In Part I of this series, we explored the first 25 essential computer vision terms—covering foundational ideas like AI and machine learning, as well as core metrics like IoU and F1 score.
50 Essential Computer Vision Terms (Part I) | Unitlab Annotate
This second part continues with 25 more terms commonly encountered in computer vision—especially in areas like data annotation, image labeling, object detection, and real-world deployment. These entries include annotation types, file formats, data challenges, and emerging tools like SAM and synthetic data.
Whether you're preparing datasets, developing models, or managing labeling workflows, understanding these terms will help you work more effectively across teams and systems.
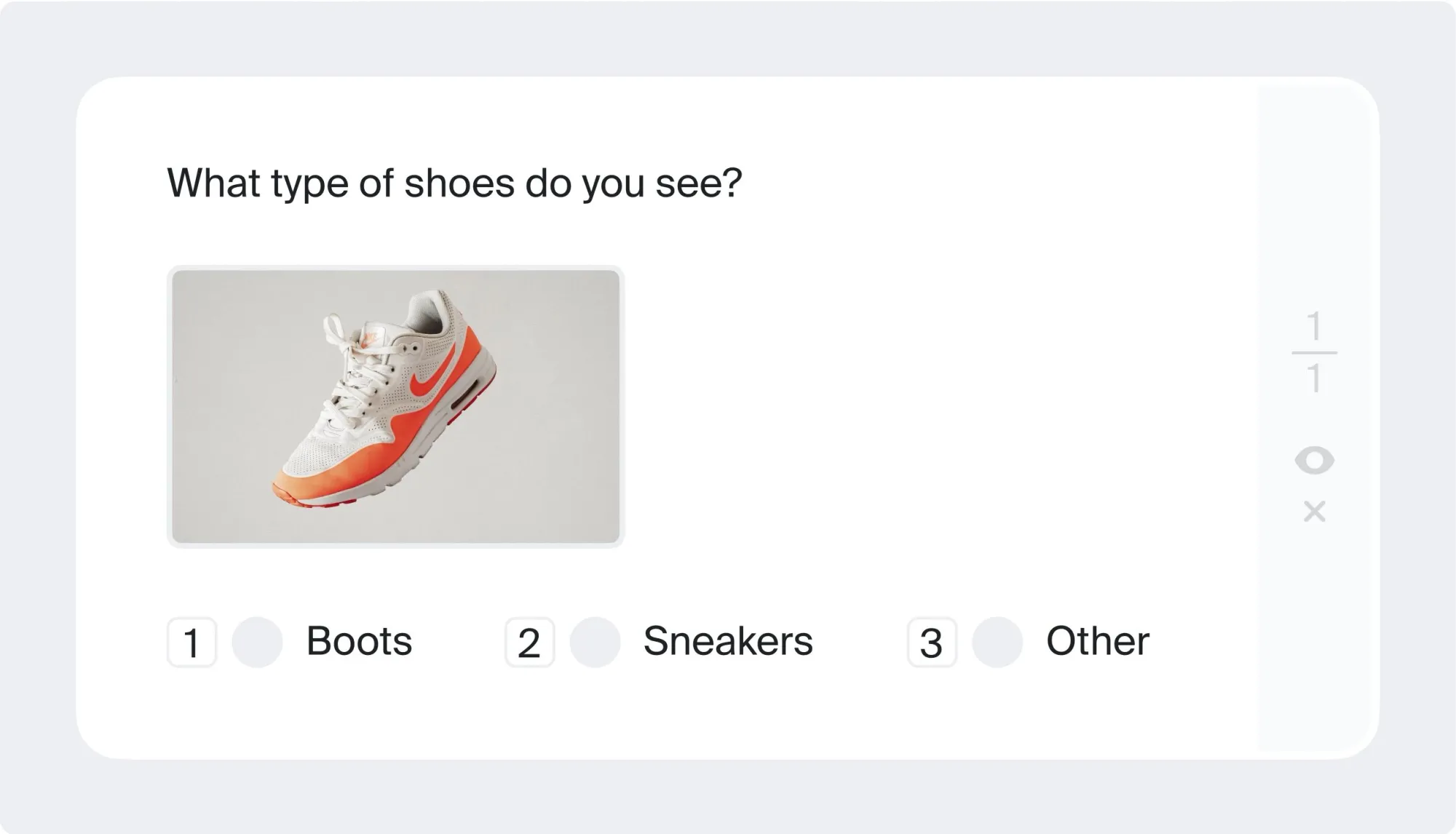
26. Classification
Image classification assigns a single label to an entire image. It answers the question: What is this image about? Examples include determining whether an image contains a cat or a dog, or identifying a product category in retail.
