When training computer vision models, data collection and annotation represent the most critical initial steps, as the data in these ML datasets fundamentally defines the model. In essence, the quality of any AI or machine learning model depends on the training and testing data, often encapsulated by the phrase “garbage in, garbage out.”
Because the dataset directly affects model performance, it must be handled with great care. Building computer vision models on weak or flawed datasets is rarely fruitful. Imagine living in a house with a crumbling foundation; the risk would outweigh any perceived convenience. Similarly, high-quality, well-annotated datasets minimize false positives and improve model generalization.
Conversely, poorly prepared datasets limit a model’s potential, regardless of the extent of fine-tuning. Unfortunately, numerous errors introduced by data practitioners can undermine a model’s effectiveness without their realizing it. This post highlights eight frequent mistakes in dataset preparation and offers practical ways to address them.
By the end of this post, you will learn:
- Why datasets are crucial
- What a dataset actually is
- Two categories of dataset mistakes
- Eight common mistakes
What is a dataset?
In this post, we explain at length how data collection and data annotation form the bedrock of any AI or machine learning endeavor, including computer vision. The term “dataset” is broad, encompassing the collection, annotation, and organization of training, validation, and testing data. Essentially, the dataset is the entire process by which data is managed and refined for use in AI/ML modeling.
The errors commonly seen within a dataset tend to emerge either during data collection or data annotation. Since these phases establish the foundation on which all subsequent processes depend, it is critical that teams approach them with diligence. We divide these mistakes into two categories:
- Mistakes during data collection
- Mistakes during data annotation
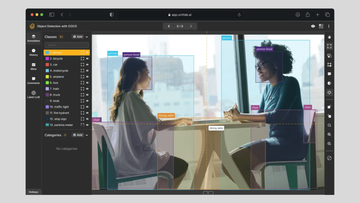
For illustration, we focus on object detection models, one of the most widely applied categories of computer vision models across multiple industries.
Car Detection with Bounding Boxes | Unitlab Annotate
Data Collection Mistakes
1. Insufficient Data Quantity
- Mistake: A common principle is “the more data, the better.” Although this is not always strictly true (factors like diversity and balance also matter) a well-balanced, diverse, and substantial dataset generally performs better than a small one of similar diversity and balance.
- Impact: An object detection model trained on a small dataset is vulnerable to overfitting. It may achieve high accuracy on training (and possibly even test) data, yet fail when presented with new examples. Such models often end up with impressive metrics but little real-world applicability. Put simply, you get an accurate, yet useless computer vision model.
- Solution: For object detection, collect as many images or video frames as is feasible to capture different real-world variations. If there is an upper limit (for instance, in medical imaging), try to approach that maximum.
2. Lack of Diversity in Data
- Mistake: Diversity is a buzzword that is used way too much in too many contexts, but for datasets, it is a mistake not to ensure diversity. Even large datasets can be narrow in scope if they lack diversity. When training a model on only one subset of potential conditions or perspectives, its predictive power diminishes in all other scenarios. Since AI and machine learning models depend on identifying patterns, diversity is vital for capturing a realistic array of features and conditions.
- Impact: The model may perform well for the data it was shown but flounder in novel or unexpected contexts. An object detection system trained on homogeneous data often suffers in complex, dynamically changing real-world environments.
- Solution: Include images from various settings, angles, lighting conditions, and weather scenarios. If you are creating an inventory management system with computer vision for a tech warehouse, ensure the dataset incorporates different types of tech equipment. This greater variety generally leads to better model accuracy and generalization.
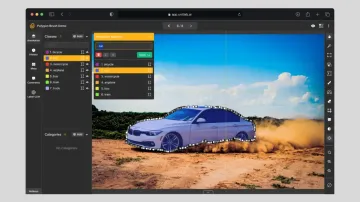
3. Imbalanced Class Distribution
- Mistake: Even a large, diverse dataset can be skewed if certain classes appear much more frequently than others. In a parking lot monitoring scenario, for example, cars might far outnumber trucks, buses, and bikes. The result is a model that excels at detecting cars but struggles with other vehicle types.
