

Computer vision teaches machines to interpret visual data such as images and videos. At its core, it allows software to see, recognize, and understand the visual world. That definition sounds simple. The real impact comes from what machines can do once they understand images reliably.
Computer vision is now deployed across healthcare, manufacturing, autonomous vehicles, security, and retail. The global computer vision market is projected to reach $58.29 billion by 2030, driven by rapid adoption in automation, analytics, and AI-powered decision systems.

Use Cases of Computer Vision
Retail and e-commerce stand out as one of the most natural fits for computer vision. Retail is inherently visual. Products are visual. Shelves are visual. Customer interactions are visual. Every operational process generates image or video data.
In this post, you will see exactly how computer vision transforms retail and e-commerce systems, and why annotated visual data makes it possible.
Why Computer Vision Matters for Retail
Computer vision enables machines to extract structured information from visual input. Instead of relying on fixed rules, modern systems use deep neural networks trained on labeled datasets. These models learn to recognize objects, classify attributes, detect patterns, and interpret scenes. This allows machines to perform tasks that previously required human vision.
Retail environments generate massive volumes of visual data every day, including:
- Product images uploaded to online catalogs
- Camera feeds from physical stores
- Warehouse monitoring footage
- User-uploaded product photos
- Receipts, invoices, and shipping labels
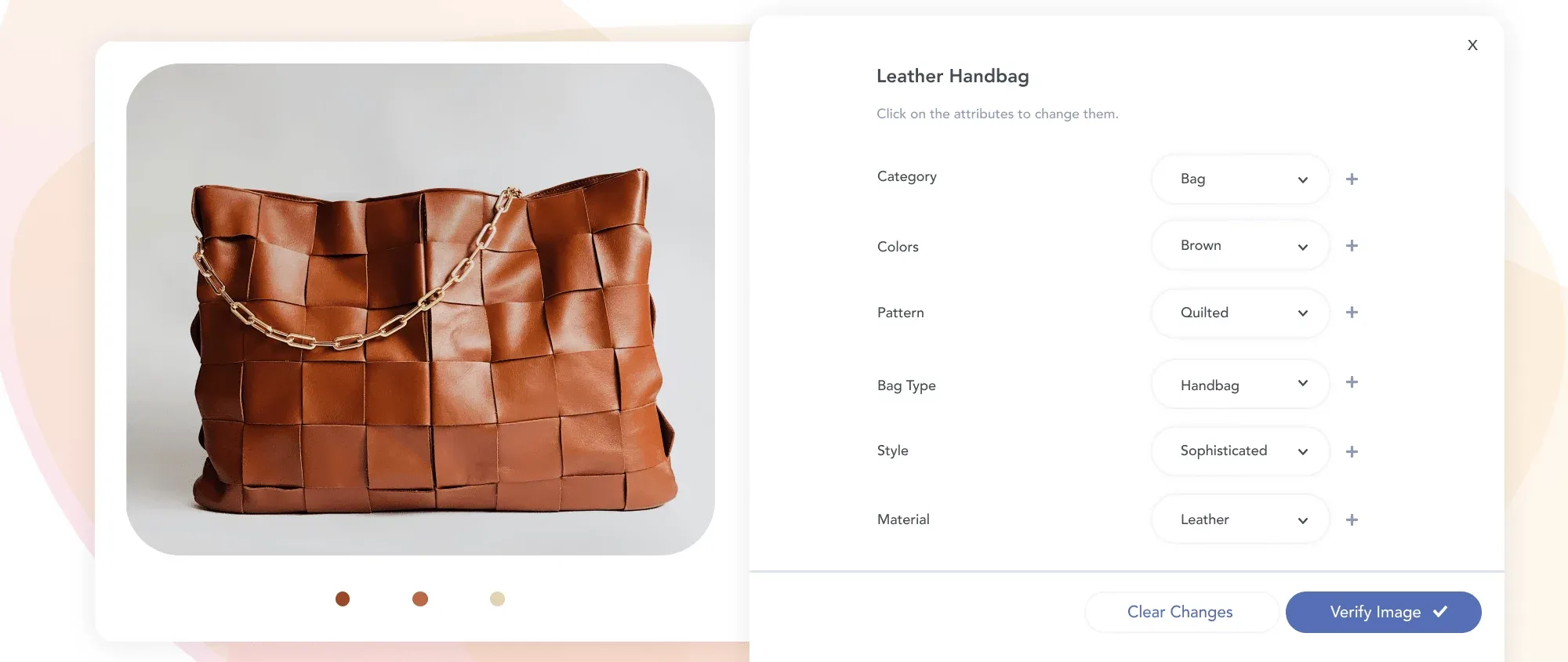
Historically, humans processed this data manually. Staff categorized products, counted inventory, reviewed images, and extracted document information. This approach works at small scale but fails when catalogs contain millions of products and operations run continuously.