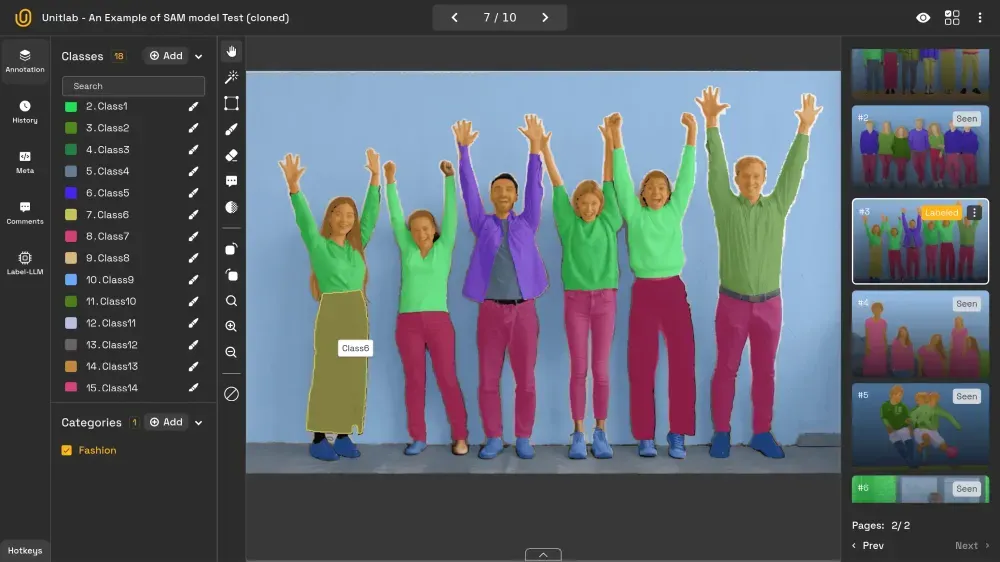
27. Segmentation
Segmentation, also known as semantic segmentation or pixel-perfect labeling, involves assigning a label to every pixel in an image. This divides the image into regions that correspond to different objects or categories.
Unlike object detection, which focuses on locating objects, segmentation works at the pixel level and is essential for detailed tasks such as medical imaging or autonomous vehicle scene analysis.
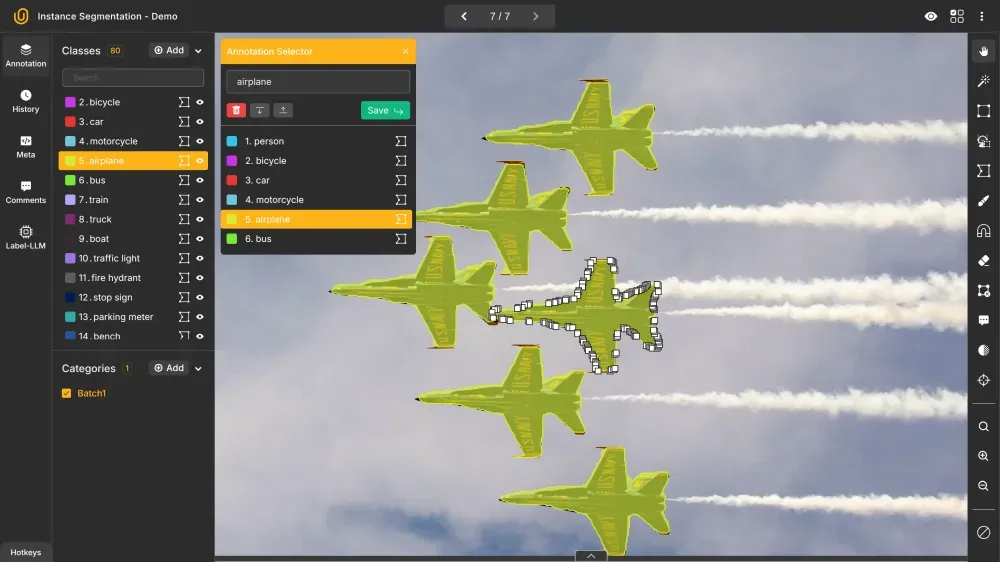
28. Instance Segmentation
Instance segmentation builds on semantic segmentation by distinguishing between individual instances of the same object class. While semantic segmentation treats all objects of the same class identically, instance segmentation keeps them separate.
