Data annotation is the foundation of artificial intelligence and machine learning. Every high-performing AI system depends on accurately labeled data. From computer vision annotation to medical image labeling and robotics dataset annotation, the quality of training data directly determines model accuracy, reliability, and scalability. Whether it is image annotation for computer vision, LiDAR dataset labeling, or multimodal ML annotation, the strength of an AI system begins with the precision of its dataset.
The rapid expansion of AI applications has intensified the demand for scalable data labeling solutions. Enterprises today rely on data labeling platforms, dataset annotation tools, and ML data annotation services to build robust AI systems. However, traditional manual review processes often struggle with scalability, consistency, workforce management, and rising operational costs. As AI adoption accelerates across healthcare, robotics, geospatial intelligence, manufacturing, and autonomous systems, organizations are reevaluating their approach to data labeling for machine learning and deep learning model training.
In response, annotation QA automation, powered by large language models and intelligent agents, has emerged as a new-generation solution. AI-powered labeling software and AI-accelerated annotation tools now support annotation workflow automation, combining machine learning data labeling with human-in-the-loop annotation platforms. These systems detect inconsistencies, reduce review time, and strengthen quality control across complex datasets, from segmentation dataset tools and object detection labeling tools to medical imaging QA automation and satellite image annotation.
However, a critical question remains: can AI fully replace human quality control?
While automated image labeling tools and computer vision workflow automation dramatically improve speed and efficiency, high-risk domains such as healthcare ML labeling services and robotics ML data services still depend on human judgment, bias mitigation, and contextual reasoning.
As organizations evaluate outsourcing training data creation, annotation services companies, and enterprise data annotation platforms, they face a strategic decision. In 2026, will annotation QA agents replace manual review, or will hybrid quality control become the new standard for data annotation for AI?
In this blog, we will discuss:
- Manual review and annotation QA automation in modern data annotation workflows
- Workforce-driven vs compute-driven quality control models
- The strengths and limitations of automated data labeling
- A direct comparison of manual, automated, and hybrid QA architectures
- Whether AI can realistically replace human quality control in 2026
What Is Manual Review in Data Annotation?

Manual review has shaped the foundation of modern artificial intelligence. Before advanced automation and intelligent systems were introduced, the quality of model training data depended almost entirely on human expertise.
At its core, data annotation for machine learning follows a structured human workflow. Annotators use a data labeling platform or dataset annotation tool to label images, text, video, or sensor data. Once the primary annotation is completed, a second human reviewer validates the output against predefined guidelines, ensuring accuracy, consistency, and compliance with project requirements.
This layered approach became the standard model for data labeling and annotation services. Annotation services companies and data labeling outsourcing companies built operational systems around it. A model training data provider would not deliver a dataset until it passed multiple rounds of human verification.
Manual review offers several strengths.
First, it provides contextual judgment. Human reviewers understand ambiguity in instance segmentation labeling, recognize subtle inconsistencies in object detection labeling tools, and detect errors that automated systems may overlook. In regulated environments such as medical imaging annotation or safety-critical robotics dataset annotation, this human oversight remains essential.
Second, manual workflows allow direct interpretation of project-specific instructions. Complex computer vision annotation projects often require interpretation beyond simple boundary drawing. Reviewers evaluate edge cases, annotation drift, and class confusion within computer vision ML data.
Third, manual review reinforces accountability. Annotation workforce management structures assign responsibility to identifiable teams, creating traceability within enterprise data annotation platforms.
For years, this model scaled with demand. More data requires more annotators and more reviewers. Organizations that chose to outsource data annotation or rely on data labelling outsourcing expanded teams to maintain delivery speed.
However, as dataset volumes increased into the millions, the operational model began to show strain. Costs grew proportionally with dataset size. Review cycles and extended delivery timelines. Maintaining consistency across distributed teams became increasingly complex.
Manual review remains reliable and trusted. It continues to anchor many data labeling solutions today. Yet as enterprises demand faster turnaround, tighter margins, and scalable annotation workflows, the question is no longer whether manual review works. The question is whether it alone can support the next stage of AI growth.
