AI and machine learning models — and computers in general — aren’t biased by nature. At their core, they’re just tools designed to solve specific problems. But that doesn’t mean they’re neutral in practice. In fact, these tools can end up being quite biased, not because someone deliberately made them that way, but because the data they learn from often carries hidden assumptions and imbalances.
To build practical and effective AI/ML models, we usually need a huge amount of data. There’s a common rule of thumb called the 10x rule, which suggests the dataset should be roughly ten times larger than the number of parameters in the model. But before this data can be used, it has to go through several steps: collection, cleaning, augmentation, and labeling.
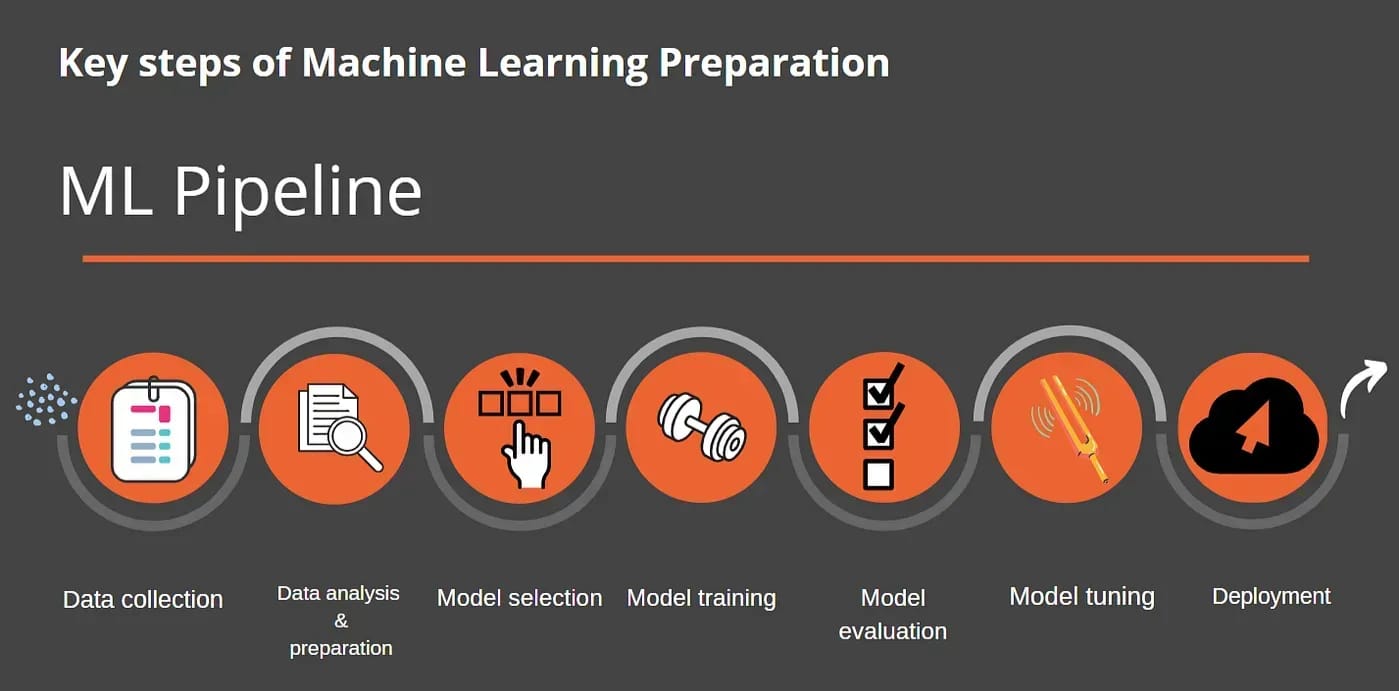
Biases can sneak in at any stage of this pipeline, but they’re most common during the data collection phase. In this post, we’ll look at two key sources of bias that often make their way into the final model — and that you can identify and address in your own AI projects:
- Bias in the data itself
- Bias introduced by human annotators
But first, let’s be clear on what we mean by “bias” in this context.
What is Bias Anyway?
Machine learning bias refers to systematic and unfair disparities in the output of machine learning algorithms. These biases can manifest in various ways and are often a reflection of the data used to train these algorithms.
— Wikipedia
Put simply, bias is a pattern of error in a model’s outputs that systematically favors or disadvantages certain groups, classes, or scenarios. The tricky part is that this often isn’t obvious at first glance. A model might underperform on minority groups, misrepresent ideologies, or entirely overlook rare edge cases — and unless you’re explicitly looking for these issues, they may go unnoticed until they cause real harm.