For example, two people in the same image would each be segmented individually, even though they both belong to the "person" class.
Vehicle Detection Demo | Unitlab Annotate
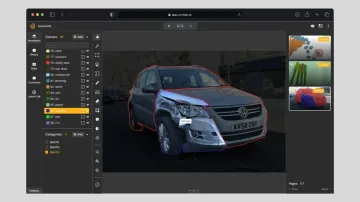
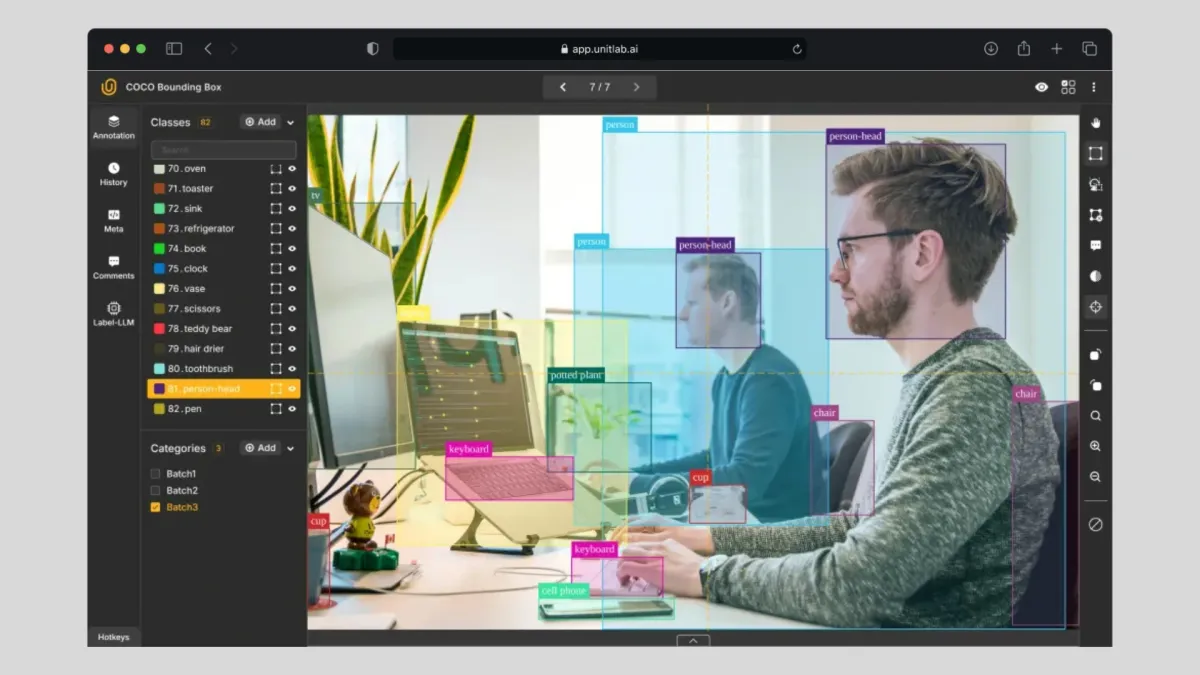
29. Object Detection
Object detection identifies and classifies objects within an image, typically by drawing a bounding box and assigning a label to each. While similar to instance segmentation, object detection is generally less precise due to its reliance on rectangular boxes.
That said, bounding boxes are simple, intuitive, and widely adopted for real-world tasks such as vehicle tracking, product detection, and pedestrian monitoring.
30. OCR
OCR (Optical Character Recognition) is the process of detecting and extracting text from images. Common applications include digitizing printed documents, reading license plates, and extracting text from scanned legal or banking records.
OCR plays an essential role in computer vision by enabling systems to interpret and act on textual content embedded in images.