This pressure becomes even more visible when we examine how manual review operates across different visual data types. Image annotation and video annotation introduce distinct operational challenges, particularly in review time, consistency control, and cost structure.
The table below highlights the structural differences between manual review in image and video annotation workflows.
| Aspect | Image Annotation (Manual Review) | Video Annotation (Manual Review) |
|---|---|---|
| Review Complexity | Single-frame validation | Multi-frame sequence validation |
| Time Requirement | Moderate per image | High due to frame-by-frame checking |
| Error Detection | Easier to isolate mistakes | Temporal inconsistencies harder to detect |
| Edge Case Handling | Clear boundary inspection | Occlusion and motion complicate review |
| Consistency Control | Reviewer-dependent | Tracking drift across frames common |
| Cost Impact | Linear with dataset size | Significantly higher due to volume of frames |
| Scalability | Manageable for medium datasets | Difficult at large scale |
As dataset scale and complexity continue to grow, organizations are rethinking how quality control should operate. This shift has led to the emergence of annotation QA automation as a structured alternative to purely manual review.
What Is Annotation QA Automation?
Annotation QA automation refers to the integration of automated validation mechanisms within modern data labeling platforms to monitor, verify, and improve annotation quality at scale. Unlike traditional manual review, where quality control occurs after labeling is completed, annotation QA automation embeds intelligent validation directly into the annotation workflow.
In practice, enterprise annotation platforms such as Unitlab implement these capabilities through built-in quality checks, AI-assisted validation, and structured human-in-the-loop escalation. Instead of treating QA as a separate phase, the system continuously evaluates annotations during production, enabling scalable, consistent, and risk-aware data labeling operations.
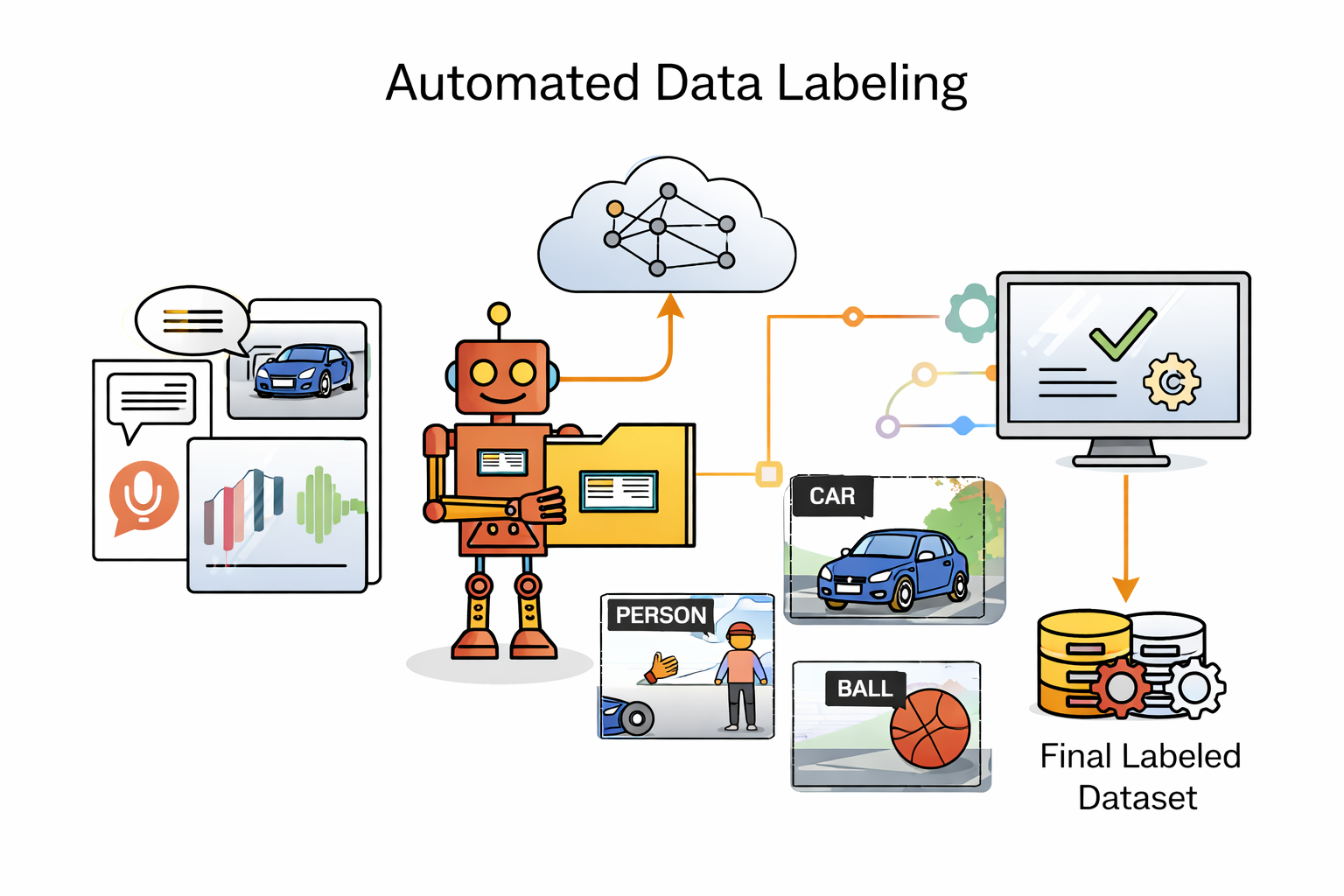
At its core, automated data labeling is labeling that is not performed entirely by a person. Machine learning models learn labeling patterns through self-training processes and apply labels based on learned rules, statistical correlations, and historical examples. The system identifies which labels should be applied to which data points, reducing dependence on sequential human review.