This is not experimental technology; it already runs in production systems at global scale. Amazon Go used CV to track products customers pick up, eliminating traditional checkout. Shopify uses image understanding systems to improve product taxonomy, categorization, and search accuracy across millions of listings. Zalando uses CV models to power visual search and automatically extract product attributes such as clothing type.
The underlying capability behind all of these systems is the same. Computer vision converts raw visual input into structured, machine-readable data. Once visual information becomes structured data, software systems can automate decisions, trigger workflows, and operate at scale without human intervention.
Key Applications of Computer Vision in E-Commerce
Here is a summary of key applications:
| # | Use Case | What It Does | Key CV Task(s) | Popular Models |
|---|---|---|---|---|
| 1 | Visual Search | Search by image, not keywords | Feature extraction, similarity search | CLIP, ResNet-50 |
| 2 | Virtual Try-On & AR Shopping | Preview products on yourself before buying | Pose estimation, body/face segmentation | MediaPipe, VITON-HD |
| 3 | Automated Product Cataloging | Auto-tag product attributes from images | Multi-label classification, attribute recognition | EfficientNet, ViT |
| 4 | Inventory Management & Shelf Monitoring | Track stock levels and detect stockouts in real time | Object detection, real-time tracking | YOLO26, Faster R-CNN |
| 5 | Personalization & Recommendations | Recommend products based on visual style preferences | Visual embedding, similarity matching | CLIP, DeepFashion |
| 6 | Content Moderation | Flag inappropriate or counterfeit product images | Image classification, anomaly detection | ResNet, OpenNSFW2 |
| 7 | Customer Behavior Analysis | Track in-store movement, emotions, and product interactions | Multi-object tracking, facial expression recognition | YOLO26 + DeepSORT, OpenPose |