31. Bounding Boxes
Bounding boxes are rectangular boxes drawn around objects to indicate their position. This is the most common form of object annotation used in detection tasks.
More advanced use cases include rotated bounding boxes, which add an angle parameter for improved accuracy around tilted or irregularly oriented objects.
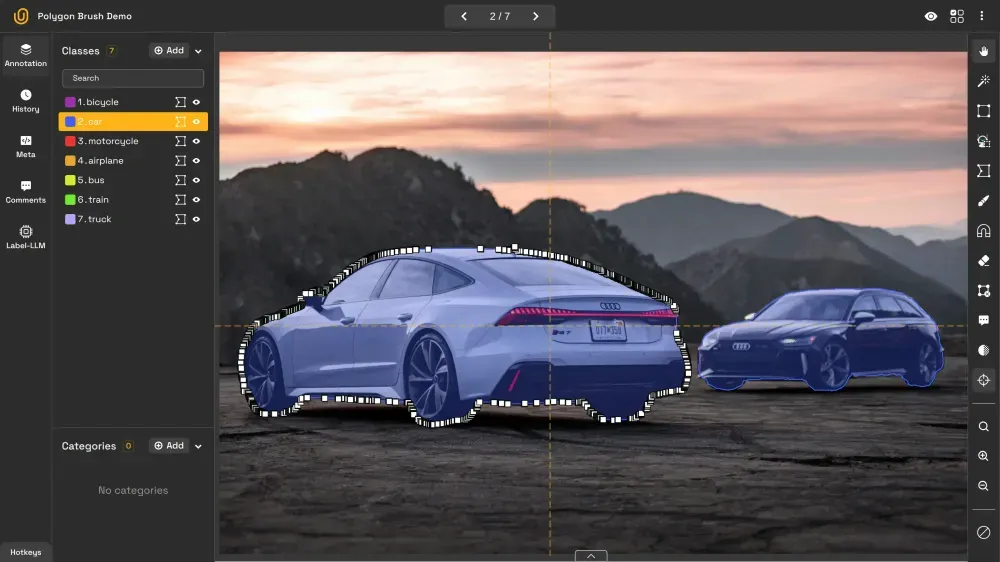
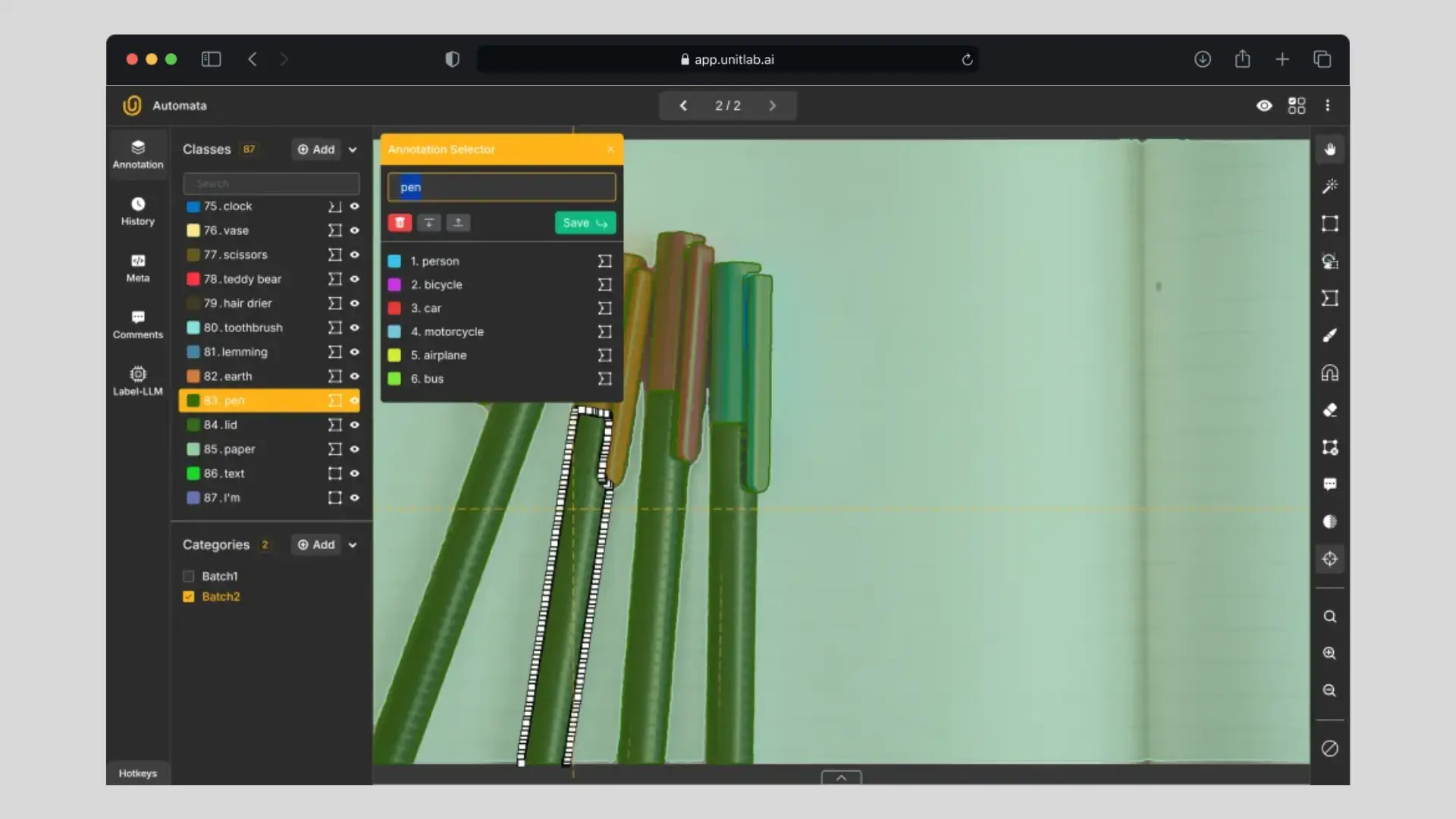
32. Polygons
Polygon annotation allows for precise outlining of object boundaries by connecting multiple points. This method is especially useful for objects with irregular shapes that cannot be accurately captured by rectangles.
