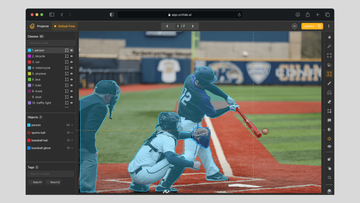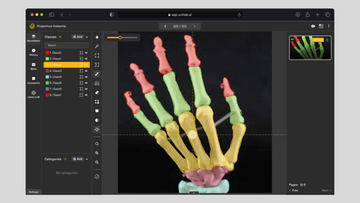
Image annotation is the foundation of computer vision model development, serving as the critical first step in the AI/ML pipeline. The quality of your model hinges on the quality of your data labeling. Garbage in, garbage out.
11 Factors in Choosing Image Annotation Tools | Unitlab Annotate
Because every AI/ML model has its own requirements, there are various types of image annotation. There isn’t one universal “best” type, only the right one for the job. In fact, in our data annotation platform selection post, we highlighted that the image annotation type is the single most important deciding factor.
Earlier this year, we covered 10 types of image annotation to help you make the right choice. Now, we’ll dive deeper into skeleton annotation. To illustrate how it works in practice, we’ll discuss using it on Unitlab Annotate, our collaborative, AI-powered image labeling tool, complete with real examples and practical tips.
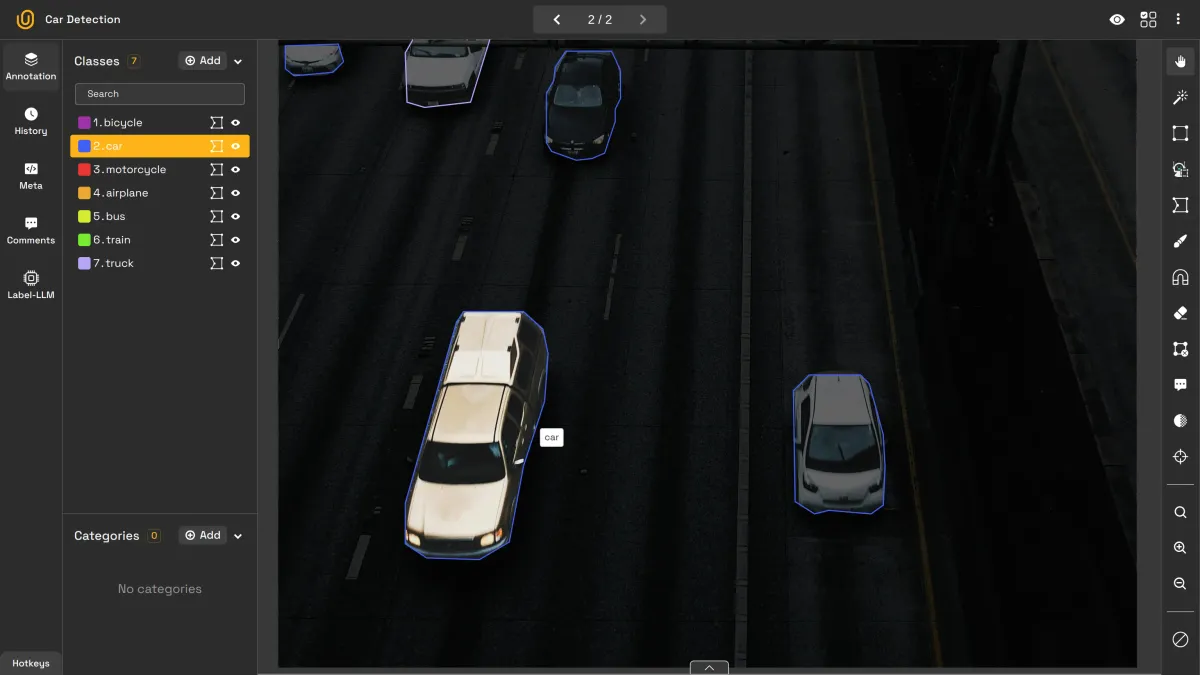
Image Annotation Types & Applications | Unitlab Annotate
Introduction
Skeleton annotation is a type of image annotation that converts complex visual data into linear frameworks. Most are familiar with bounding boxes or polygons; they outline the perimeter of the object.