| 8 | OCR for Retail Operations | Extract text from labels, invoices, and price tags | Optical character recognition, document layout analysis | PaddleOCR, TrOCR |
1. Visual Search
Computer vision directly solves one of the most persistent problems in e-commerce: the vocabulary gap. A person may see a pair of shoes on the street and try to search for them using phrases like "black sneakers" or "leather shoes." These descriptions are incomplete: they miss important details such as shape, texture, cut, or design elements.
Traditional text search depends entirely on keywords. If the keywords do not match the product metadata exactly, the engine may fail to return relevant results. Visual search addresses this limitation.
Most production systems use convolutional neural networks or vision transformers to encode images into numerical representations called feature embeddings. These embeddings capture visual characteristics such as shape, texture, color, material, and structural patterns.
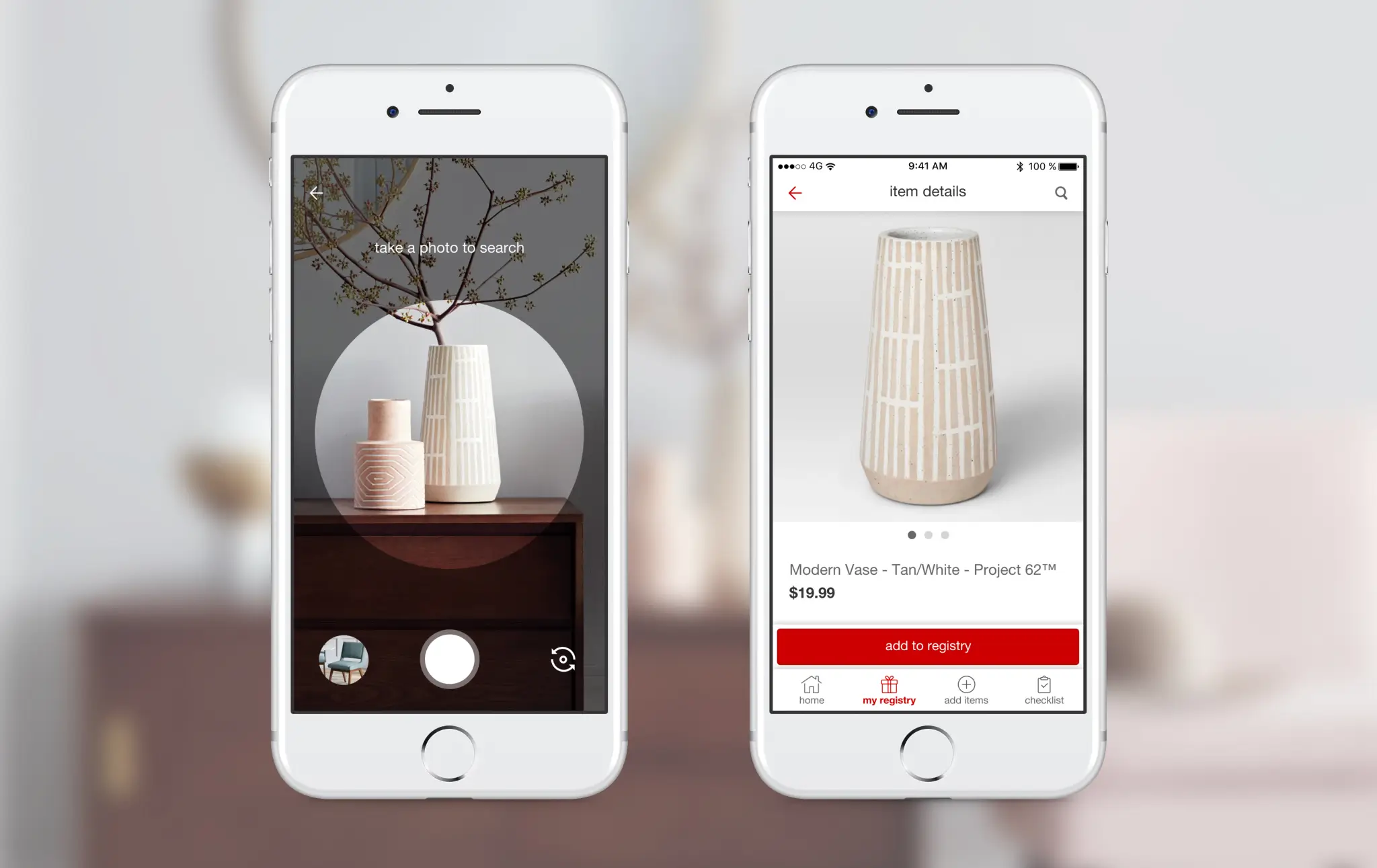
The visual search pipeline typically follows three steps:
- Detect the product or region of interest in the image
- Extract feature embeddings using a trained vision model
- Compare the embedding against product embeddings stored in a database
Major retail platforms already use visual search in production.
Pinterest built Pinterest Lens, which allows users to search using photos and discover visually similar items across billions of images. Amazon developed StyleSnap (Shop The Look), which enables users to upload clothing photos and find matching products instantly.
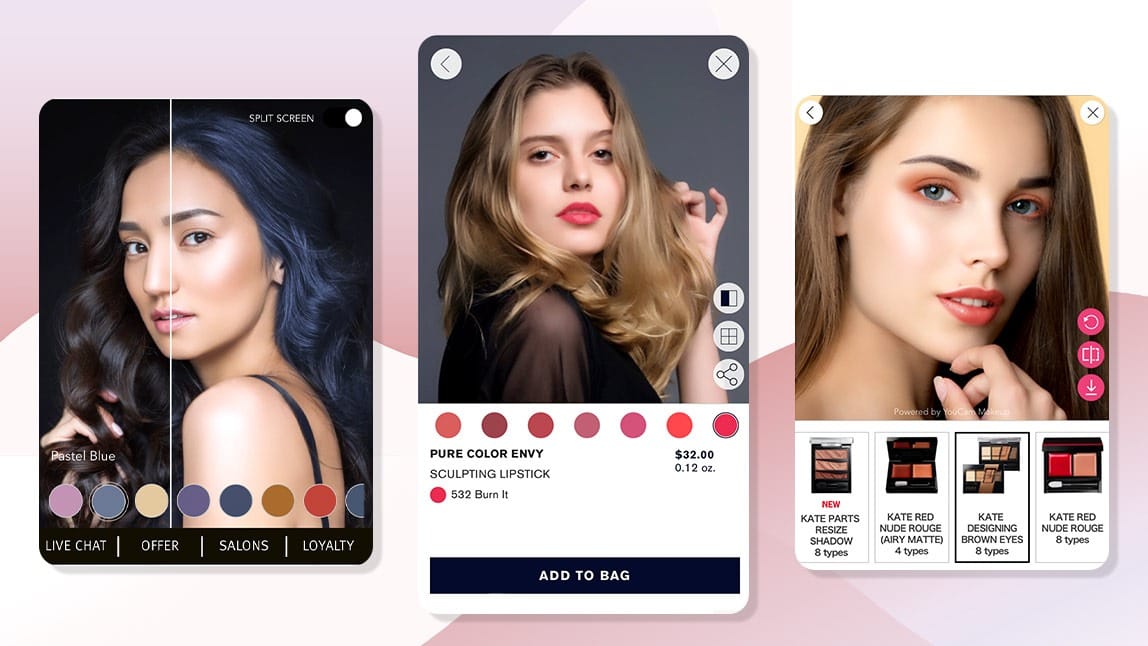
2. Virtual Try-On and AR Shopping Experiences
Customers cannot see how clothing fits their body, how glasses look on their face, or how makeup appears under real lighting conditions. This uncertainty directly affects purchase decisions and increases return rates. Computer vision solves this problem through virtual try-on systems.