These models rely on machine learning algorithms that detect patterns, reason over similarities, and adjust based on new data. In structured computer vision annotation tasks such as object detection labeling, segmentation dataset tools, or instance segmentation labeling, automation evaluates bounding box placement, class consistency, and structural constraints. In video annotation workflows, temporal consistency rules monitor frame-to-frame drift. In medical imaging QA automation or robotics dataset annotation, anomaly detection helps identify high-risk samples requiring expert validation.
Rather than eliminating human oversight, annotation QA automation restructures it.
Human-in-the-loop annotation platforms focus reviewer attention on uncertain or flagged samples, while automated systems handle repetitive validation checks.
How Automated Data Labeling Works
Automated data labeling typically operates through:

Now that we have the workflow, let’s break down each step in more detail.
1. Self-Training Models
Models learn labeling behavior from previously annotated data. Over time, they predict labels for new data points based on learned patterns.
2. Active Learning
Active learning is a semi-supervised process in which the system selects uncertain samples from unlabeled data and requests human input. The feedback improves future predictions, gradually increasing annotation precision.
3. Rule-Based Validation
Predefined rules ensure structural correctness. For example, bounding boxes must stay within image boundaries, class hierarchies must match ontology definitions, and segmentation masks must not overlap incorrectly.
4. Anomaly and Drift Detection
AI-powered labeling software monitors annotation consistency across datasets. If labeling drift or unusual class distribution appears, the system flags it for review.
This structure allows scalable annotation workflows inside enterprise data annotation platforms without proportional increases in manual review labor.
Advantages of Automated Data Labeling
| Advantage | Impact |
|---|---|
| High Speed | Large datasets processed rapidly |
| Cost Efficiency | Reduced reliance on full manual review cycles |
| Scalable Operations | Compute-based scaling rather than workforce-based scaling |
| Active Learning Improvement | Models improve over time through human feedback |
| Continuous Validation | Quality signals generated in real time |
Automated data labeling reduces operational expenses by minimizing repetitive review tasks. Instead of hiring large annotation workforce teams for linear scaling, organizations rely on compute-based expansion.
Active learning further enhances performance by focusing human effort only where model uncertainty exists. Over time, this improves model stability and data consistency.