Because of this precision, polygons are frequently used in instance segmentation tasks.

33. Polylines
Polylines are open shapes formed by connecting a series of points with straight lines. Unlike polygons, they do not close into a loop. Polylines are used to label road lanes, borders, and paths—particularly in transportation, mapping, and geospatial applications.
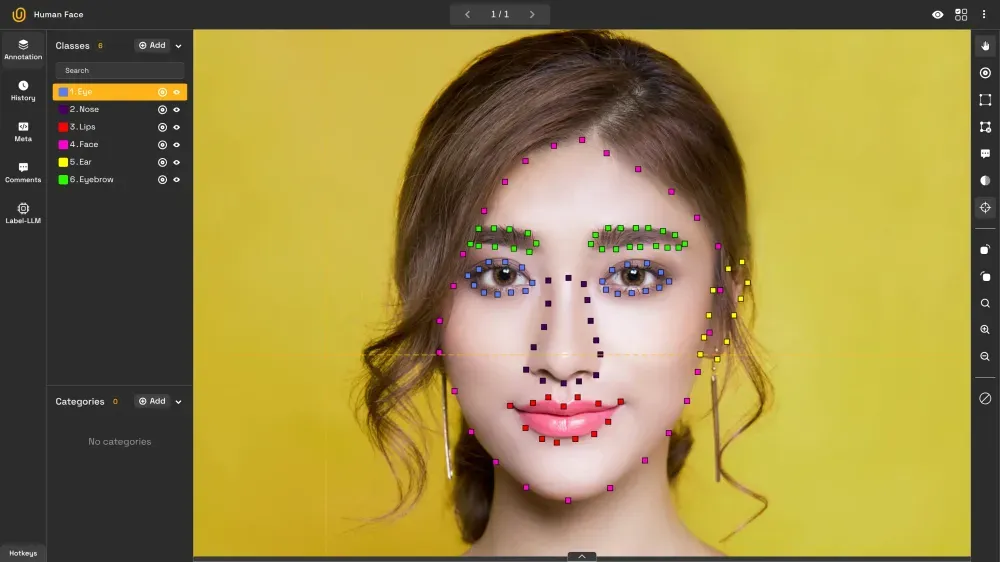
34. Keypoints
Keypoints are specific coordinates within an object that highlight important locations—such as facial landmarks, hand joints, or tool tips. Bounding boxes or polygons draw annotations around the object of interest, while skeletons draw inside to mark specific locations.