These systems rely on several core computer vision techniques. First, the system detects keypoints on the human body or face. These keypoints represent important anatomical landmarks. For facial applications, models detect:
- Eye corners
- Nose position
- Lip boundaries
- Jawline contours

For clothing applications, pose estimation models detect:
- Shoulder positions
- Elbow and wrist joints
- Hip and knee joints
- Body orientation and posture
This allows the system to understand the user's geometry and spatial structure. Next, segmentation models separate the person from the background. This ensures the product is rendered only in relevant regions.
Finally, geometric transformations align the product with the detected keypoints. The system adjusts scale, rotation, and perspective to match the user's pose. This ensures the virtual product moves naturally with the person. For example:
- Glasses remain aligned with the eyes when the user moves their head
- Lipstick follows the shape and movement of the lips
- Shirts adjust to body posture
- Hats align correctly with head orientation
This creates a realistic and interactive preview.

Major retail and technology companies have already deployed virtual try-on systems. Sephora uses computer vision to allow customers to try makeup virtually using facial landmark detection. Warby Parker provides virtual try-on for glasses, enabling users to preview frames using their phone camera. Zalando uses pose estimation models to support virtual clothing previews.
Unitlab AI provides built-in SAM3-powered auto-annotation features to speed up data annotation for your computer vision models. These models include one for fashion segmentation:
Fashion Batch Segmentation | Unitlab AI
3. Automated Product Cataloging & Attribute Tagging
Modern e-commerce platforms operate at a scale where manual catalog management becomes a structural bottleneck. Large marketplaces manage millions of SKUs (Stock Keeping Units), with new products added continuously by internal teams, brands, and third-party sellers. Every product must be categorized, tagged with attributes, and indexed correctly before it becomes searchable.
Instead of relying on manual tagging, image recognition models analyze product images and generate structured metadata automatically. The system extracts semantic information directly from visual features and converts it into machine-readable attributes. This includes:
- Category and subcategory
- Color and shade
- Material type
- Pattern and texture
- Shape and structure
- Style and design features
- Product-specific attributes

For example, when analyzing a clothing item, the system can detect:
- Category: shirt
- Sleeve length: long sleeve
- Collar type: spread collar
- Pattern: striped
- Fit: slim fit
- Material: cotton
Major e-commerce platforms already rely heavily on automated visual cataloging. Amazon uses computer vision to classify and standardize product listings at scale. eBay uses image-based attribute extraction to improve listing accuracy and search relevance.
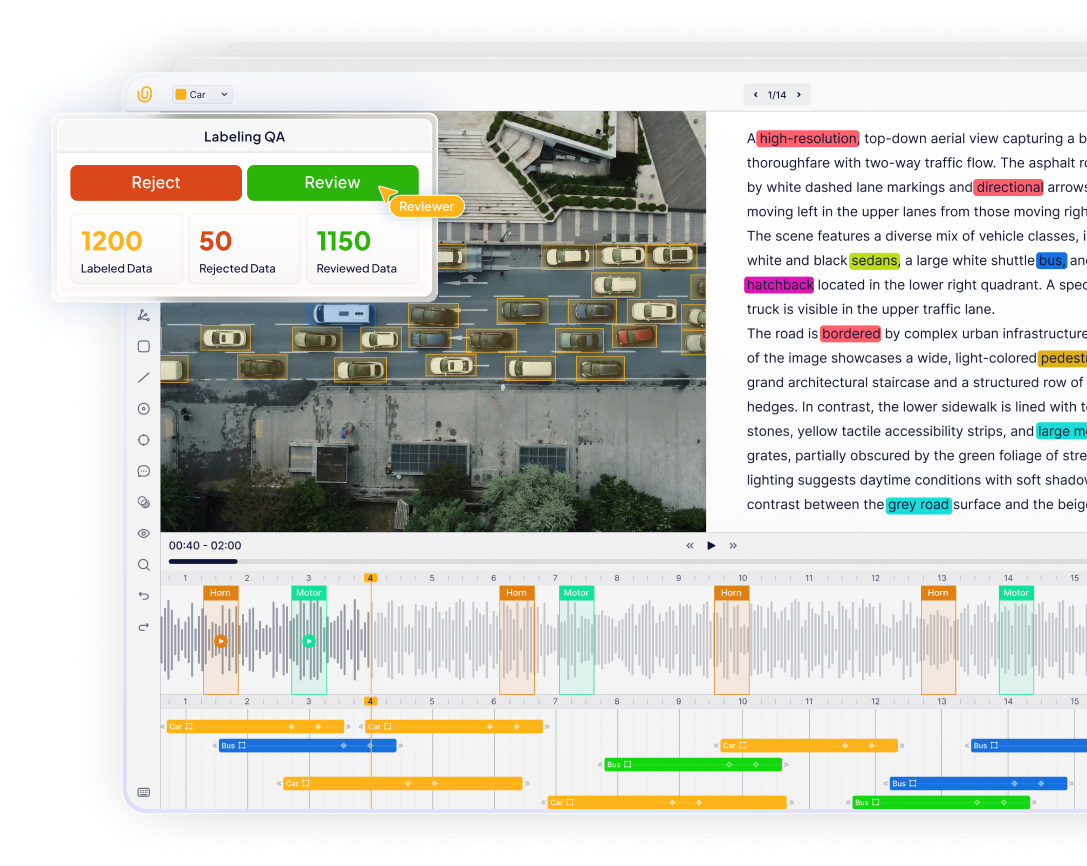
4. Inventory Management & Shelf Monitoring
We have written an entire guide on computer vision for inventory management here:

Inventory Management with Computer Vision
Inventory distortion remains a major financial burden. According to McKinsey, inventory distortion can cost retailers billions annually due to lost sales and excess stock.