- Impact: The model’s performance suffers when attempting to recognize less common objects, causing biased predictions and poor recall. Generally, most cars are parked right within the boundaries, while from time to time some cars aren't. With imbalanced datasets, we run the risk of AI model identifying the majority of cars being parked right, while, in reality, some aren't.
- Solution: Seek to balance the dataset either by collecting more samples of underrepresented classes or by reducing overrepresented ones. Techniques such as oversampling or generating synthetic data can help mitigate class imbalance.
4. Poor Image Quality
- Mistake: If you are having difficulty understanding the image or the video frame, the machine will have a lot of difficulty understanding and making sense of the data. Blurry, low-resolution, or poorly lit images can prevent the model from learning essential visual details. Since images are essentially matrices of pixels, inadequate quality restricts the model’s capacity to discern and classify objects, especially in crowded or cluttered scenes.
- Impact: Even if data collection is thorough and annotations are accurate, low-quality images degrade detection outcomes. A model trained on suboptimal images frequently misclassifies objects due to missing or distorted visual features.
- Solution: Verify that all collected images are in focus, well-lit, and of adequate resolution. Consider using preprocessing techniques such as contrast enhancement or noise reduction to make the images clearer before training.
5. Lack of Data Augmentation
- Mistake: Neglecting augmentation, such as rotation, scaling, or brightness adjustment, limits the variety of data the model can learn from. Real-world scenarios often involve shifts in perspective, changes in illumination, or other perturbations that a model should be robust against.
- Impact: A model trained on unaugmented data may falter in the face of everyday variations in lighting or orientation. This lack of robustness can cause significant errors in live environments.