In other words, these methods draw boxes or polygons around the objects of interest. Skeleton annotation, on the other hand, draws lines inside the object to reveal its core structure, almost like a blueprint of the building.

Because of its specialized nature, skeleton annotation is less common than standard approaches. Still, it’s the method of choice whenever you need to trace an object’s detailed trajectory or underlying framework.
Practical Use Cases
- Healthcare: Trace bone structures in X-rays or vascular systems in angiograms for better diagnoses and treatment plans.
- Autonomous Vehicles: Mark road boundaries, lane lines, and obstacles to enhance navigation in self-driving cars.
- Robotics: Identify the structural features of objects to improve a robot’s grasping and manipulation capabilities.
- Sports and Biomechanics: Estimate human poses accurately to evaluate athletic performance or prevent injuries.
- Agriculture: Outline plant structures or root systems, enabling automated crop monitoring and yield predictions.
Learn how to register, create your workspace, and create your project with this post.
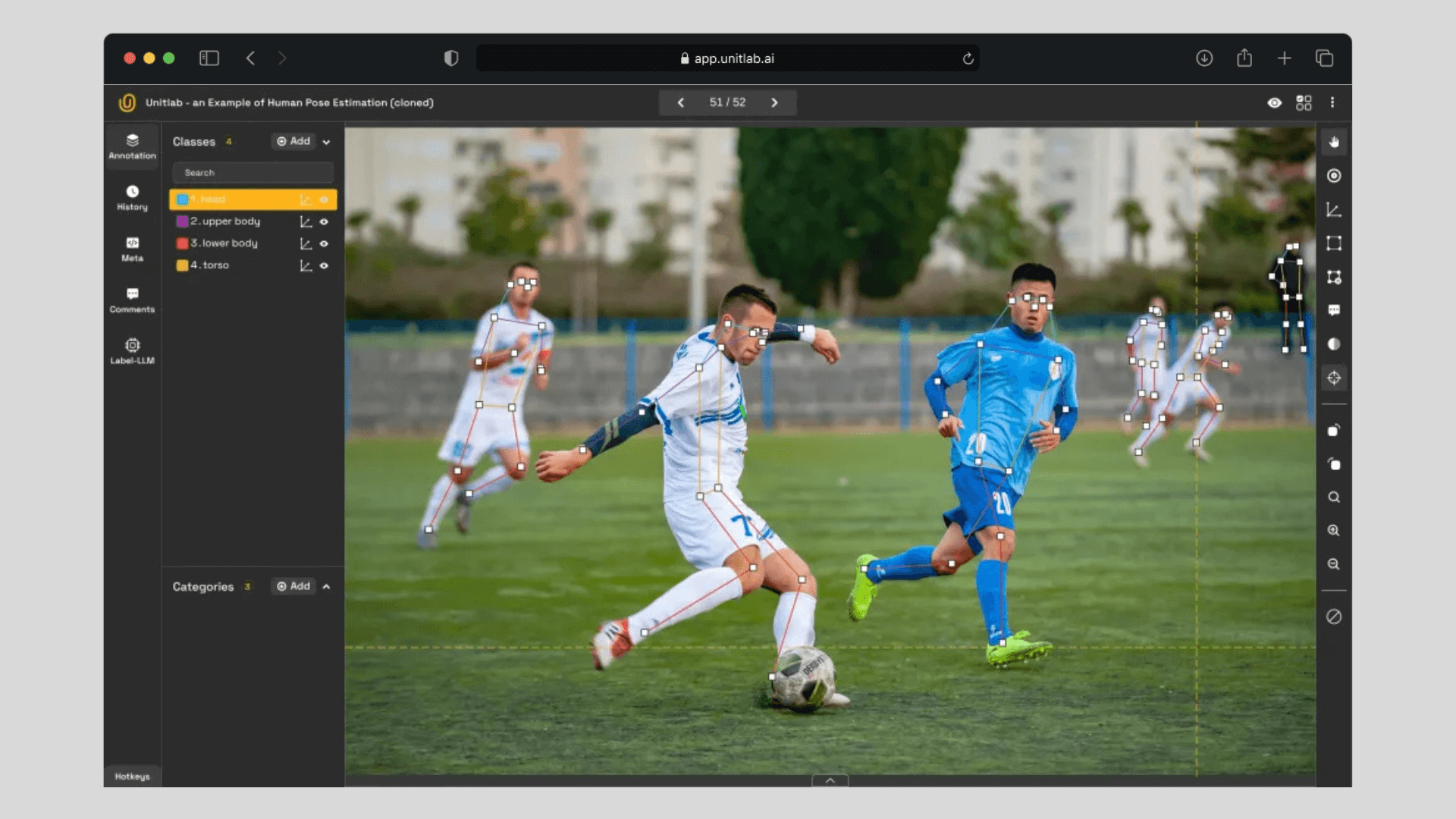
Manual Annotation
Manual annotation is the traditional and most accurate way to label image skeletons. Here, a human annotator carefully places key points or lines, guided by expertise and real-world context. This approach is especially useful when precision and domain knowledge are essential, such as in medical imaging.