Most retailers still rely on cycle counts and point-of-sale records. These methods are periodic and backward-looking. They don’t reflect the actual shelf state in real time. Computer vision changes this by making inventory visible continuously.
Shelf monitoring systems use fixed cameras or mobile robots to capture images of shelves at regular intervals. Object detection models trained on annotated images of specific SKUs analyze these images and count the number of visible units. The system compares this count to the expected planogram and identifies problems instantly.
This enables several critical actions:
- Detect low stock before shelves go empty
- Identify misplaced or incorrectly stocked products
- Trigger replenishment workflows automatically
- Reduce manual shelf inspection by staff
For example, the system might detect that only two units remain when the minimum threshold is five. Staff can restock immediately instead of discovering the issue hours or days later.
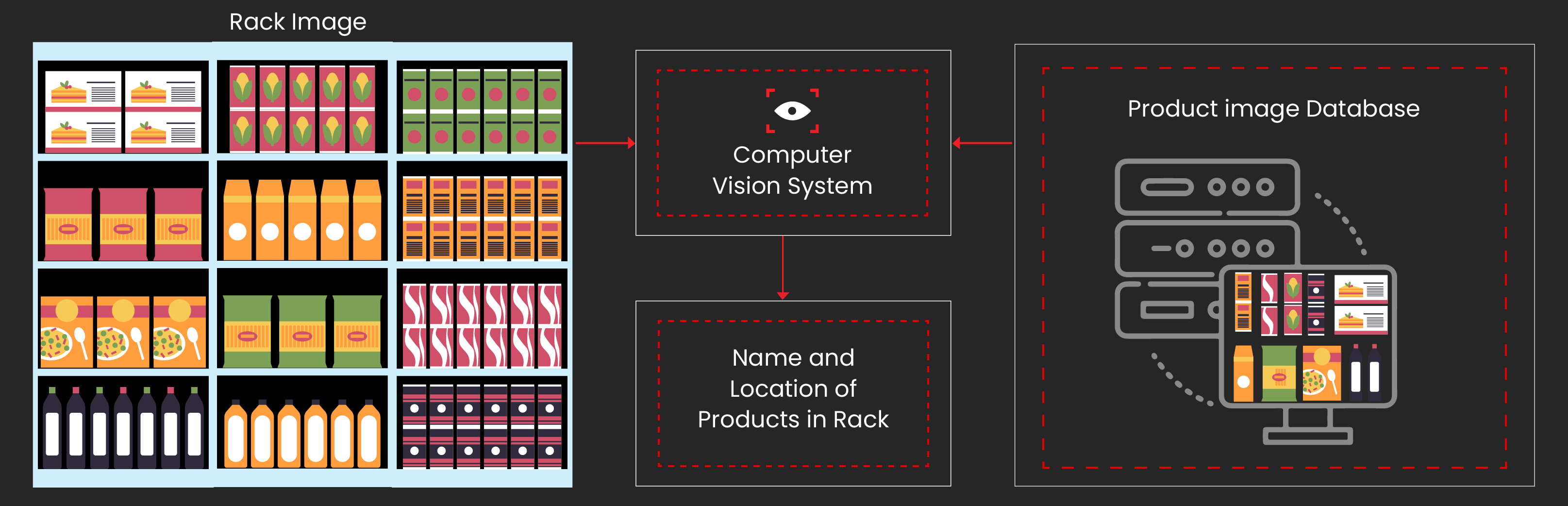
Expiration date monitoring is another high-value use case. OCR models trained on annotated examples of expiration labels can read dates directly from product packaging. This helps retailers:
- Identify products approaching expiration
- Remove expired items quickly
- Maintain compliance with safety regulations
- Reduce labor spent on manual checks
This capability is especially valuable in food retail and pharmacies, where expiration management is critical.
