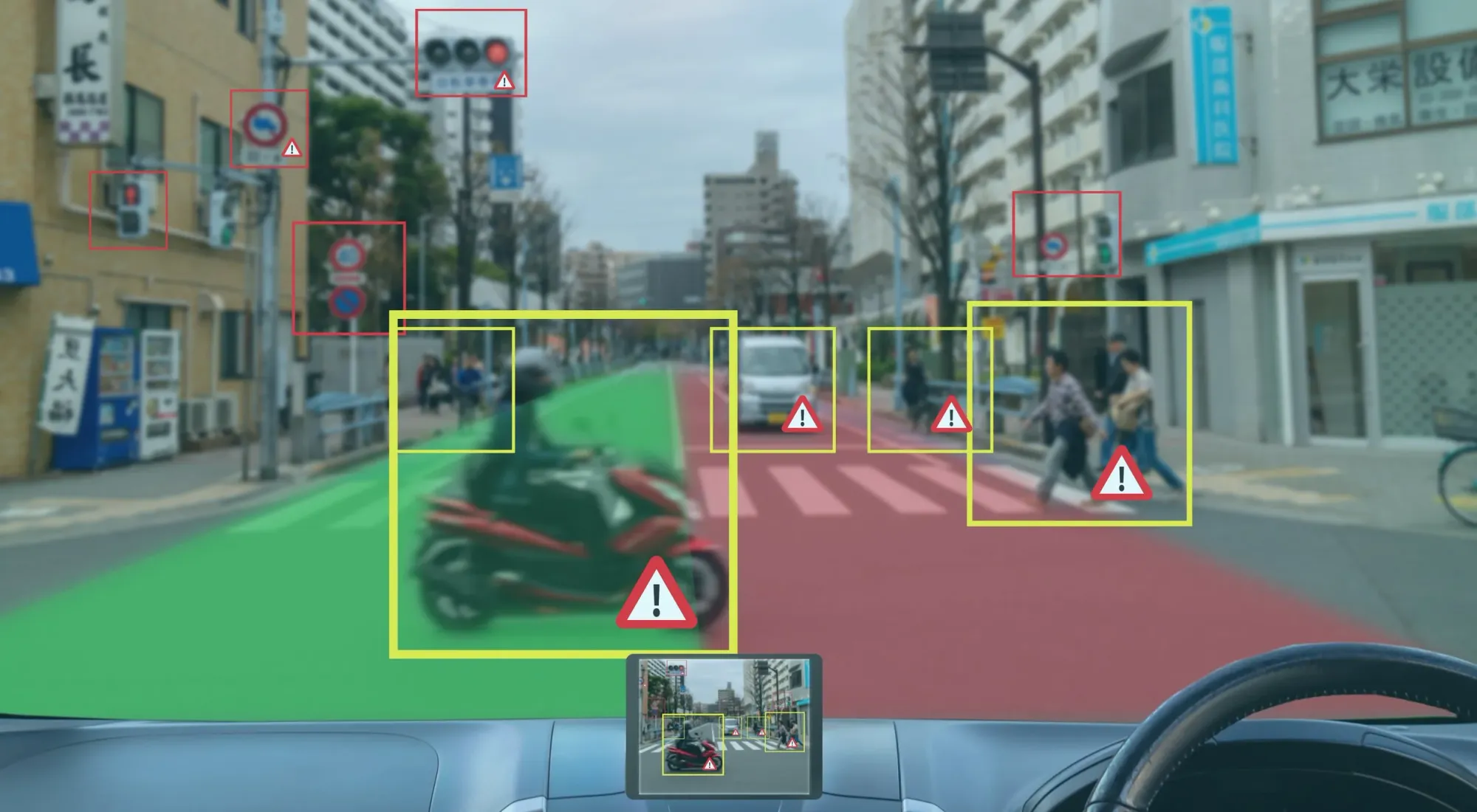
These abilities transform visual inputs into structured understanding, allowing robots to make intelligent decisions within dynamic environments.
Once a relevant aspect is successfully integrated into the “brain” of a robot, the next step involves mechanics: building physical body parts to execute the orders given by the CPU.
Data Annotation and Model Training
Before going further, let’s review one crucial aspect of implementing computer vision in robotics: data annotation.
Even the most mechanically advanced robots are of little use if they lack a powerful brain. To develop such a brain, we need data, lots of it. Not just any data, but meticulously prepared training data.
High-quality labeled datasets are essential for training vision models that power robotics. Each image or video frame must be annotated to help models recognize specific patterns or objects.