Limitations of Automated Data Labeling
| Limitation | Risk |
|---|---|
| Limited to Training Patterns | Poor generalization to unseen scenarios |
| Hidden Error Propagation | Incorrect labels may reinforce future mistakes |
| Difficulty Handling Ambiguity | Complex contextual interpretation remains challenging |
| Dependence on Sample Quality | Biased training data produces biased outputs |
| High Initial Setup | Requires model training and integration infrastructure |
Automated systems learn from existing sample datasets. If training data contains errors or bias, these issues may propagate into future predictions. Unexpected edge cases, rare visual classes, or safety-critical anomalies may not be detected reliably without human expertise.
In image annotation and video annotation tasks, automated labeling may struggle with occlusion, subtle object boundaries, or ambiguous contextual cues that experienced reviewers interpret more accurately.
Manual Review vs Annotation QA Automation: A Direct Enterprise Comparison
As AI systems scale, the debate is no longer about whether quality control is necessary. It is about how it should be structured. Manual review and annotation QA automation represent two fundamentally different operational models. One is workforce-driven and sequential. The other is compute-driven and embedded directly into the annotation workflow.
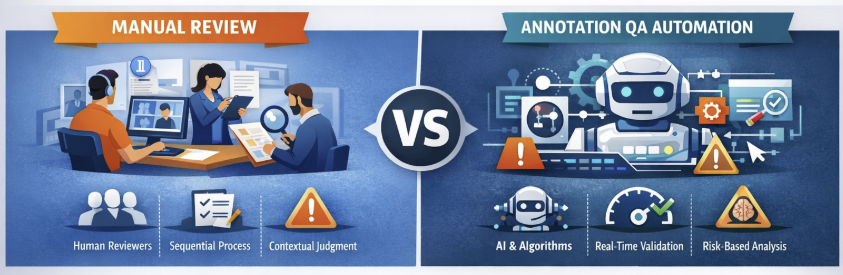
Manual review relies on layered human validation. Annotators complete tasks using a data labeling platform, and reviewers validate outputs according to guidelines. This model provides strong contextual reasoning and is particularly effective in ambiguous or safety-critical scenarios.
Annotation QA automation, in contrast, integrates validation mechanisms directly into the data annotation tool. Confidence scoring, rule-based validation, active learning, and anomaly detection continuously monitor annotation quality. Instead of reviewing every sample, the system prioritizes uncertain or high-risk cases for human inspection.
The difference is structural. Manual review scales by adding more reviewers. QA automation scales by increasing compute capacity and model sophistication.
Below is a structured comparison across enterprise-relevant criteria.
| Criteria | Manual Review | Annotation QA Automation |
|---|---|---|
| Validation Timing | Post-annotation review cycles | Continuous, embedded validation |
| Scalability Model | Workforce-based scaling | Compute-based scaling |
| Cost Behavior | Linear growth with dataset size | Marginal cost decreases at scale |
| Speed | Sequential and review-dependent | Real-time or near real-time validation |
| Consistency Control | Reviewer-dependent | Statistical and rule-driven monitoring |
| Edge Case Handling | Strong contextual judgment | Escalates uncertain cases to humans |
| Operational Complexity | High workforce coordination | Higher technical integration, lower manual overhead |
| Bias Mitigation | Human review oversight | Pattern detection + human escalation |
| Best Fit Scenarios | Regulated, high-risk domains | Large-scale CV, video, and multimodal datasets |
Analytical Perspective
Manual review remains essential in domains where interpretability, domain expertise, and regulatory compliance are critical. Medical imaging annotation, robotics dataset annotation for safety systems, and highly specialized computer vision workflows continue to depend on human contextual reasoning.
Annotation QA automation performs best in high-volume environments where speed, consistency, and scalability are priorities. In image annotation and especially video annotation workflows, automation reduces bottlenecks by eliminating the need to manually inspect every frame.