5. Personalization & AI-Powered Recommendations
Most recommendation systems rely on collaborative filtering, which analyzes clicks, purchases, and user similarity. This approach works, but it has clear limits: it can only recommend based on past behavior; it cannot understand visual style; it cannot recommend products the user has never interacted with.
Computer vision addresses these constraints by analyzing the visual content of products directly. Instead of relying only on behavioral data, a computer vision system analyzes product images the user views, saves, or purchases. It learns visual patterns such as:
- Preferred colors
- Silhouettes and shapes
- Materials and textures
- Overall aesthetic consistency
This creates a visual preference profile without requiring explicit input. The system learns what the user likes by observing visual choices.

For example, if a user consistently interacts with neutral colors, clean silhouettes, and minimal designs, the system prioritizes similar visual styles. This works even if the products belong to different categories.
Major platforms like Amazon and Pinterest use computer vision to power visual recommendations and product discovery. Their systems analyze image embeddings to identify visually similar or compatible items.
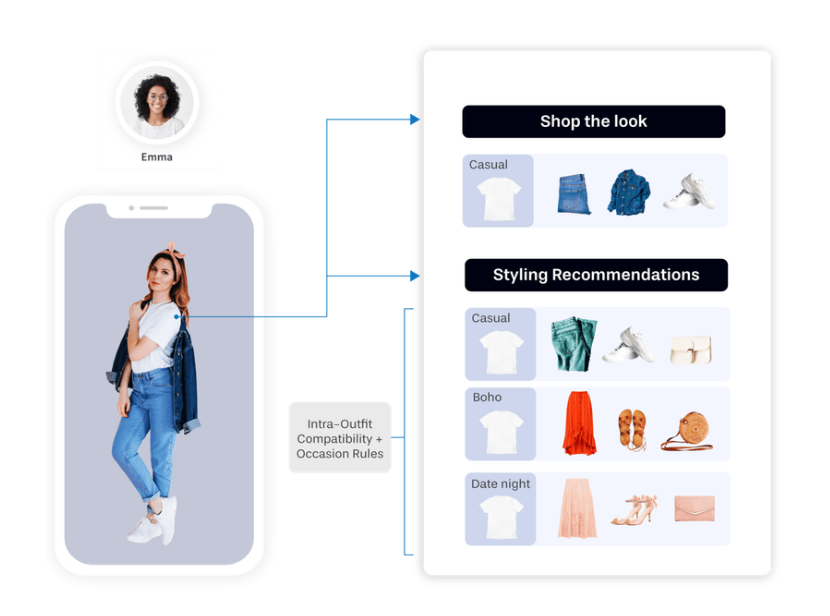
The most advanced systems go beyond similarity. They generate complete outfit recommendations. An outfit generation model analyzes a specific item and understands its visual characteristics through embeddings. It then retrieves complementary products that match stylistically. This process relies on models trained on annotated outfit datasets, where compatibility relationships are explicitly labeled.
This transforms product discovery from reactive to proactive.
6. Content Moderation
Manual content moderation in e-commerce does not scale. Large platforms receive millions of image uploads daily. Human reviewers alone cannot process this volume fast enough. Computer vision provides an automated first layer of moderation and normalization.
Image classification models trained on annotated datasets can detect policy violations automatically. These models analyze uploaded images and identify patterns associated with prohibited or risky content.
This includes detection of:
- Misleading product images
- Counterfeit indicators
- Inappropriate or unsafe imagery
- Personal information such as phone numbers or ID cards
- Policy-violating user-generated photos

The system assigns a confidence score to each image. Based on this score, the platform can automatically reject clear violations, send uncertain cases for human review, approve compliant content instantly. This prioritizes human moderators' time. They focus only on ambiguous or high-risk cases.
Additionally, brand authenticity verification is a critical application within moderation. Computer vision models compare uploaded product images with verified reference images. These models detect subtle differences that indicate counterfeit products, including:
- Logo distortions
- Incorrect fonts or label placement
- Packaging inconsistencies
- Missing or altered brand markers
This sort of verification protects both customers and legitimate sellers.
7. Customer Behavior Analysis (Physical Retail)
Computer vision brings the same behavioral insights that online retailers have long relied on (clickstreams, heatmaps, and funnel tracking into physical stores. Cameras combined with trained CV models capture customer behavior at scale, providing data that manual observation or surveys cannot match.
