

Intoduction
High-quality annotations are the foundation of every successful computer vision model, yet as datasets grow in size and complexity, manual annotation quality assurance no longer scales effectively. Missed objects, inconsistent labels, and subtle annotation errors frequently pass through traditional review workflows, leading to degraded model performance, costly retraining cycles, and delayed deployment.
By 2026, AI agents are becoming a core part of modern software systems, and annotation workflows are evolving in the same direction. Annotation QA Agents are emerging as intelligent systems that continuously review annotations, detect inconsistencies, and correct or flag errors before they reach model training. This transforms datasets from static labeling outputs into self-improving assets that learn from past mistakes and maintain quality over time.
This shift represents a move from reactive quality checks to continuous, agent-driven dataset assurance, where annotation platforms such as Unitlab integrate QA intelligence directly into the data pipeline. By combining automated QA, human-in-the-loop review, and scalable annotation workflows, platforms like Unitlab enable teams to produce more reliable datasets faster, reduce operational costs, and build stronger computer vision models from the start.
In This Blog, We Cover:
- What Annotation QA Agents are
- Core Components of an Annotation QA Agent
- How Annotation QA Agents Work
- What Annotation QA Agents Do Not Replace
- Why Annotation QA Agents Matter in Production
- A Practical Annotation QA Use Case
What Are Annotation QA Agents?
Modern computer vision systems depend on precise and consistent annotations, but maintaining this level of quality becomes increasingly difficult as datasets grow in scale and complexity. The rapid progress of computer vision has been enabled by large-scale, high-quality, domain-specific datasets such as ImageNet, COCO, and Open Images, which established the foundation for modern visual recognition systems. As datasets continue to expand, ensuring reliable annotation quality has become a critical bottleneck.
An Annotation QA Agent is an autonomous or semi-autonomous system that continuously evaluates, validates, and improves labeled data by combining computer vision models, reasoning modules, policy logic, and human feedback within the annotation pipeline. Annotation QA Agents are AI-driven systems designed to ensure the quality and consistency of labeled data across the annotation lifecycle. Unlike traditional manual review processes, these agents provide continuous quality assurance by validating annotations and supporting human reviewers where needed. This approach makes annotation QA more scalable, consistent, and cost-effective for large computer vision projects.

By introducing intelligent automation into annotation pipelines, QA agents help teams enhance dataset reliability, minimize rework, and expedite model development—transforming annotation quality into a strategic advantage rather than a limitation.
Core Components of an Annotation QA Agent
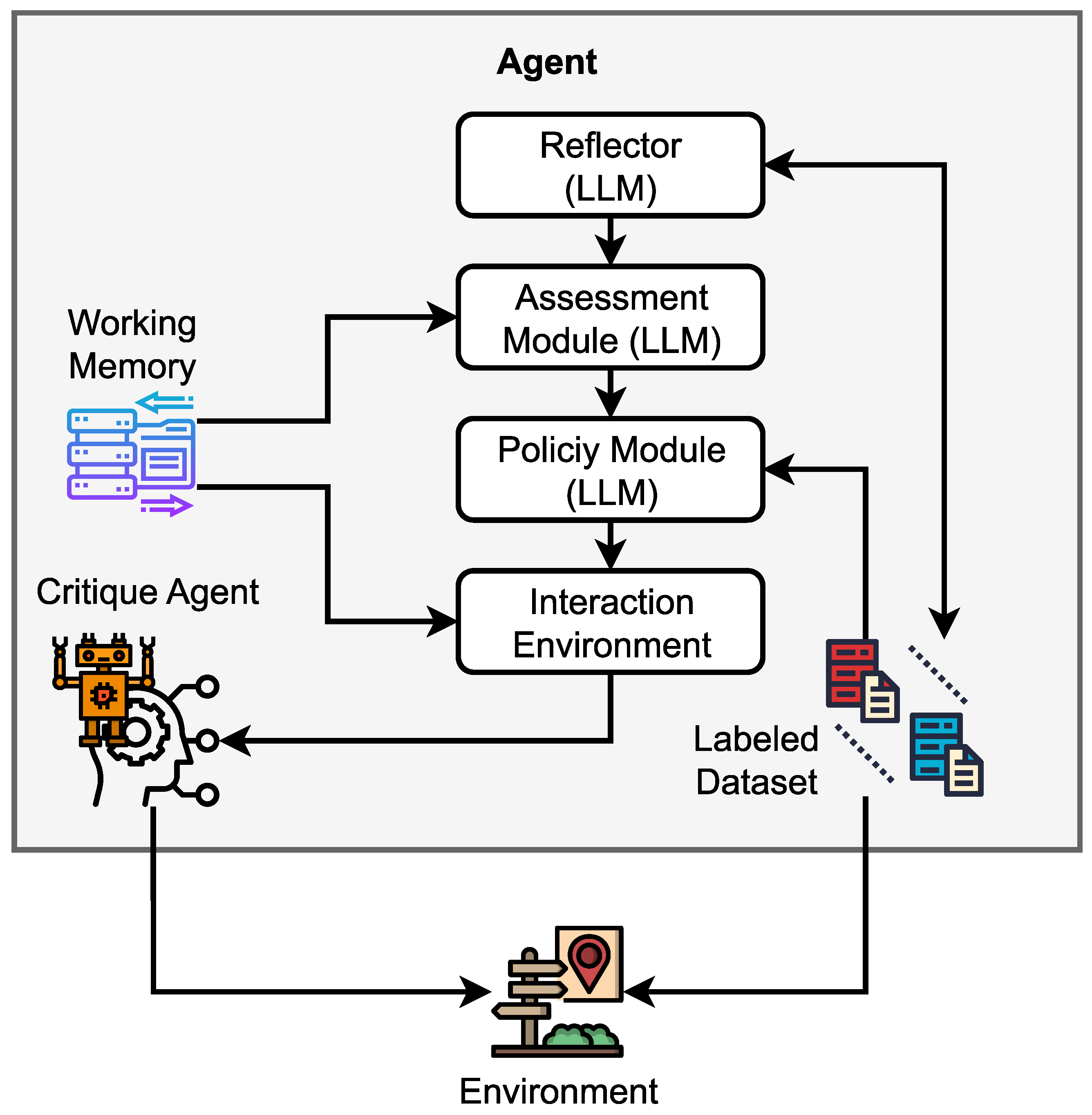
