
![Audio Data Annotation with Unitlab AI [2025]](/content/images/size/w2000/2025/12/audio-unitlab.png)
Data labeling is not only about images. Depending on the model and use case, it can be for different file formats: text, audio, or video.
Unitlab AI - Audio Data Annotation
The annotation process is the preparation of AI/ML datasets by tagging or adding metadata so that models can learn patterns and generalize across new scenarios accurately. The data and labeling must be customized based on what these AI technologies are used for. This is quite similar to the Unix philosophy of “Do one thing, and do it well.”

In this post, we will focus on the annotation phase of audio data for a specific AI model we use daily, Audio AI.
You will learn:
- what audio labeling is
- types of audio annotation
- a hands-on audio labeling tutorial
- why audio labeling matters
Let's dive in!
What is Audio Labeling, Essentially?
Everyday voice assistants like Apple Siri or Amazon Alexa are prime examples of Audio AI in action. Any application (Google Search, for instance) that can receive commands in voice form relies on annotating audio data. Basically, they are machine learning models that can handle speech data with the use of speech recognition technology.
These interactive systems are built on top of models that can process audio data in real time, such as Mozilla’s DeepSpeech or Meta AI’s Wav2Vec 2.0.
Audio labeling is the process of preparing audio files specifically for audio datasets. This could mean:
- Writing out speech as text (audio transcription)
- Identifying who is speaking (speaker identification)
- Marking sound events like alarms, sirens, or claps (audio segmentation)
- Highlighting emotions such as happiness, frustration, or neutrality (emotion detection)
Essentially, just like any other data labeling mode, audio annotation turns raw sound into structured data that AI models can use.
How audio annotation is different
The reality is that AI models are increasingly used everywhere in the business world across industries. Obviously, they require different types of datasets depending on their use case. Therefore, various data labeling types and techniques have evolved over time.
Essentially:
- Building face detection → image labeling
- Building video surveillance → video annotation
- Building a chatbot → text annotation
- Building a voice assistant → audio annotation

Beware that no annotation type works for every case. If you only have a hammer, every problem looks like a nail.
In a nutshell, audio annotation differs from other types of data labeling in its nature and data type. The AI model you build dictates which type of labeling you do.
Types of Audio Annotation
Data annotation types share broad similarities, but differ in details. For instance, classification and sentiment analysis appear in all domains of data annotation, but look very different in labeling audio data.
To illustrate different types of audio annotation in practice, we'll go through this famous scene from Star Wars: Episode III – Revenge of the Sith (2005):
Star Wars: Episode III – Revenge of the Sith (2005)
It’s a perfect example because 1) everyone knows it, and 2) it has everything we need: words, music, and raw emotion.
Audio Transcription
Most common. The focus here is to produce a accurate and complete text completion for video subtitles, legal materials and conference archives, usually by using transcription tools. This task is human-centered, for humans.
For our example, this transcription could look like this:
Obi-Wan: You were the chosen one! It was said that you would destroy the Sith, not join them! Bring balance to the Force, not leave it in darkness.
Speech Recognition
Often confused with text transcription, but it is machine-centered. The goal is not to produce a verbatim written record of the audio file, but to understand and act on it in real-time.
For example, if you upload the audio file to a natural language processing model like ChatGPT, it acts on it based on your prompt. It might find the YouTube clip, refer to a Star Wars fandom page, or write the transcript.
Speech recognition is wider than audio transcription in its scope, and considered an input for the natural language processing machines in the audio annotation pipeline.
Audio Classification
Assigns one or more labels to the entire audio recording. You don’t care about who spoke or when, only about the meaning of the audio data.
For our Star Wars example, audio classification could produce a whole list of labels: "dialogue", "human_speech", "English", "high_emotion".
Audio Segmentation
It is so much easier to annotate audio recordings when you have meaningful, bite-sized audio segments (chunks) to work with. Thus, this type is generally the first step in labeling audio data.
This mode splits the audio into time-stamped audio segments with labels. It is built on sound event detection. These specific segments can be of any intuitive name like music and siren sounds, or even background noise. The focus is: where does one unit end and another begin? This differs it from basic audio transcription.
We could segment our full audio file this way:
[0.0s – 9.5s] “You were the chosen one! … darkness.” → speech[9.6s – 11.0s] “I hate you!” → speech[11.1s – 14.0s] “You were my brother, Anakin. I loved you.” → speech
Speaker Identification
Also known as speech recognition, it is closely related to audio segmentation but differs in subtle, important ways. While the goal of segmentation is to create time-based chunks, it does not automatically care who is speaking.
