Computer vision is one of the most exciting fields in artificial intelligence: teaching machines how to interpret images and video, recognize patterns, and make visual decisions. Like any other technical field, stepping into computer vision can feel overwhelming, especially with all the new technical terms and jargon.
While there are universally accepted terms and jargon, some are specific to certain teams, companies, or tools. For newcomers, these terms can be difficult to grasp as Elon Musk once observed while running his high-tech companies. It's unrealistic to define every term used in the field, but it is absolutely possible, and useful, to explain the essential ones so that you're confident what you're saying makes sense to others.
This post is the first in a two-part series where we explain 50 essential computer vision terms in simple, approachable language. We will start with broad ideas and moving toward more specific ones. Whether you're just beginning your journey or already working on basic models, these explanations will give you a solid understanding of the computer vision landscape.
1. AI
Artificial Intelligence (AI) is the broad concept of building machines that can perform tasks that usually require human intelligence. These tasks include understanding language, recognizing faces, learning from experience, or making decisions. AI systems use algorithms, neural networks, and statistical methods to accomplish these goals. Computer vision is one major branch within the larger field of AI.
One widely accepted definition of AI comes from John McCarthy (2004, by IBM):
It is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable.
2. Machine Learning
Machine Learning (ML) is a subset of AI focused on developing systems that can automatically improve through experience. Instead of being programmed with fixed rules, ML models learn from data and improve over time by finding patterns. ML has many subfields and techniques (such as supervised, unsupervised, deep, and reinforcement learning), but its core idea is learning from data.
In computer vision, ML powers models that learn to recognize patterns in images: for example, distinguishing between a dog and a cat, or between a cancerous and healthy cell.
3. Deep Learning
Although the terms “deep learning,” “neural networks,” and “machine learning” are often used interchangeably, they refer to different layers of the same field. Deep learning is a specialized branch of machine learning that uses deep neural networks (networks with many layers) to learn from large, complex datasets.
Deep learning is particularly well-suited for computer vision because it can automatically learn relevant visual features from raw image data, eliminating the need for hand-crafted rules. Most cutting-edge applications in computer vision today rely on deep learning.
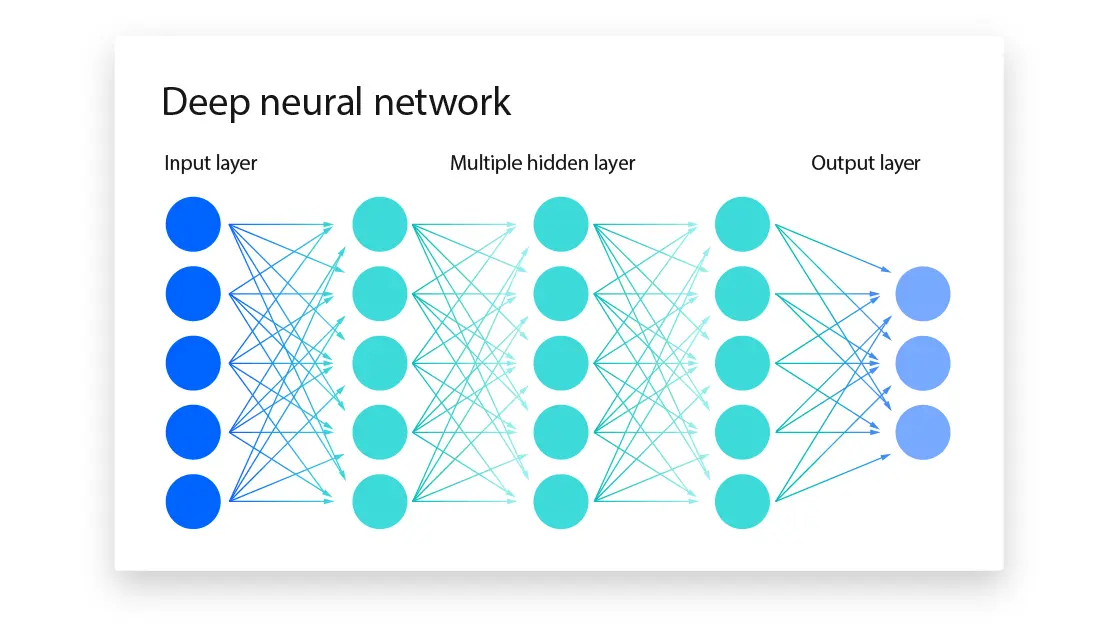
4. Neural Networks
Neural networks are the core component of deep learning. Inspired by the structure of the human brain, they consist of layers of connected nodes, or “neurons,” that pass information between each other. The input layer receives raw data, hidden layers process the data, and the output layer produces the final prediction.