An annotation QA agent is not a single model or rule set, but a layered system composed of specialized components that work together to ensure annotation quality at scale. While implementations vary across platforms, most production-grade QA agents share a common architectural structure:
- Perception Layer
Responsible for analyzing raw visual data and existing annotations using computer vision models, heuristics, and statistical checks. This layer detects potential quality signals such as missing objects, misaligned bounding boxes, class inconsistencies, or low-confidence labels. - Reasoning Layer
Interprets detected issues by applying annotation guidelines, contextual understanding, and multi-step validation logic. This layer often combines rule-based validation with LLM-powered reasoning to handle ambiguous cases and domain-specific labeling conventions. - Policy and Confidence Control
Determines the appropriate response to detected issues based on confidence thresholds, uncertainty estimates, and risk tolerance. This component decides whether an annotation can be safely auto-corrected, should be flagged, or must be escalated for human review. - Action Layer
Executes decisions by applying corrections, generating QA flags, or routing samples to human annotators within the annotation workflow. This layer integrates directly with data annotation tools and labeling platforms. - Memory and Feedback Loop
Stores historical QA outcomes, human feedback, and downstream model signals. These signals are used to continuously refine agent behavior, enabling adaptation to new datasets, evolving guidelines, and emerging edge cases over time.
Images + Annotations
Perception Layer
(CV models, heuristics)
Reasoning Layer
(LLM + rules + context)
Policy & Confidence Ctrl
(thresholds, uncertainty)
Action Layer
(auto-fix / flag / route)
Annotation Tool / Human Review
Memory & Feedback Loop
(history, signals, logs)
Together, these components form a closed-loop quality assurance system that enables annotation QA agents to operate continuously, adapt to evolving data and guidelines, and maintain high annotation quality at production scale.
How Annotation QA Agents Work
Annotation QA agents operate as autonomous systems that follow a continuous cycle of perception, reasoning, action, and learning. In computer vision workflows, this means the agent continuously observes annotated images, evaluates label quality, takes corrective or routing actions, and adapts its behavior based on feedback from both machine learning models and human reviewers.
At the perception stage, the agent jointly analyzes visual data and existing annotations. It looks for common quality issues such as missing objects, inconsistent bounding boxes, class mismatches, label noise, or low-confidence annotations. These signals may come from vision models, heuristic rules, or statistical inconsistencies across the dataset.
Once potential issues are detected, the agent enters a reasoning and assessment phase. Here, LLM-powered modules interpret annotation guidelines, apply multi-step validation logic, and evaluate alternative interpretations of ambiguous cases. Rather than relying on rigid rules, the agent decomposes complex quality checks into structured steps, allowing it to handle edge cases, overlapping objects, or domain-specific labeling conventions more reliably.