This type identifies who the speaker is in a given moment in the audio data. It usually comes after audio segmentation for accurate annotations. With speech recognition added, our example could look like this:
[0.0s – 9.5s] Obi-Wan: “You were the chosen one! … darkness.” → speaker = Obi-Wan[9.6s – 11.0s] Anakin: “I hate you!” → speaker = Anakin[11.1s – 14.0s] Obi-Wan: “You were my brother, Anakin. I loved you.” → speaker = Obi-Wan
Emotion Detection
Binary task: is there emotion present in our audio recording, yes or no? It does not ask when, where, what kind, whose; it just checks for the existence of any emotion in the clip.
Is there emotion in our example clip? Yes. Anger, anguish, rage, sadness. You name it.
Emotion Recognition
Emotion recognition (sentiment analysis) takes two steps further and assigns emotions to bite-sized chunks generated by audio segmentation, similar to speaker identification:
In our case, this could be:
[0–9.5s] (Obi-Wan): anguish / betrayal[9.6–11.0s] (Anakin): rage / hatred[11.1–14.0s] (Obi-Wan): grief / love
Language Identification
Determines which language is being spoken. For example, if you talk to a voice assistant or a chatbot, it automatically detects your language and replies in your language. Depending on the system, it can detect dozens of different languages and identifies the correct one. This is especially useful when the AI system should work with many languages.
For our audio clip, this is easy: English.
Language Classification