However, the comparison is not binary. Enterprises increasingly adopt hybrid quality control models that combine automated validation with targeted human review. This approach reduces operational strain while preserving oversight in ambiguous or high-risk cases.
The next logical question is whether hybrid models represent a transitional phase or the long-term standard for data annotation for AI in 2026.
Hybrid Annotation QA Architecture
A hybrid annotation QA architecture is a quality control model that integrates automated data labeling with structured human oversight. It is designed to balance scalability and contextual judgment within modern data annotation workflows.
Rather than operating as a purely manual review system or a fully automated pipeline, hybrid architecture embeds validation directly into the annotation process. Automated components perform large-scale labeling, structural validation, and consistency monitoring. Human reviewers intervene selectively when uncertainty, ambiguity, or risk thresholds are exceeded.
This structure changes how quality control scales. Manual review alone scales proportionally with workforce size. Fully automated labeling scales with compute but may struggle with ambiguity and rare edge cases. Hybrid architecture combines both strengths: automation ensures speed and consistency, while human expertise preserves contextual reasoning and domain sensitivity.
In this model, quality control becomes continuous rather than sequential. Validation signals are generated throughout the workflow instead of after dataset completion. As a result, annotation drift, structural violations, and uncertainty are detected earlier, reducing downstream correction costs.
The following figure provides an example of how such a hybrid annotation QA architecture may be structured in practice.
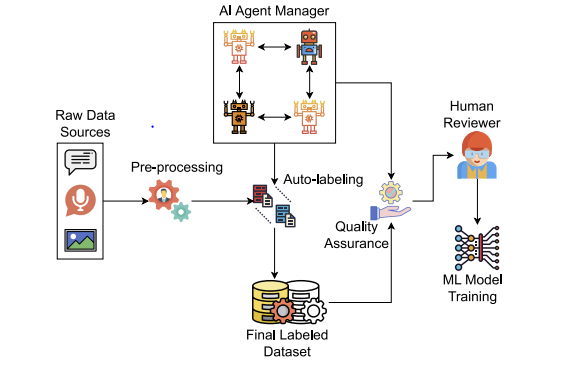
The figure shows how a hybrid pipeline operates from raw data to model training.
The workflow starts with raw data sources, such as images, audio, or text. Before labeling begins, data moves into a pre-processing stage, where inputs are cleaned, normalized, and aligned with required formats and metadata.
Next, the AI Agent Manager coordinates automated labeling behavior. In practice, this layer may include multiple specialized agents or models that collaborate to produce initial annotations. These agents drive the auto-labeling stage, generating preliminary labels such as bounding boxes, segmentation masks, keypoints, or structured tags depending on the task.
After auto-labeling, outputs pass through a Quality Assurance layer. This stage performs continuous validation inside the pipeline, including:
- Confidence scoring to estimate reliability
- Rule-based validation to enforce structural and ontology constraints
- Cross-sample consistency checks to reduce annotation drift
- Anomaly and drift detection to identify unusual patterns or distribution shifts
When the system detects uncertainty or violations, selected samples are routed to the human reviewer, shown on the right side of the figure. This is the human-in-the-loop mechanism. The reviewer focuses on complex or high-risk cases rather than inspecting every annotation.
Finally, validated outputs become the final labeled dataset, which is then used for ML model training. The figure highlights that quality control is embedded and continuous, with human effort applied selectively where it adds the most value.In the illustrated example, raw data enters a pre-processing stage before reaching an AI coordination layer. Automated agents generate preliminary annotations, which then pass through a validation module that performs confidence scoring, rule-based checks, and drift monitoring. Only samples that exceed predefined uncertainty thresholds are escalated to human reviewers. Once validated, the refined outputs form the final labeled dataset used for ML model training.
The image represents one possible implementation. The specific components may vary across enterprise data annotation platforms. However, the core principle remains consistent: automation handles scale and repetitive validation, while human oversight concentrates on complexity and risk.
Hybrid annotation QA architecture therefore represents a structural evolution in data annotation for AI. It does not eliminate human review. It reallocates it.