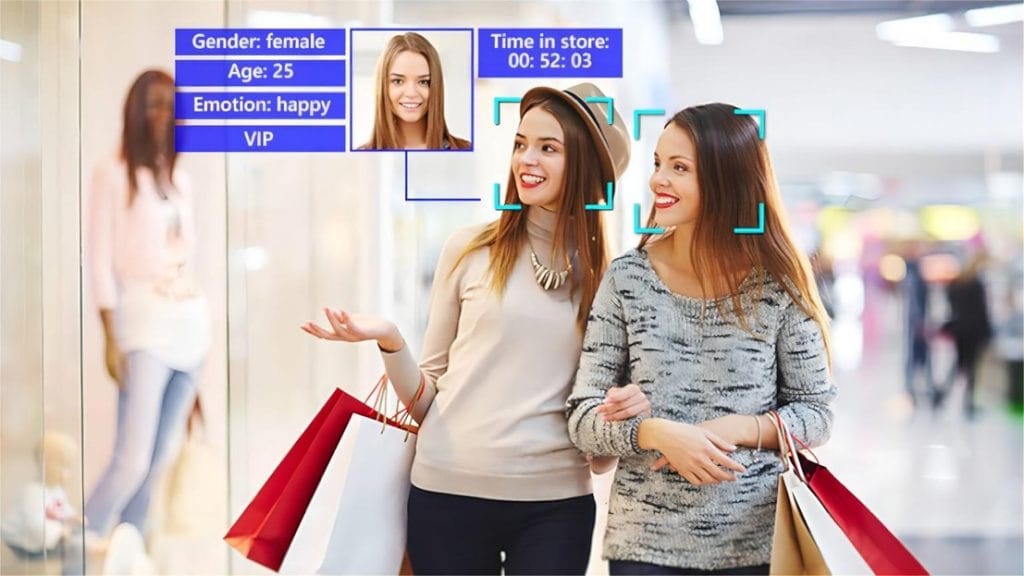
Facial emotion detection tracks landmarks on the face (brow position, mouth shape, eye region) to classify emotions such as engagement, confusion, satisfaction, or frustration. Applied across a store, this provides real-time sentiment data. Retailers can see which displays attract positive reactions and which create friction.

Foot traffic analysis uses person detection, tracking, and pose estimation to map movement through the store. Models measure:
- Unique visitors per zone
- Dwell time at displays
- Common navigation paths
- Congestion points
This informs planogram decisions, product placement, and staff deployment, directly impacting sales.
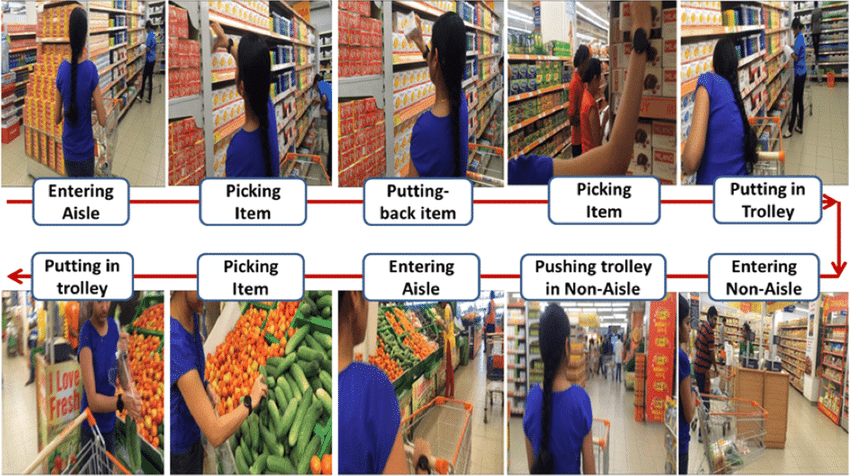
Action recognition identifies behaviors like picking up a product, reading a label, or comparing items. Combined with location data, it provides insights similar to online engagement metrics, i.e. how long customers interact with a product before making a purchase decision.
Privacy and compliance are also critical. Facial and behavioral data should be processed locally without storing identifiable information. Customers must be informed of monitoring, and workflows must follow local regulations. Annotation platforms supporting these workflows help ensure compliance.