Imagine a government services AI system developed for the Canadian government. In the beginning, it can only respond for English and French. Over time, they might add multilingual support for other predominant languages in Canada.
Initially, when the call comes to this audio AI, it might classify the request as either English or French. It might neglect or misinterpret another language, say, Ukrainian.
In essence, LangID detects a language, while Lang Classification sorts it into a fixed set of known languages.
Putting It All Together
These audio labeling types do no exist in vacuum. In practice, these types are combined to create full audio datasets. A typical pipeline begins with segmentation, followed by speech recognition and emotion labeling.
Putting it all together, in audio annotation software, we could generate these full audio segments:
[0.0s – 9.5s] Obi-Wan: “You were the chosen one! … darkness.” → speaker = Obi-Wan, emotion = anguished, language = English[9.6s – 11.0s] Anakin: “I hate you!” → speaker = Anakin, emotion = rage, language = English[11.1s – 14.0s] Obi-Wan: “You were my brother, Anakin. I loved you.” → speaker = Obi-Wan, emotion = sorrow, language = English
Audio segmentation, speech recognition, emotion recognition, language identification, all in one place. Pretty slick, no?
Audio Labeling Project at Unitlab AI
Project Setup
Now that you know these audio labeling modes, we will show how audio annotation is done with Unitlab AI, a fully-automated data labeling tool. You can choose different audio annotation tools from in this platform.