This type of annotation is especially useful in gesture recognition, facial analysis, and robotics.

35. Human Pose Estimation
Pose estimation identifies the positions of human joints and connects them to estimate body posture. It relies on internal keypoints—like shoulders, elbows, knees—and maps them into a skeletal model.
Applications include motion tracking in sports, rehabilitation programs, and interactive systems.
LiDAR Example | Mark Rober
36. LiDAR
LiDAR (Light Detection and Ranging) is a remote sensing technology that uses lasers to measure distances and build 3D maps of environments. It emits pulses of light in all directions and calculates distances based on return time.
LiDAR is widely used in self-driving vehicles and drones to develop the map of the environment in real-time, and usually better than cameras alone, as shown in the video above.
37. Point
Point annotation involves marking a single pixel or coordinate to represent the presence or center of an object. This is useful in scenarios like crowd counting or key feature localization, where full outlines are unnecessary.
It’s a minimalist yet powerful form of annotation when accuracy at a single location is enough.
38. Data Annotator
A data annotator is a specialist who prepares labeled data for machine learning, particularly in supervised learning tasks. They follow detailed instructions to ensure consistency and quality in the labeled dataset.
In computer vision, annotators use tools to draw boxes, assign labels, trace outlines, and validate AI-generated labels.
Data Annotator Role Overview | Unitlab Annotate
39. Manual Annotation
Manual annotation refers to data labeling performed entirely by human annotators. While labor-intensive, it offers high-quality results and is often used to create ground-truth datasets.
Due to the volume of data needed for modern ML, manual annotation is often reserved for critical or complex samples.
Medical Image Labeling with SAM Model | Unitlab Annotate
40. SAM (Segment Anything Model)
The Segment Anything Model (SAM), developed by Meta AI, is a foundational segmentation model that can label objects in any image with minimal input.
SAM supports diverse domains and reduces the time required for manual labeling. It represents a major step forward in interactive and automatic image segmentation. Above is the example of annotating a medical hand image with SAM.