Importantly, detecting an issue does not automatically result in correction. A dedicated policy decision stage determines the appropriate action: whether the annotation can be safely auto-corrected, should be flagged for review, or must be escalated to a human annotator. Confidence signals such as low model agreement, high uncertainty, or conflicting visual evidence play a key role in this decision-making process. The agent then acts within the interaction environment, applying corrections, generating quality flags, or routing samples to human reviewers. Corrections and reviewer feedback are captured and stored in working memory, along with downstream model signals such as training loss or prediction confidence.
Over time, this feedback is reused to refine the agent’s behavior. Patterns learned from past corrections allow the QA agent to adapt to new datasets, evolving annotation guidelines, and previously unseen edge cases with minimal retraining. This creates a closed feedback loop in which annotation quality improves continuously rather than being validated only at the end of the pipeline.
Together, these capabilities establish a new paradigm for agent-driven quality assurance in computer vision annotation where datasets are treated as living assets that are continuously monitored, corrected, and refined as models, tasks, and domains evolve.
What Annotation QA Agents Do Not Replace
Annotation QA agents are a powerful addition to modern data annotation workflows, but they are not a silver bullet. To deploy them effectively within a data annotation tool, data labeling platform, or enterprise data annotation platform, it is important to understand both their capabilities and their limitations.
Annotation QA agents are designed to augment annotation services companies, data annotation startups, and dataset labeling companies by embedding annotation QA automation directly into annotation pipeline automation. They improve consistency, scalability, and efficiency across image dataset labeling, video annotation outsourcing, 3D annotation services, and multi modal ML annotation workflows. However, they do not eliminate the need for human expertise, structured processes, or reliable annotation service providers.
In production environments using AI labeling tools, machine learning data labeling tools, or deep learning model labeling pipelines, QA agents act as an intelligent quality layer rather than a replacement for annotators, reviewers, or domain specialists. This distinction is especially critical for high-risk domains such as medical image labeling, LiDAR dataset labeling, geospatial image annotation, robotics dataset annotation, and industrial automation dataset preparation.
The table below summarizes the practical capabilities and limitations of annotation QA agents, clarifying where they add value and where human expertise and structured workflows remain essential.
| Category | Annotation QA Agents Can Do | Annotation QA Agents Cannot Do |
|---|---|---|
| Annotation Quality | Detect missing objects, box errors, and label noise | Guarantee perfect labels alone |
| Automation | Automate QA checks at scale | Fully replace human reviewers |
| Human-in-the-Loop | Route uncertain cases to humans | Eliminate domain experts |
| Tool Integration | Integrate with annotation and dataset tools | Fix poor labeling guidelines |
| Scalability | Scale QA across large datasets | Work without task setup |
| Model Feedback | Learn from model and reviewer signals | Replace training data providers |
| Modalities | Support image, video, OCR, and multimodal data | Generalize to all domains automatically |
| Robotics & Industry | Assist robotics and industrial vision QA | Replace robotics annotation expertise |
| Advanced CV | Work with SAM, SAM 2, and SAM 3 | Operate fully unsupervised |
Clearly defining what annotation QA agents do not replace helps teams deploy them correctly within data labeling solutions, data labeling outsourcing companies, and AI dataset creation services. Rather than competing with annotation service providers or computer vision outsourcing companies, QA agents strengthen their workflows by reducing rework, improving consistency, and focusing human effort where it adds the most value.
When used correctly, annotation QA agents become a force multiplier for computer vision annotation services, CV dataset creation, and enterprise-scale machine learning pipelines, ensuring that labeled datasets remain reliable, auditable, and production-ready as data volumes and task complexity continue to grow.
Why Annotation QA Agents Matter in Production
As computer vision systems move from experimental settings into real-world production environments, annotation quality emerges as a central determinant of system reliability. In production pipelines, datasets are no longer static collections created once and reused indefinitely. Instead, they evolve continuously as new data is collected, labeling guidelines change, and operational edge cases surface. Under these conditions, annotation errors introduced early in the pipeline can persist unnoticed and negatively affect model training, evaluation, and deployment.
Traditional annotation quality assurance workflows typically rely on manual spot checks, static validation rules, or one-time audits performed after labeling is complete. While such approaches may detect obvious errors, they are poorly suited to large-scale, evolving datasets. Prior research has shown that label noise and systematic annotation errors are difficult to detect using static QA methods and can significantly degrade downstream model performance if left unaddressed.