- Solution: Apply realistic augmentations that mirror situations the model may encounter in deployment. Flipping, cropping, rotating, and adjusting brightness levels can boost the model’s resilience to variations. However, ensure that augmentations align with the real-world conditions in which the model will operate.
Data Annotation Errors
1. Incorrect Dataset Splitting
- Mistake: Allowing overlap among training, validation, and test sets leads to inflated performance metrics. When identical or highly similar images appear across these sets, the model’s validation accuracy or loss does not accurately reflect real-world performance.
- Impact: The model may appear to perform exceptionally in validation tests but fails to generalize once deployed, indicating it overfits to the training data.
- Solution: Rigorously separate training, validation, and test datasets. Consider using stratified sampling to ensure each set remains representative of the entire data distribution.
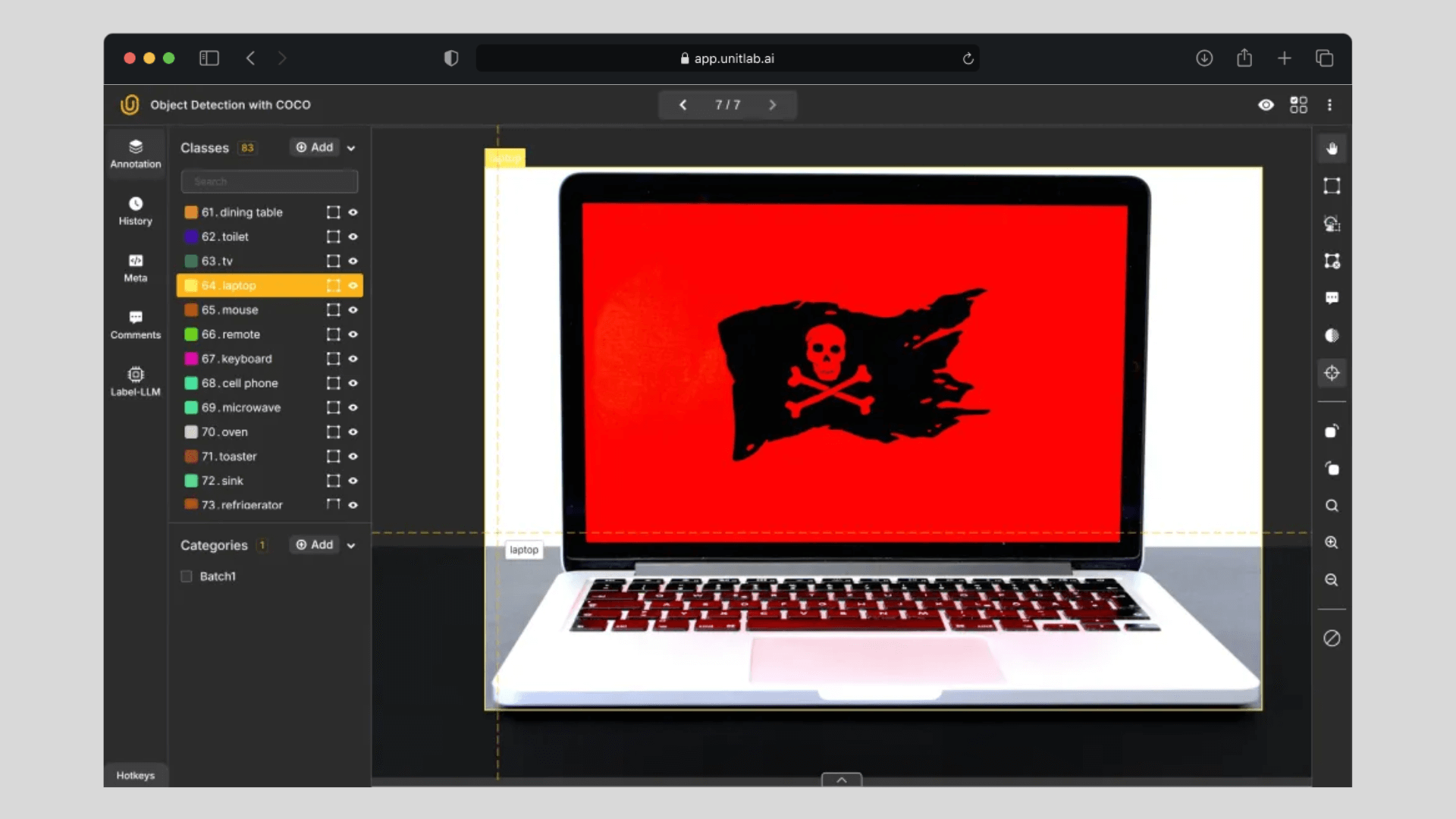
2. Inaccurate or Inconsistent Labeling
- Mistake: This mistake is very, very wide: entire startups, jobs, and industries have emerged to solve this issue. This issue is full of trade-offs: accurate and consistent labeling requires a lot of investment and resources. However, we need high-quality datasets to develop AI/ML models to solve a real-world issue and make a profit. How do we achieve high-quality datasets with reasonable time and monetary resources? In fact, our entire blog is devoted to this multi-faceted problem.
- Impact: Inaccurate annotations lead to misleading training feedback, lowering accuracy and inflating false detection rates.
- Solution: Implement strict annotation guidelines and conduct repeated quality checks. Automated tools can help, but human oversight is crucial to ensure uniformity. Practically, at this stage of AI/ML development, you most likely need to choose and use a data annotation platform.