A neural network becomes “deep” when it has three or more layers. Each layer learns increasingly abstract features, enabling the system to make more sophisticated decisions based on the data.
5. Computer Vision
Computer vision is the field of artificial intelligence that focuses on enabling machines to interpret and understand visual information, like photos, videos, or real-time camera feeds. It allows computers to “see” and derive meaning from the world in a way that mimics human vision.
Computer vision combines techniques from AI, ML, and image processing. Its models are typically trained on image- or video-based datasets, with applications in facial recognition, object detection, medical imaging, and beyond.
6. NLP
Natural Language Processing (NLP) is the area of AI that deals with the interaction between computers and human language. It enables machines to read, interpret, and even generate written or spoken language.
Although NLP is a separate field, it often complements computer vision in multimodal systems; for example, when AI generates captions for images or scans and extracts text from documents. NLP tools can also assist with automated data labeling in CV workflows.
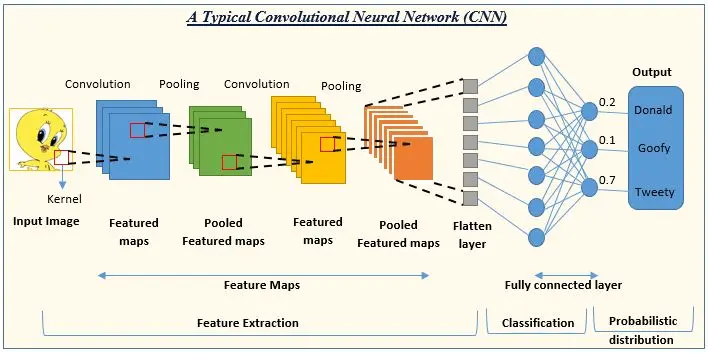
7. CNN
Convolutional Neural Networks (CNNs) are a type of deep learning model built specifically for processing images. They are the standard architecture for most computer vision tasks.
CNNs use convolutional layers to scan the input image with small filters, detecting basic features like edges and textures. These features are then combined in deeper layers to detect more complex patterns like shapes, objects, or faces. CNNs form the backbone of many classification, detection, and segmentation models.
8. Dataset
A dataset is a structured collection of data used to train and evaluate machine learning models. In computer vision, this usually means thousands—or millions—of images or videos, each paired with labels that describe their content.
The quality of a dataset heavily influences the quality of the resulting model. As the saying goes, “Garbage in, garbage out.” If the dataset is flawed, biased, or mislabeled, the model will learn the wrong patterns.
9. Data Annotation
Annotation is the process of labeling your dataset. Raw data—like unlabeled images—is not useful for training supervised models until you explain what the data represents. Data annotation can include drawing bounding boxes around objects, identifying key points on a face, or labeling whether a medical image shows a disease.
Annotations give meaning to your data, helping the model learn which patterns to associate with which labels.

10. COCO
COCO (Common Objects in Context) is a benchmark dataset widely used in computer vision research. It includes over 300,000 images, with more than 2.5 million labeled objects. What makes COCO special is that it provides images with complex, real-world scenes where multiple objects appear in various settings and positions.
COCO is used to train and evaluate models on tasks like object detection, instance segmentation, and image captioning.
11. YOLO
YOLO (You Only Look Once) is a real-time object detection algorithm. Unlike traditional models that look at different parts of the image in multiple passes, YOLO processes the entire image in one go—making it exceptionally fast.
It is widely used in applications where speed is critical, such as real-time video analysis, autonomous vehicles, or security systems.