Humans, however, are slower than machines and not always consistent. Labor costs can be high, and projects may take longer to complete due to corrections and other human factors. At the same time, human insight is crucial for tasks that are too complex or nuanced for fully automated systems.
Manual Image Skeleton Annotation | Unitlab Annotate
Features of Manual Skeleton Annotation
- Human Expertise: Domain experts can pick up subtle details (like tiny fractures in bone X-rays) that automated processes might miss.
- Customizability: Manual tools allow annotators to adjust skeleton structures, place points more precisely, and correct errors on the fly.
- Flexibility: Perfect for diverse data types, from action shots of human poses to satellite imagery of roads.
Challenges of Manual Skeleton Annotation
- Time-Consuming: Manually annotating large datasets is labor-intensive and slow.
- Costly: Paying skilled annotators raises expenses, especially for specialized tasks that require domain expertise (i.e. medical images).
- Potential for Human Error: Even experts occasionally make mistakes under pressure, particularly with complex or high-volume datasets.
Despite these drawbacks, manual annotation remains crucial wherever accuracy and context truly matter. In your high-stake skeleton annotation pipelines, it is unwise to cut human annotators from the image labeling pipeline.
Auto Annotation
Automated image annotation solutions offer speed, consistency, and a lower price for large-scale image labeling projects. With data auto-annotation, machines can label large datasets in remarkably short periods. Pre-trained models and advanced computer vision algorithms can truly accelerate the process, saving time and effort.
However, auto-annotation stumbles when dealing with nuanced or ambiguous skeleton annotation tasks. AI-powered image annotation excels at straightforward object detection or segmentation.
However, this automated tool might miss intricate details might be missed without sufficient domain-specific training, at least in this stage of AI development. Still, auto skeleton labeling provides a robust first result that human annotators can refine according to their expertise and team guidelines.
Auto crop-annotation with Image Skeleton | Unitlab Annotate
If your projects and requirements are so bespoke that you have developed your own AI solutions for image labeling, you can integrate your own models with data annotation platforms in order to leverage the vendor platform.
Features of Auto Skeleton Annotation
- Efficiency: Automated systems can process hundreds or thousands of images in a fraction of the time manual annotators would need.
- Consistency: Machines apply the same logic across an entire dataset, reducing variability in labeling.
- Scalability: Easy to expand to larger datasets without significantly increasing the time or labor needed.
Challenges of Auto Skeleton Annotation
- Accuracy Limitations: Ambiguous or complex images can lead to errors or incomplete annotations.
- Dependency on Training Data: If the underlying model is poorly trained or not fine-tuned for your exact use case, annotation quality will suffer.
- Limited Flexibility: Complex, contextual decisions often require human intervention.
Auto skeleton annotation is particularly effective when used as a complementary tool to manual methods. Annotators can utilize automated outputs as a baseline, refining and correcting them for improved accuracy. This synergy speeds up labeling without sacrificing quality, also known as 'hybrid annotation' or the 'human-in-the-loop' approach.