First, create your free account to follow the tutorial:
In the Projects pane, click Add a Project:
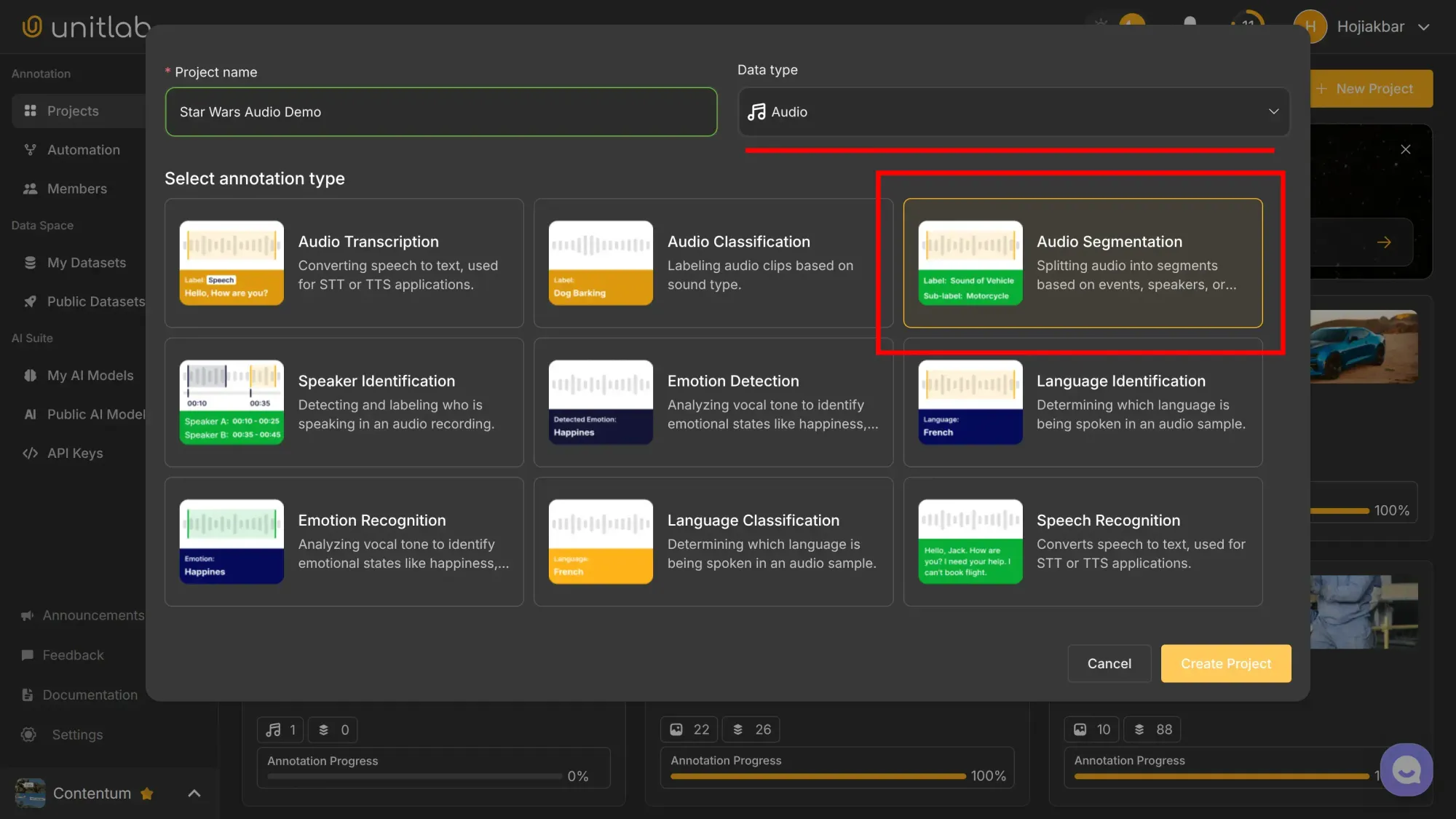
Name the project, choose Audio as the data type and Audio Segmentation for the annotation type:
Upload project data. You can use the longer audio clip of the Star Wars video we have been using for illustration. Download it here:
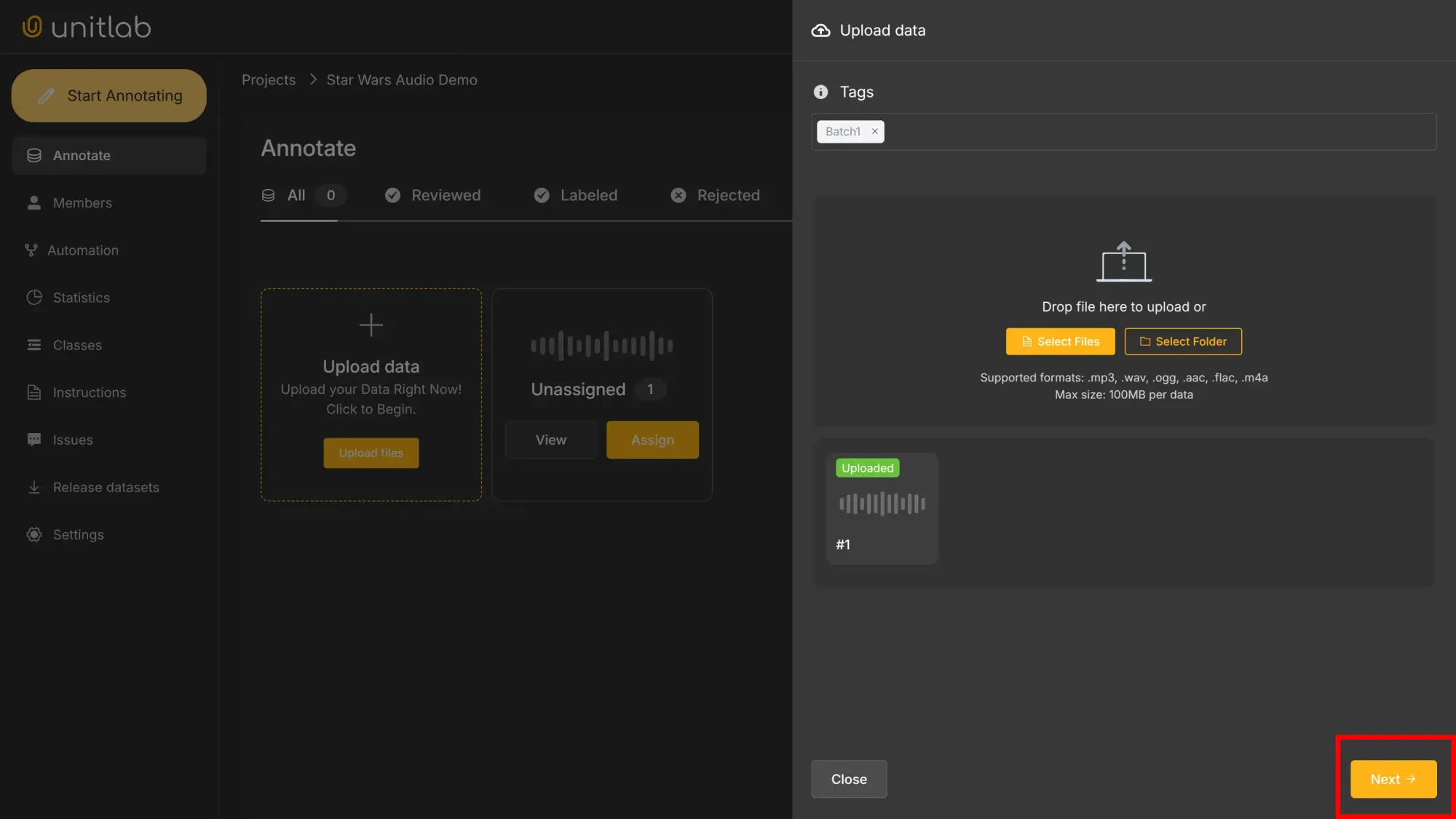
Our audio labeling project is now ready.
Audio Labeling
Annotating audio data differs notably from photo, video, or text labeling. It might be intimidating for the new users, but with the help of intuitive audio annotation tools and platforms such as Unitlab Annotate, it is actually quite easy.
Take a look at this video below. We first define two classes, obi-wan and anakin , and add annotations where they each speak. The additional configuration is there to help you annotate faster:
Audio Segmentation | Unitlab Annotate
The video is purposefully longer to explain the audio segmentation process. In reality, it takes less time as you become more experienced with the labeling type and the intuitive interface of your chosen audio annotation software.
If you plan to increase the quality of your audio labels, Unitlab Annotate provides additional configuration you can use to fine-tune your annotation:
- You almost always increase audio speed to fasten the labeling process.
- You may want to increase zoom to segment the audio file more accurately.
- You will probably customize your dashboard, configuring a setup that works optimally for you.