41. Automatic Annotation
Automatic annotation leverages pre-trained models to label data automatically. It greatly accelerates dataset creation, especially for large-scale projects.
While fast, these labels often lack the domain-specific accuracy of human annotators and typically require review and refinement.
42. Hybrid Annotation
Hybrid annotation combines automatic tools with manual oversight. The system produces initial labels, which are then corrected or enhanced by human annotators.
This workflow balances efficiency and quality and is the most common setup in production data labeling pipelines.
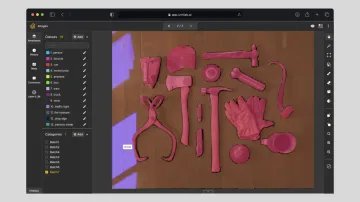
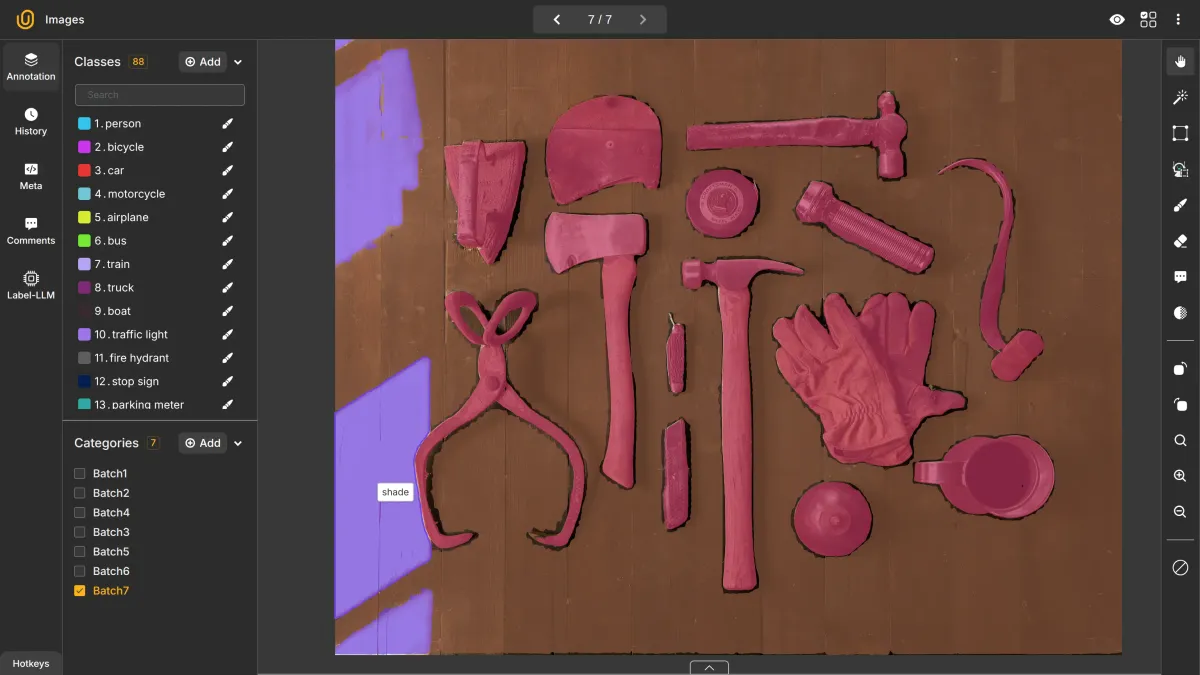
43. Brush Annotation
Brush annotation is a freeform labeling technique where annotators use a digital brush to “paint” object areas. It is often used in segmentation tasks where precision is required, but pixel-level polygon drawing is inefficient.
Brush tools are ideal for organic or irregular shapes such as tissues, clouds, or fluid boundaries:
Annotating Car Image with Polygon Brush | Unitlab Annotate
44. Dataset Format
Dataset format defines how images, labels, and metadata are stored and structured. It determines how tools read, write, and manage data.
Choosing the right format ensures compatibility with model training tools, annotation platforms, and version control systems. Common formats include JSON, XML, and CSV.
45. JSON
JSON (JavaScript Object Notation) is a lightweight, human-readable format used to store structured data. In CV, it’s widely used to represent annotations, such as bounding boxes, class labels, and confidence scores.
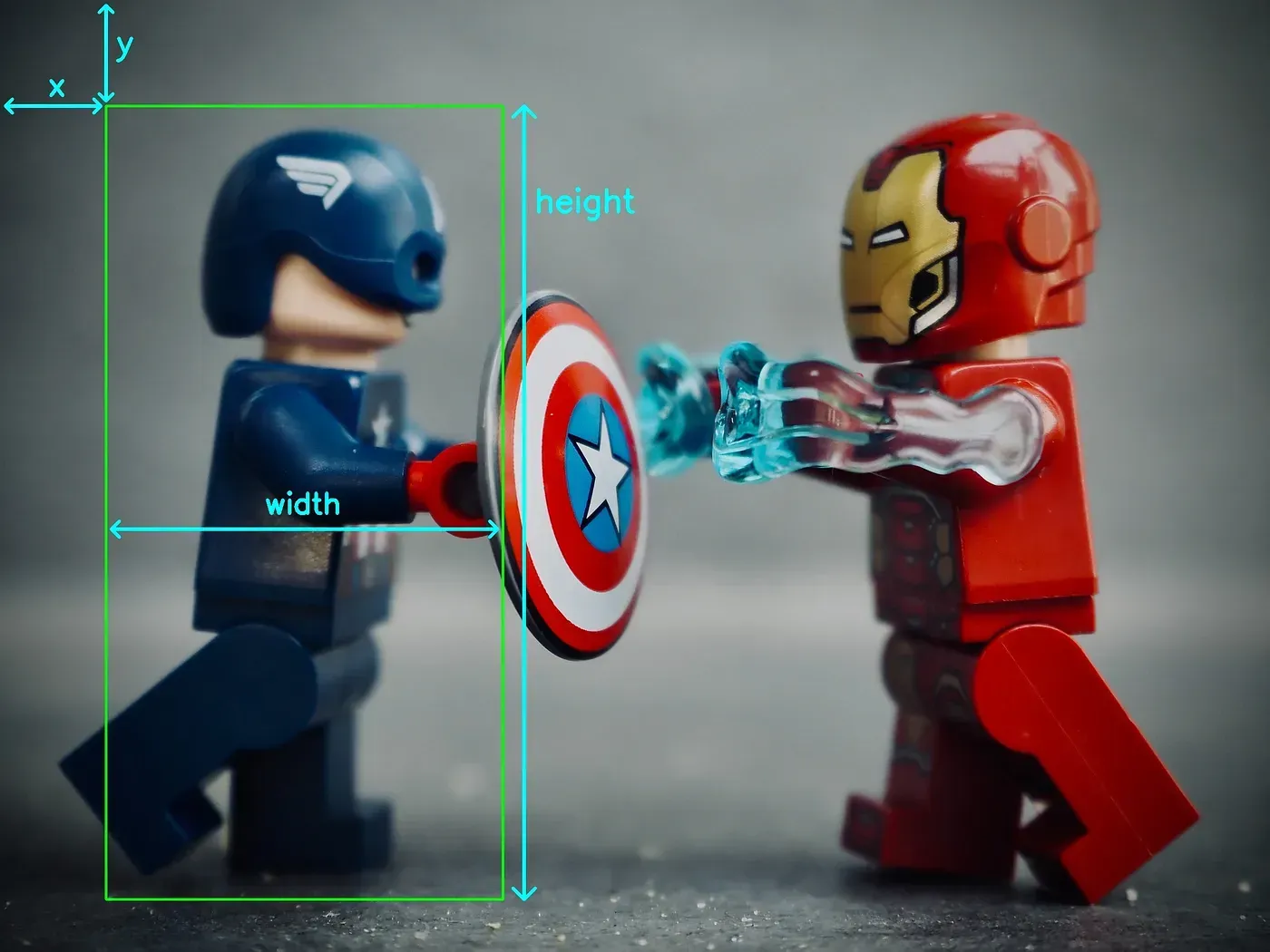
For example, for the image and bounding box above, these are the JSON coordinates:
{
'class': 'Person',
'coordinates': {
'x': 10,
'y': 10,
'width': 150,
'length': 300
},
'confidence_score': 0.93,
}46. XML
XML (eXtensible Markup Language) is a structured data format used in older or legacy systems. While more verbose than JSON, it is still widely used in datasets such as PASCAL VOC.
Understanding both XML and JSON is important for compatibility across tools and workflows in computer vision.
47. Imbalanced dataset