8. OCR for Retail Operations
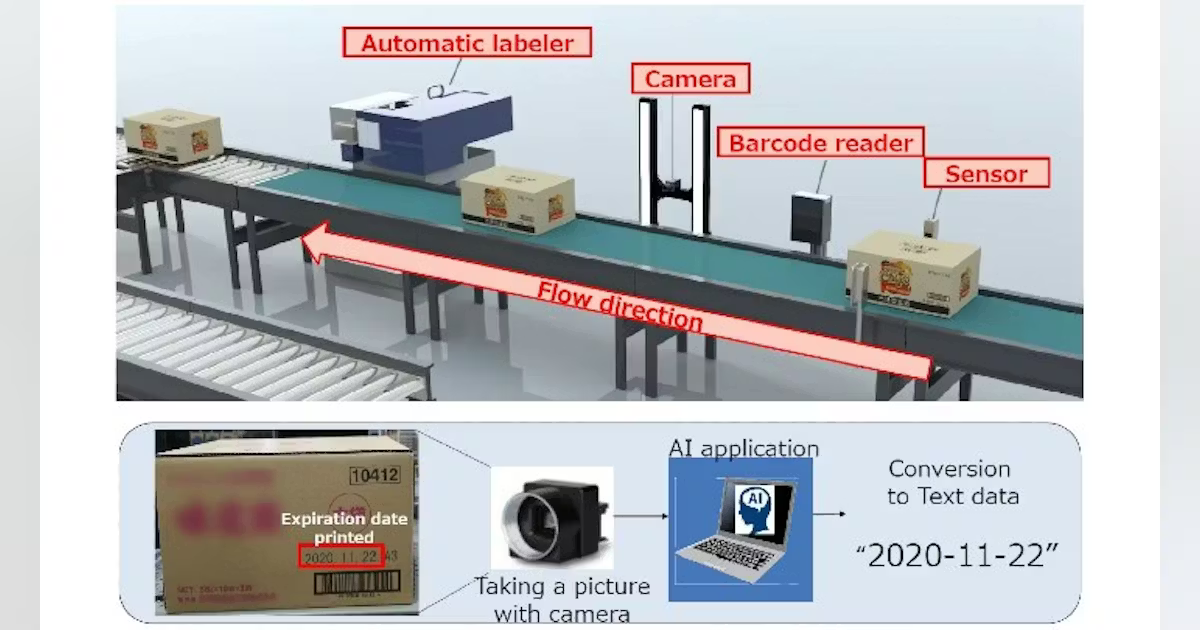
At the product level, OCR models read labels, barcodes, and printed text on packaging to extract product identifiers, ingredient lists, nutritional information, and regulatory compliance data.
In logistics and fulfillment, OCR processes shipping documents, invoices, packing slips, and customs declarations. A model trained on the specific document formats used by a retailer’s supplier base can extract invoice numbers, line-item quantities, unit prices, and shipping addresses with high accuracy, feeding that structured data into ERP and warehouse management systems without manual data entry.

Top 10 OCR Applications
Expiration date reading is technically an OCR task specialized for a narrow domain: small, often embossed or inkjet-printed date codes on a wide variety of packaging backgrounds. These models require training data that captures the full range of date formats (DDMMYY, MM/DD/YYYY, Julian date codes, best-before codes) and printing conditions (contrast variation, partial occlusion, curvature over packaging edges).
Price verification is a growing application in both physical retail and competitive intelligence. In-store, CV systems can read shelf price tags and compare them against the expected price in the pricing system, flagging mismatches before they become customer complaints or compliance issues.
The Role of Data Annotation
Every computer vision application described in this post is, at its foundation, a machine learning model. And every machine learning model is only as good as the data it was trained on, (Garbage In, Garbage Out).
Data annotation (the process of labeling raw images and video with structured ground truth information) is the work that converts raw visual data into the training signal that models learn from. Without high-quality annotation, there are no models; without high-quality models, there are no applications.
The annotation types required across retail CV span the full spectrum of computer vision tasks: bounding box, semantic segmentation, keypoint and landmark annotation, OCR, and others.
Unitlab AI Automation Workflow
Features like model-in-the-loop, where a pre-trained model pre-labels images and human annotators correct rather than create from scratch, can reduce annotation time dramatically for well-defined tasks.
Auto-labeling pipelines, automated quality assurance checks, and dataset versioning are not conveniences; they are the infrastructure required to produce training data at the scale and quality that production retail CV systems demand.

HITL Approach to Data Labeling
Unitlab AI is built specifically for this kind of high-volume, high-precision annotation work. The combination of automated data collection, model-assisted labeling, and systematic QA enables annotation pipelines that are 15 times faster than manual workflows, freeing AI engineers from data preparation overhead so they can focus on model architecture and evaluation.
Conclusion
Computer vision is not a single technology being applied to retail: it is a family of capabilities reshaping the retail industry at every layer simultaneously.
The common thread across all of these applications is the requirement for high-quality training data. The sophistication of the model architecture matters, but the quality, consistency, and scale of the annotated datasets those models learn from is the more fundamental determinant of production performance.
The gap between retailers who treat computer vision as a feature and those who treat it as a core operational capability is widening. The annotation infrastructure that makes that capability reliable and scalable is where that gap is most practically addressed.
Explore More
- Computer Vision for Robotics: Overview
- Computer Vision in Healthcare: Applications, Benefits, and Challenges [2026]
- Practical Computer Vision: Parking Lot Monitoring with a Demo Project
References
- Marharyta K (Feb 07, 2025). Computer Vision for eCommerce: Optimizing Business Processes with Computer Vision. Alltegrio: Source
- Pablo Soto (Jul 04, 2024). Computer Vision in e-commerce: 5 ways it is transforming online shopping. Pento AI: Source
- Piotr Mężyk (Nov 14, 2025). Computer Vision In Ecommerce: AR Solutions For Online Retailers. Nomtek: Source