Strategic Outlook for Annotation QA in 2026
The evolution of annotation QA is no longer a theoretical discussion. It is an operational necessity driven by dataset scale, multimodal complexity, and enterprise risk management.
By 2026, annotation workflows will undergo a measurable structural shift. Human review will not disappear, but its volume will significantly decrease as AI agents assume a larger share of validation responsibilities. Repetitive review cycles, frame-by-frame inspection in video annotation workflows, and large-scale image dataset labeling checks will increasingly be handled by intelligent QA agents embedded inside enterprise data annotation platforms.
In this new structure, successful AI organizations will design systems where:
- Automated validation handles scale and repetition
- AI agents perform continuous confidence scoring and anomaly detection
- Human reviewers focus on ambiguity, edge cases, and risk-sensitive scenarios
- Validation is embedded directly into the annotation pipeline
- Quality metrics are continuously monitored and auditable
- Oversight is allocated based on risk profile rather than sample volume
This represents a reallocation of human effort rather than elimination. Instead of reviewing every annotation, domain experts supervise the system, intervene selectively, and validate high-impact decisions.
The economic impact is significant. As AI agents assume repetitive QA tasks, marginal review costs decrease. Workforce scaling becomes less linear. Annotation QA shifts from labor-intensive inspection toward intelligent supervision.
However, full replacement of human quality control remains unlikely in regulated or safety-critical domains. Healthcare ML labeling services, robotics ML data services, and high-risk enterprise AI deployments will continue to require human accountability layers.
The defining change in 2026 is therefore not replacement, but redistribution.
AI agents will absorb the majority of repetitive quality validation tasks. Human oversight will become more strategic, more specialized, and more risk-aware.
Organizations that proactively redesign their annotation QA architecture around this principle will achieve superior scalability, cost efficiency, and governance control.
Conclusion
Data annotation remains the foundation of artificial intelligence. As AI systems scale across computer vision, medical imaging, robotics, and multimodal applications, the structure of quality control becomes a strategic decision rather than an operational detail.
Manual review built the foundation of modern AI. It provides contextual reasoning, accountability, and domain sensitivity. However, workforce-driven scaling cannot sustainably support the volume and velocity of next-generation datasets.
Annotation QA automation introduces compute-based scalability, embedded validation, and continuous monitoring. It reduces repetitive review labor and improves operational efficiency. Yet, full automation alone struggles with ambiguity, rare edge cases, and high-risk decision contexts.
The future is not a choice between human or machine. It is architectural design.
In 2026, successful AI organizations will deploy hybrid annotation QA systems where:
- Automated validation manages scale
- Human expertise concentrates on risk and ambiguity
- Quality signals are embedded within the workflow
- Oversight is allocated intelligently, not uniformly
AI will not eliminate human QA. It will redefine it.
The organizations that understand this shift and design their annotation workflows accordingly will achieve scalable accuracy, cost efficiency, and sustainable governance in the next era of AI development.
For organizations building large-scale AI systems, the challenge is no longer just labeling data but designing intelligent quality control from the start. Platforms like Unitlab are built around this new reality, combining AI-assisted annotation, embedded QA automation, and structured human-in-the-loop workflows within a single enterprise-ready environment. By integrating automated validation with selective expert review, companies can scale faster, reduce operational costs, and maintain the level of accuracy required for high-impact AI deployments. In the era of hybrid annotation QA, the competitive advantage belongs to those who operationalize quality, not just measure it.
References
- Karim, M. M., et all.
Transforming Data Annotation with AI Agents: A Review of Architectures, Reasoning, Applications, and Impact. Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences. - Singh, S. (2022).
Manual or Automated Data Labeling: How to Decide? - Dayal, U.
Why High-Quality Data Annotation Still Defines Computer Vision Model Performance. - Saeeda, et all. (2025).
Data Annotation Quality Problems in AI-Enabled Perception System Development. arXiv:2511.16410. DOI:10.48550/arXiv.2511.16410. - Unitlab.
Unitlab: 100% Automated and Accurate Data Annotation, Dataset Curation, and Model Validation.