An imbalanced dataset contains a disproportionately high number of samples from certain classes and very few from others—e.g., 95% cats and 5% dogs.
This can lead to biased models that underperform on underrepresented classes. Solutions include resampling, class weighting, and data augmentation.
48. Occlusion
Occlusion occurs when part of an object is blocked from view—by another object, the edge of the image, or an obstruction. For example, a person standing behind a table may only be partially visible.
Models must learn to recognize partially occluded objects. The best practice during labeling is to annotate the object as if fully visible.
49. Data Augmentation
Data augmentation refers to techniques used to artificially expand a dataset by applying transformations like rotation, flipping, cropping, or lighting changes.
This improves model generalization, reduces overfitting, and helps address class imbalance when data is limited.
50. Synthetic Data
Synthetic data is artificially generated through simulations, rendering engines, or generative models like GANs. It mimics real-world data but can be produced at scale without manual collection or labeling.
Synthetic data is valuable for training in privacy-sensitive or data-scarce domains and enables rapid prototyping before gathering real samples.
Conclusion
Computer vision today goes far beyond object detection. It involves thoughtful dataset design, high-quality annotations, evaluation metrics, file formats, and practical trade-offs between speed and accuracy.
With these 50 essential terms, you now have a vocabulary that spans the full CV pipeline—from annotation tools to model performance. Whether you're a developer, annotator, researcher, or team lead, these terms will help you communicate and build with greater confidence.
Explore More
Check out these posts for more information on the topic:
- Who is a Data Annotator?
- Four Essential Aspects of Data Annotation
- A Comprehensive Guide to Image Annotation Types and Their Applications
References
- Brad Dwyer (Oct 5, 2020). Glossary of Common Computer Vision Terms. Roboflow Blog: Link
- Johannes Dienst (Jun 12, 2024). Common Terms in Computer Vision. AskUI: Link
- Nikolaj Buhl (November 11, 2022). 39 Computer Vision Terms You Should Know. Encord Blog: Link