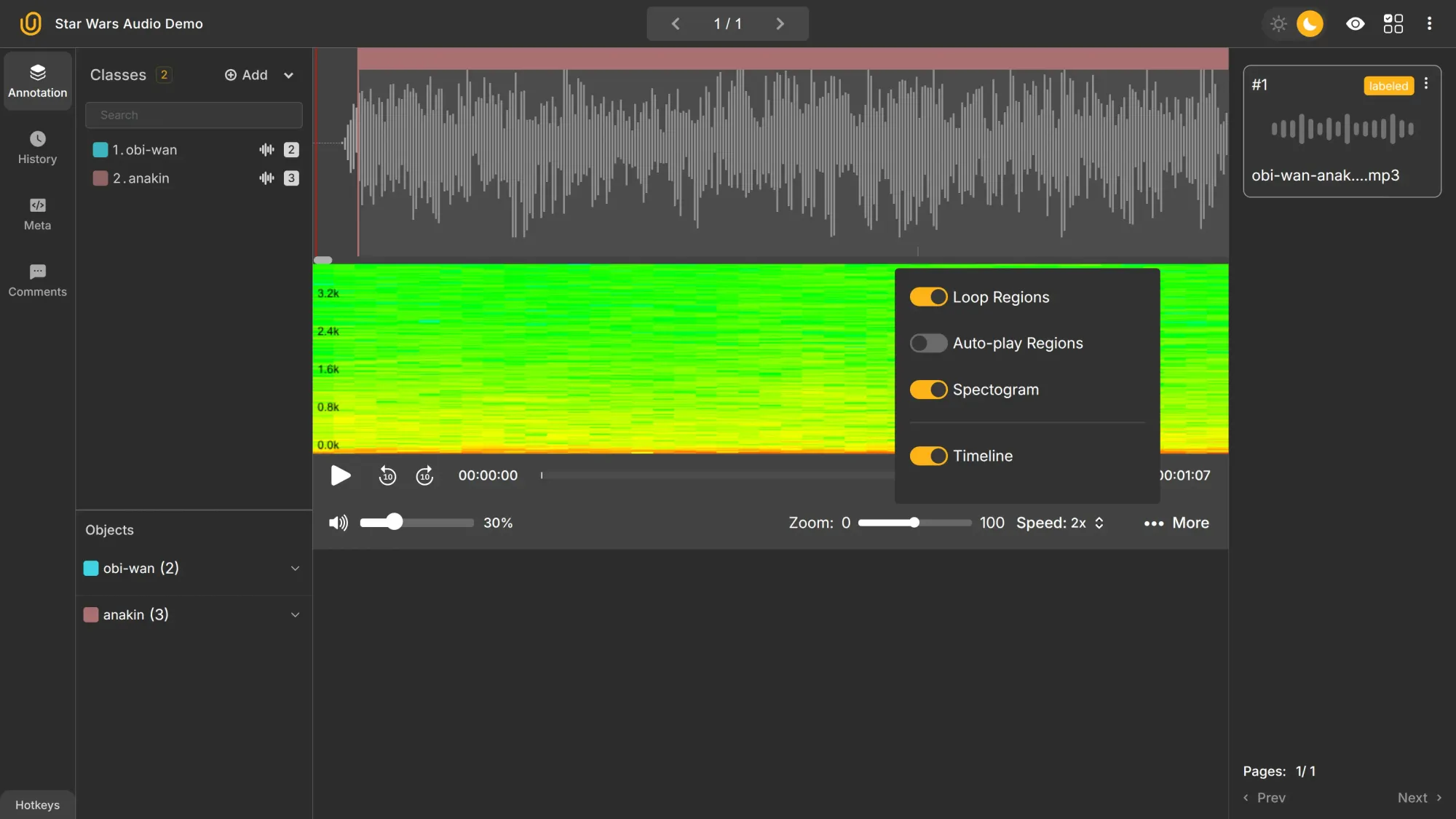
In the dashboard above, you can see that the zoom is set to 50 and the speed to 2x. I may choose to toggle off Spectogram and Timeline as I see fit for labeling the audio. With zoom, I see that my segment for the class anakin is slightly off; I will fix it, increasing accuracy.
Why Care about Audio Annotation?
So, after all these, let's answer briefly why care about audio labeling at all?
Audio AI needs structured audio data to learn audio and speech patterns. The quality of your model depends on the quality of your labeled audio recordings.
If you are building any kind of audio AI: voice assistants, transcription services, or call center analytics, you need good audio annotation tools to create a well-labeled audio dataset.
Conclusion
Audio annotation is another type of data labeling. You need different data types to train different AI/ML systems.
Audio labeling is more than just transcribing spoken language. It's about interpreting the audio data: words, speakers, emotions, and languages so that audio AI systems can work with these audio files.
The audio annotation process might look intimidating at first, but with AI-powered audio annotation tools and audio annotation software like Unitlab AI, you can easily start labeling audio files in your machine learning projects.
Explore More
Check out these resources for more on data annotation:
- A Comprehensive Guide to Image Annotation Types and Their Applications
- Data annotation: Types, Methods, Use Cases.
- The Rise of Data Annotation Platforms
References
- Cem Dilmegani (Jul 3, 2025). Audio Annotation. AI Multiple: Source
- Hojiakbar Barotov (Mar 15, 2025). Who is a Data Annotator? Unitlab Blog: Source
- Telus Digital (no date). Audio annotation. Telus Digital Gloosary: Source

![Text Annotation with Unitlab AI [2025]](/content/images/size/w360/2025/12/text.png)