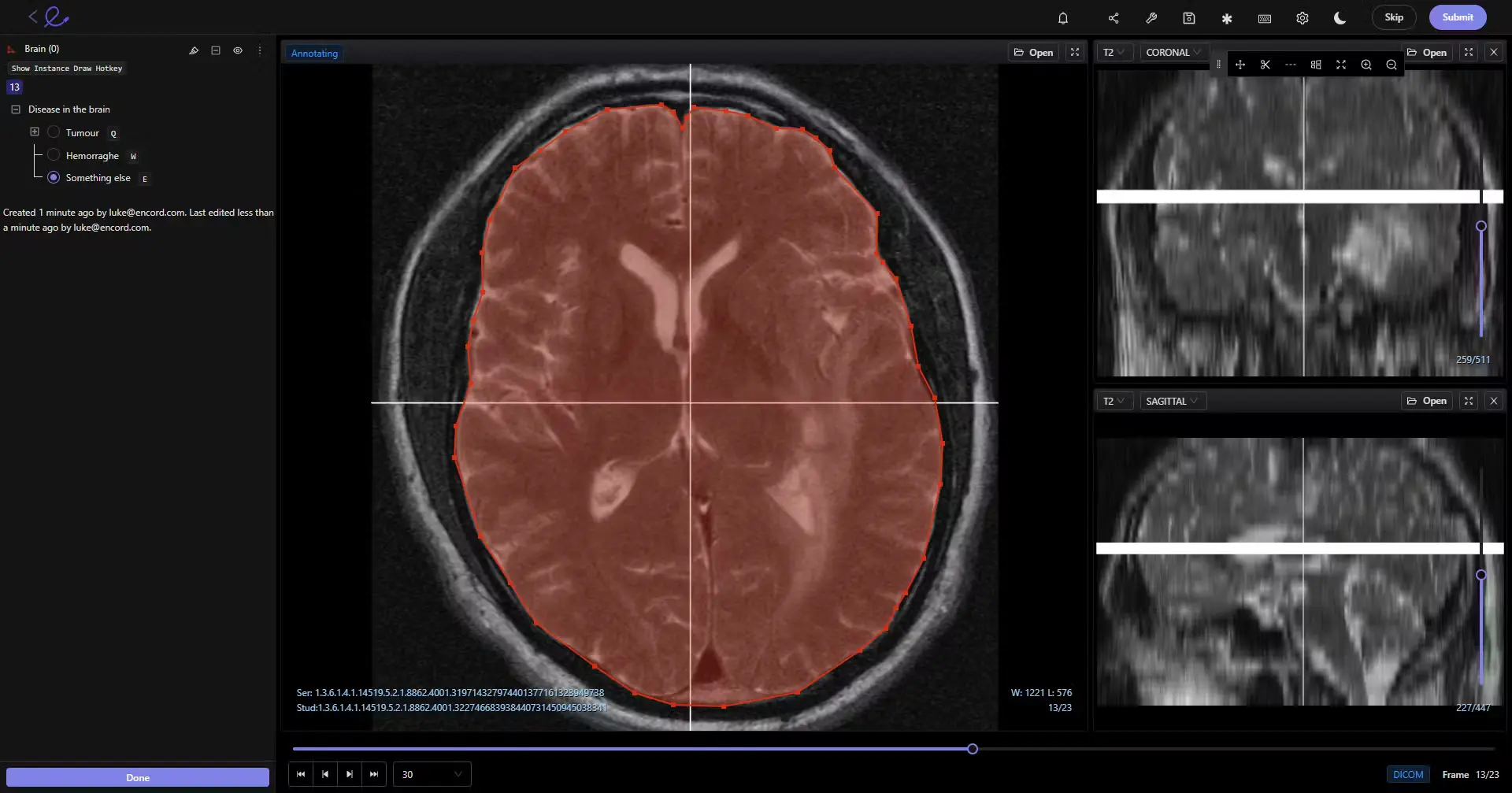
12. DICOM
DICOM (Digital Imaging and Communications in Medicine) is the standard format for storing and exchanging medical imaging data—such as MRI, CT, and ultrasound scans. It ensures compatibility between different medical systems and imaging devices.
For computer vision in healthcare, models must be able to read and process DICOM files to work with real-world clinical data.
13. NIFTI
NIFTI (Neuroimaging Informatics Technology Initiative) is another medical imaging format, commonly used for 3D brain imaging. Unlike DICOM, NIFTI includes spatial orientation information and is designed for academic and research settings, especially in neuroscience.
Many medical CV systems must handle both DICOM and NIFTI formats depending on the task and domain.
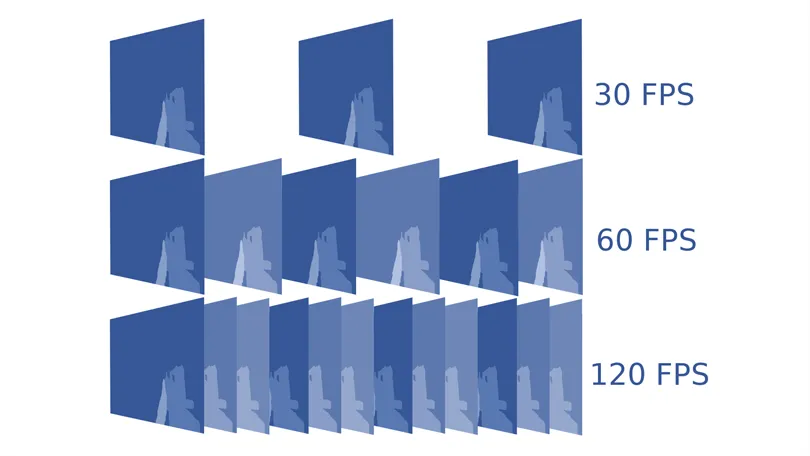
14. FPS
FPS (Frames Per Second) measures how many individual frames are processed every second. In video or real-time systems, this determines how smooth the video looks and how fast a model reacts to visual input.