Annotation QA agents address these limitations by embedding continuous, adaptive quality control directly into the annotation lifecycle. Rather than treating QA as a final checkpoint, agent-based systems operate alongside annotation workflows, continuously assessing label consistency, detecting anomalies, and responding dynamically as new data is introduced. Recent studies demonstrate that iterative, feedback-driven quality assurance mechanisms lead to more reliable annotations and improved downstream model behavior compared to one-pass validation pipelines.

This example highlights how annotation errors are often subtle rather than overt. In the incorrect case, bounding boxes show inconsistent coverage and overlap despite correct class labels, introducing localization noise that can degrade model training. Continuous annotation QA is designed to surface and correct such inconsistencies before they propagate downstream.
A Practical Annotation QA Use Case
Annotation QA agents improve data quality by operating directly within the annotation workflow, rather than validating labels only after dataset creation is complete. In practice, these agents evaluate annotation outputs generated by data annotation tools, AI-powered labeling software, and automated image labeling tools, checking for geometric consistency, coverage accuracy, overlap anomalies, and confidence mismatches. This continuous assessment enables early detection of quality issues that are difficult to identify through manual spot checks alone.
Research on label noise has shown that undetected annotation errors can systematically bias model training and evaluation, even when datasets appear visually correct. By introducing automated, confidence-aware QA into the labeling process, annotation QA agents help surface these hidden inconsistencies before they propagate into downstream machine learning pipelines.
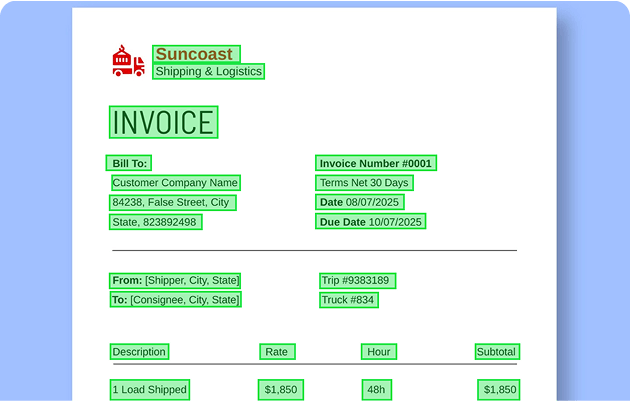
A representative example can be seen in logistics and warehouse workflows, where computer vision annotation tools are used for image dataset labeling, OCR annotation, and text detection annotation on shipping boxes. In platforms such as Unitlab, these pipelines rely on object detection labeling tools, bounding box labeling tools, and polygon annotation tools to prepare high-quality training data for automation systems used in sorting, inventory management, and warehouse robotics.

In this context, annotation QA agents continuously validate outputs from training data labeling tools by identifying low-confidence detections, incomplete or poorly aligned bounding boxes, and inconsistent label definitions. Ambiguous cases such as partially occluded labels or damaged packaging are selectively escalated through human-in-the-loop annotation platforms, ensuring that human review is applied only where it provides the greatest value. This selective escalation strategy is well supported by active learning research, which shows that prioritizing uncertain samples significantly improves labeling efficiency.
Conclusion
As machine learning systems move into production, the importance of reliable data annotation tools and data labeling platforms continues to grow. Modern data annotation for machine learning requires more than static checks; it depends on continuous quality control, scalable coordination, and close integration with model development. This is especially critical for image dataset labeling, computer vision annotation, and multi-modal ML annotation, where subtle inconsistencies can significantly impact downstream performance.
Annotation QA agents address these challenges by embedding annotation QA automation directly into labeling workflows. Working alongside auto annotation tools, AI-powered labeling software, and training data labeling tools, they enable annotation workflow automation and scalable annotation workflows while preserving accuracy through human-in-the-loop annotation platforms. This approach allows teams using data labeling and annotation services or data labeling outsourcing companies to maintain consistent quality across growing datasets and distributed annotation teams.
Platforms such as Unitlab illustrate how this model can be implemented within an enterprise data annotation platform, combining dataset management platforms, AI-accelerated annotation tools, and annotation workforce management. By supporting diverse use cases from object detection, labeling, and OCR annotation to robotics dataset annotation, geospatial image annotation, and medical imaging annotation, agent-driven QA systems help transform labeled data into reliable, production-ready assets. As demand for high-quality training data continues to expand, intelligent annotation QA will remain a foundational component of scalable computer vision and machine learning pipelines.
References
LABELING COPILOT: A Deep Research Agent for Automated Data Curation in Computer Vision
Analyzing Dataset Annotation Quality Management in the Wild
Can Vision-Language Models Replace Human Annotators: A Case Study with CelebA Dataset
![Multimodal AI in Robotics [+ Examples]](/content/images/size/w360/2026/01/Robotics--12-.png)