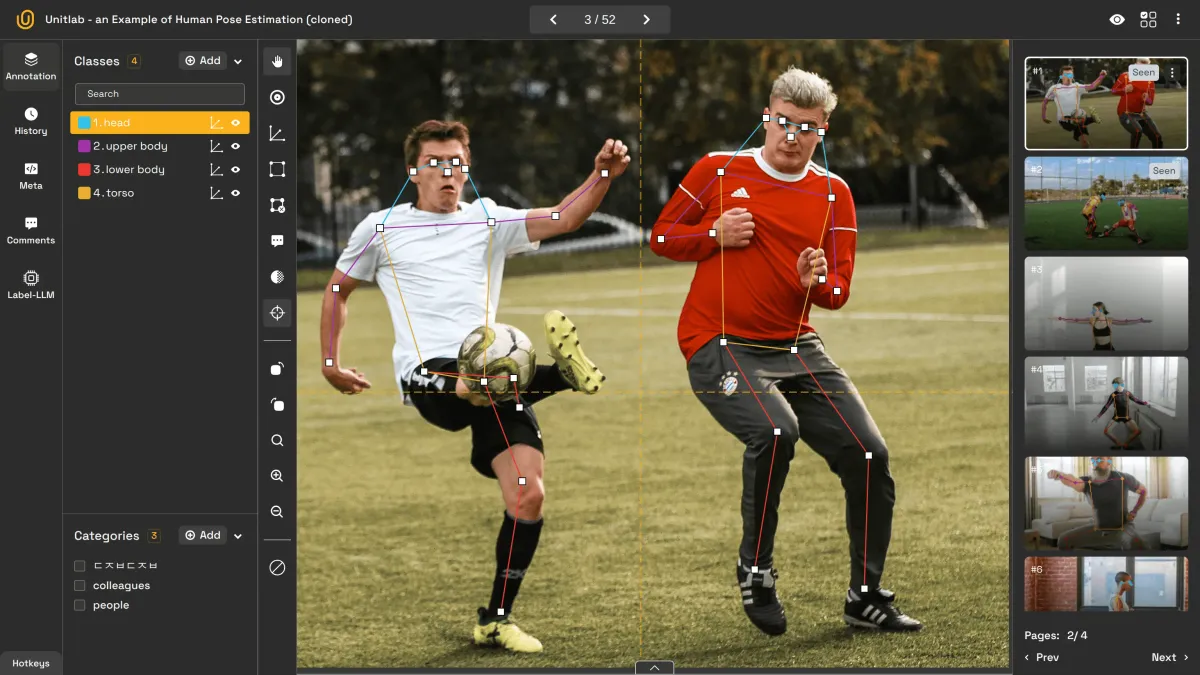
Hybrid Annotation
If a human annotator and a auto-annotation model both have advantages and disadvantages in annotating image skeletons, why not combine the best of the two? A hybrid approach combines the best qualities of manual and automated methods.
First, an automated tool attempts to annotate images. Next, human annotators correct and improve those results, adding the context and adaptability that machines can’t fully match. Finally, a reviewer ensures all guidelines are met for maximum consistency.
Offered as a core feature in Unitlab Annotate, this approach addresses the key pain points of both manual and automated labeling, giving you and your team a quick turnaround without sacrificing precision and quality. It’s ideal for projects that require scalable solutions but can’t compromise on quality.
This is how Unitlab Annotate can "accelerate data annotation by 15x and minimize costs by 5x using advanced auto-annotation tools."
Hybrid Approach with Image Skeleton | Unitlab Annotate
Conclusion
Skeleton annotation provides a blueprint-like view of objects, making it indispensable wherever structural details matter. Manual methods offer contextual accuracy, while auto labeling solutions streamline workflows and deliver consistency. A hybrid approach truly brings out the best of both, creating a fast, flexible, and high-quality pipeline.
Whether you need to outline road networks for autonomous driving or trace neural pathways in medical imaging, skeleton annotation, backed by the right combination of tools and expertise, empowers your AI/ML models to perform at their best in real-world settings. The hybrid approach offered by Unitlab Annotate can speed up the process and improve quality of your datasets at the same time.