A model running at 60 FPS processes 60 frames per second. Higher FPS allows faster, more accurate performance in tasks like object tracking, live gesture recognition, or drone navigation.
15. Confidence Threshold
When a model makes a prediction, it assigns a confidence score—how certain it is about the result. The confidence threshold is the minimum value needed to accept that prediction as valid.
For example, if a model detects a cat with 95% confidence and your threshold is 70%, the prediction is accepted. But if the score is 60%, it gets discarded. Adjusting the threshold balances the trade-off between false positives and missed detections.
16. F1
In model evaluation, the F1 score is a single metric that combines precision (how accurate the predictions are) and recall (how many actual positives were found). It's especially useful when working with imbalanced datasets, where one class dominates the others.
Confusion Matrix and F1 Score in Computer Vision | Unitlab Annotate
The F1 score is the harmonic mean of precision and recall and provides a more balanced view of model performance than accuracy alone.
17. IoU and Dice Loss
Both are metrics used to evaluate how well a model’s predictions match the ground truth:
- IoU (Intersection over Union): Measures how much a predicted bounding box overlaps with the actual box. A value above 0.5 is often considered acceptable.
- Dice Loss: Commonly used in segmentation tasks, especially in medical imaging. It measures how closely the predicted region matches the actual region by comparing their overlap.
18. Anchor Boxes and Non-Maximum Suppression (NMS)
These are techniques used in object detection models:
- Anchor Boxes are predefined shapes that help the model detect objects of different sizes and aspect ratios.
- Non-Maximum Suppression (NMS) removes duplicate detections for the same object by keeping the one with the highest confidence and suppressing the rest.
Together, they help models detect multiple objects in a clean and structured way.
19. Noise
Noise refers to any unwanted variation or error in an image that doesn't reflect the actual content—such as lighting problems, blur, or sensor errors.
Too much noise can confuse the model and reduce accuracy. Preprocessing steps like filtering or denoising are often used to clean the data, but models must also learn to tolerate noise in real-world environments.

20. Blur Techniques
Blurring is a technique used to reduce detail in an image. It’s useful for several purposes, including removing noise, anonymizing personal information (like faces), or simulating motion.
Two common types are:
- Gaussian Blur: Smooths sharp transitions and removes noise.
- Motion Blur: Mimics the effect of movement in an image.
Blurring is also used as a data augmentation method in training.

21. Grayscale
A grayscale image contains only shades of gray—no color. It simplifies the data and reduces computational cost while preserving structure and contrast.
Grayscale images are often used in applications where color does not provide useful information, such as OCR (Optical Character Recognition), edge detection, or medical X-ray analysis.
22. Metadata
Metadata is information about a piece of data. In images, metadata can include resolution, file size, date taken, GPS location, or even the labeling format used.
Metadata is essential for organizing datasets, performing quality checks, or automating parts of the training pipeline.
23. Framework
A framework is a set of tools and libraries that simplify the process of building, training, and deploying machine learning models.
Popular frameworks in computer vision include:
- TensorFlow and PyTorch for deep learning
- OpenCV for traditional image processing
Frameworks help reduce boilerplate code and standardize development practices.
24. GPU
A GPU (Graphics Processing Unit) is designed to perform many calculations in parallel. This makes it ideal for training deep learning models, which rely heavily on matrix operations.
Using a GPU can reduce training time from days to hours. They are critical for modern CV work, especially when working with large datasets and complex models.
25. CPU
A CPU (Central Processing Unit) is the general-purpose processor found in most computers. While it's slower than a GPU for training large models, it’s still widely used for running (or inferring from) models in production—especially in lightweight or embedded systems.
Conclusion
If you're diving into computer vision, understanding the vocabulary is half the battle. These 25 terms form a strong foundation, helping you make sense of model architectures, dataset formats, and performance metrics.
In the next part, we’ll tackle 25 more terms—including segmentation types, synthetic data, and more hands-on concepts you’ll encounter as you build and deploy real-world models.
Explore More
Check out these resources for more on computer vision:
- Computer Vision in Healthcare: Applications, Benefits, and Challenges
- Top 10 Computer Vision Blogs
- Top 11 AI Podcasts by Category
References
- Brad Dwyer (Oct 5, 2020). Glossary of Common Computer Vision Terms. Roboflow Blog: Link
- Johannes Dienst (Jun 12, 2024). Common Terms in Computer Vision. AskUI: Link
- Nikolaj Buhl (November 11, 2022). 39 Computer Vision Terms You Should Know. Encord Blog: Link