To understand bias more intuitively, consider a real-world example from the world of finance: herd mentality. This is the tendency of investors to copy what others are doing — not based on logic or analysis, but simply because "everyone else is doing it." This behavior has fueled everything from the dot-com bubble in 1999 to the GameStop short squeeze in 2021.
If you bought shares in an overhyped stock simply because it was trending online, you’ve experienced herd bias firsthand. It’s an emotional shortcut that overrides independent thinking — and it’s a powerful force that leads to irrational decisions and inflated markets.

Bias in machine learning is similar: it’s often not about malicious intent, but about inherited assumptions — patterns passed down from flawed data. And the consequences are real, whether it's an algorithm making incorrect predictions or reinforcing outdated norms.
Bias in Data
This type of bias occurs when the dataset used to train an AI model doesn’t accurately reflect the diversity and complexity of the real world. These gaps can take many forms: an overrepresentation of certain classes, missing data from specific regions or groups, or an overreliance on polished or ideal scenarios.
Here are a few common types of data bias that have been well documented:
- Language bias: Most large language models are trained primarily on English content. As a result, they tend to prioritize Western perspectives while downplaying or ignoring ideas expressed in other languages. For example, search queries on concepts like "liberalism" often return Anglo-American definitions that may not align with interpretations in other parts of the world.
- Gender bias: AI models often reflect the same gender imbalances found in historical data. A notable example comes from Amazon’s 2015 hiring tool, which began penalizing résumés from women simply because past data showed that most successful applicants were men. The model learned from this skewed history and started downgrading applications that mentioned women’s colleges or female-coded language.
- Political bias: Closely tied to language bias, political bias arises when models lean toward a particular ideology based on the data they were trained on. In efforts to appear politically neutral and achieve political correctness, some systems may even strip away meaningful context — sacrificing current and historic facts in the name of balance.

- Racial bias: Many datasets used in healthcare, law enforcement, and facial recognition have historically underrepresented people of color. The result is algorithms that don’t work as well for these groups — leading to higher error rates, misidentifications, or unequal access to services.
A widely cited example is facial recognition technology. Multiple independent studies have found that these systems perform significantly worse on individuals with darker skin tones.
The root cause? The datasets used to train them contained disproportionately more images of lighter-skinned individuals. This imbalance means that, even if the algorithm is not inherently biased, its training history makes it less accurate for certain groups.
To address this data bias, we have written an extensive guideline before:
Common Dataset Mistakes | Unitlab Annotate
Human Bias during Labeling
Even if your data is diverse and balanced, you are not in the clear yet. The next layer of bias can emerge during the labeling process — when humans annotate the data used to train your model.
Annotators are people, and like all of us, they bring their own perspectives, assumptions, and mental shortcuts into the task. This becomes especially noticeable in subjective labeling tasks, such as classifying emotions in text, drawing segmentation masks, or rating content for toxicity.
A recent paper, Blind Spots and Biases (Srinath & Gautam, 2024), dives into this issue. The researchers found that annotators often deviated from the intended labels due to cognitive fatigue, reliance on shortcuts, or personal beliefs. Even with clear instructions, different annotators interpreted the same data differently — leading to inconsistencies that ripple into the model’s behavior.
So what can you do about this?
- Use multiple annotators and compare their responses. Metrics like Cohen’s Kappa can help quantify disagreement.
- Develop clear, example-rich labeling guidelines that reduce ambiguity.
- Regularly review samples for consistency and provide feedback.
- Rotate tasks or implement breaks to reduce fatigue-related errors.
- Track patterns across annotators — are certain individuals consistently mislabeling edge cases?
Human input is powerful — it adds nuance and judgment that machines lack — but it needs guardrails. A thoughtful data annotation process can go a long way in reducing bias at this stage.
Conclusion
Bias in AI isn’t caused by a single mistake. It’s the result of a long chain of small, often invisible decisions — from how the data is collected to how it’s labeled and interpreted. The key isn’t to aim for perfection, but to build awareness and processes that help detect and reduce bias where it matters most.
By actively questioning your data sources, diversifying your inputs, and supporting your annotators with better tools and guidelines, you don’t just build a better model — you build a fairer one. And in a world where AI is playing a bigger role in everything from hiring to healthcare, that makes all the difference.
Explore More
Explore these resources for more on data annotation:
- Data Annotation at Scale
- (Processed) Data is the New Oil
- Importance of Clear Guidelines in Image Labeling
References
- IBM (no date). What is AI bias? IBM Think: Link
- Inna Nomerovska (Dec 13, 2022). How A Bias was Discovered and Solved by Data Collection and Annotation. Keymakr Blog: Link
- Mukund Srinath and Sanjana Gautam (Apr 29, 2024).Blind Spots and Biases: Exploring the Role of Annotator Cognitive Biases in NLP. arXiv: Link