How Unitlab AI Aims to Transform Data Annotation | Unitlab Annotate
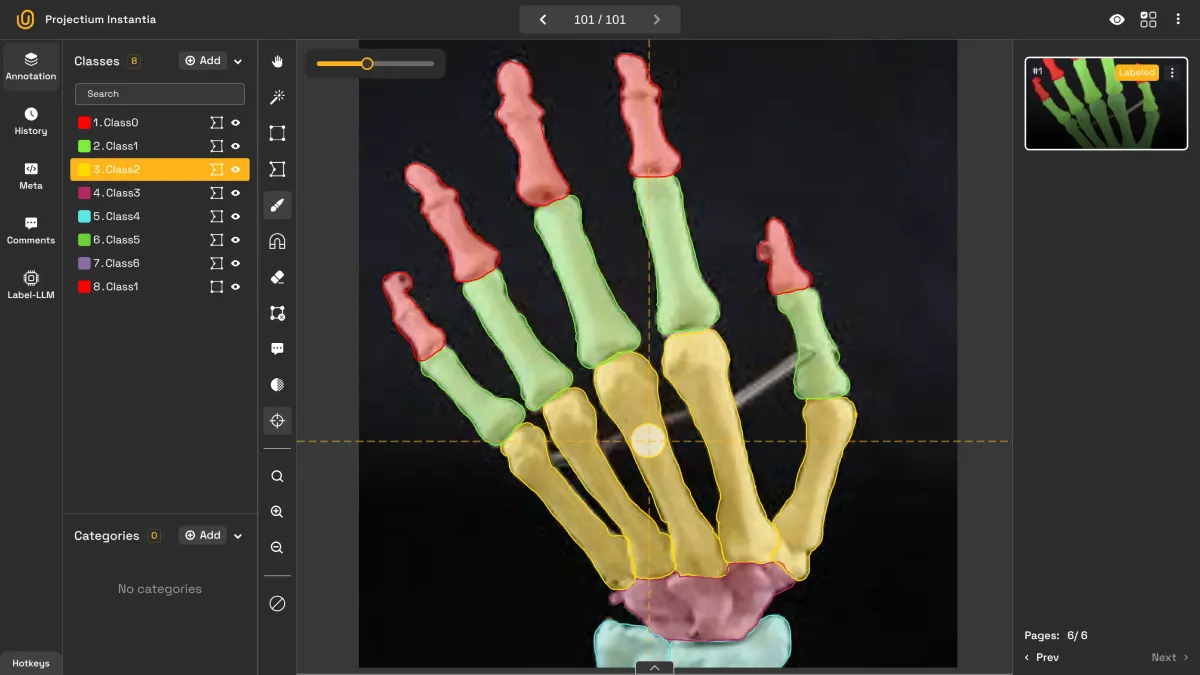
3. Ignoring Occluded or Partial Objects
- Mistake: Failing to label partially visible or occluded objects, such as those hidden behind other objects or captured in reflections, limits the training data’s realism. Models in many real-world applications will encounter partially visible objects, yet these cases often go unlabeled.
- Impact: The model may not learn to detect objects unless they are entirely unobstructed. This limitation can severely reduce efficacy in domains such as surveillance or retail analytics, where partial visibility is common.
- Solution: Annotate occluded and truncated objects consistently so the model recognizes them in similar situations. Label partial objects as though they were fully visible, allowing the model to adapt and generalize properly.
Labeling Occluded Objects | Unitlab Annotate
Conclusion
The term “dataset” encompasses data collection, data annotation, and data management. It serves as the main repository for training, validation, and testing images used in building AI/ML models. Because the dataset is the foundation for model success, it should be assembled and prepared with meticulous attention to detail.
This post has outlined common dataset mistakes related to both data collection and data annotation. While rectifying or preventing these errors can require significant resources, it ultimately provides far more value than suffering through an inaccurate and impractical computer vision model. Addressing these pitfalls helps ensure your model rests on a solid, robust foundation.
Explore More
- 7 Tips for Accurate Image Labeling
- Importance of Clear Guidelines in Image Labeling
- Top 10 Computer Vision Blogs
References
- Benjamin Obo Tayo (Sep 10, 2020). 6 Common Mistakes in Data Science and How To Avoid Them. KD Nuggets: Source
- Cogito Tech. (Apr 19, 2023). Object Detection: 8 Top Dataset Mistakes and How to Fix Them. Cogito Tech: Source