Key annotation types include:
- Bounding boxes for object detection
- LiDAR for mapping and depth measurement
- Polygons for segmentation
- Keypoints for pose estimation
Unitlab Annotate offers an AI-powered, automated data annotation platform to label raw visual, audio, and text data efficiently and effectively. We provide a freemium model to get you started in five minutes. Try Unitlab for your robotics project.
Once annotated, datasets train neural networks that improve through continuous feedback. This loop (data, training, validation, and retraining) drives accuracy and generalization across tasks in robotics.
Real-World Applications
Advanced computer vision, AI, and hardware are proving highly valuable across diverse industries, even in areas you might not expect:
- Military: Historically, new technology was first used for defense and military purposes (the Internet and drones included). Robots now see increasing use for military applications. Notable examples include unmanned aerial vehicles (drones). Robots can also detect and remove landmines. Researchers have developed a model that can detect mines with a whooping 99.6% accuracy.
- Warehouse: Amazon utilizes more than a million robots of ten different kinds across its giant warehouses worldwide. That number alone is mind-blowing.
- Autonomous Systems: Your favorite self-driving car fits here. This concept extends beyond cars or trucks; any independent system that interprets its environment, acts on it, and learns from it is considered an autonomous system.

Why care about robots? Because they provide concrete, measurable, and significant benefits to humans. This may come from operational efficiency (Amazon’s warehouse robots), defense and security (military drones and robots), or safer and more comfortable driving experiences (Waymo, Tesla).
However, there’s more to modern robots with computer vision.
Challenges and Future Outlook
Like anything worth creating, intelligent robots equipped with “eyes” aren’t easy to build.
Despite rapid progress in AI, machine vision, mechanics, and robotics, several challenges remain:
- Cost: Modern robots are still expensive; they aren’t yet mass-produced since many are still in prototype phases. This Spot robot dog by Boston Dynamics costs $75,000, for instance.
- Safety: Tesla reports “one crash for every 6.36 million miles driven in which drivers were using Autopilot technology,” compared to one crash per 993,000 miles without Autopilot. Still, robotics hasn’t yet reached a point where it can be considered foolproof.
- Data quality and diversity: The universal problem across ML and AI models. Garbage in, Garbage out.
- Domain adaptation: Not all models generalize beyond their training data. These models sometimes need retraining under different conditions.
- Real-time inference: Edge computers (installed directly in robots) have storage and processing limitations, just like any other computer. A self-driving Waymo can generate up to 20 terabytes of data in a single day. For comparison, iPhone 17 Pro Max has a maximum of 2 TB of storage.
Additionally, the hardware part of robotics is an entirely different challenge of its own. To illustrate, consider this problem stated by an AI researcher:
Until dynamics is deeply incorporated in machine learning models, they will remain “statistical machines” that “statistically work” which is not enough for a real world application such as robotics.
So, what is the future of robotics? For sure, no one can know for sure. We can’t make definite statements because of the pace and breadth of change. The purpose of tech pundits is to make astrologers look good.
However, we can say that the future lies in embodied AI-robots that integrate vision, touch, and reasoning. As models evolve, robots will gain better scene understanding, allowing seamless interaction with humans and unpredictable environments.
Conclusion
Computer vision enables robots to see, understand, and act. It turns passive automation into intelligent autonomy.
Machine vision is analogous to human perception: cameras and sensors for eyes, image processors for human brain sensors, and ML models for brain decision-making neurons.
These components enable mechanical robots to recognize objects, pick up items, follow trajectories, and execute delicate tasks.
However, it is the brain of the robot that differentiates it from hard automation. Data annotation, model training, and efficient model deployment are as essential as hardware that goes into the robot.
Robots are an exciting field to be in: a field that receives widespread interest and funding, and is about to explode in the near futures. We now see successful military and industrial cases, as well as promising research.
However, legitimate challenges in robotics exist: costs, safety, regulations, technical limitations. However, as time goes on, robotics is expected to improve over time.
Explore More
Check out these posts to see how computer vision is transforming other industries:
- The Transformative Power of Computer Vision in Logistics
- Practical Computer Vision: Parking Lot Monitoring with a Demo Project
- Automate Inventory Management with Computer Vision – 10× Faster Data Annotation and Collection
References
- Abirami Vina (Aug 30, 2024). Understanding the integration of Computer Vision in robotics. Ultralytics: Source
- Annotera (no date). The Engine of Automation: Data Annotation for Next-Generation Robotics and Manufacturing. Annotera Blog: Source
- Contributing Writer (Oct 31, 2024). Computer Vision Use Cases in Robotics. Roboflow Blog: Source
- Haziqa Sajid (Jan 11, 2024). Top 8 Applications of Computer Vision in Robotics. Encord Blog: Source
- inbolt (no date). Computer Vision in Robotics. inbolt Blog: Source